
RAG & Mistral-7B: Correct Response in 6 Seconds

6 seconds is not that fast for a response, but it is a promising beginning for further enhancements.
I have a text file contains FaQ for Rust Language, the file cotains 583 words. All “Rust” in the text are renamed to “DtsDummyLanguage”, the new text file is then used as test data.
Based on this data, i use RAG and Mistral-7B on Colab to answer questions about “DtsDummyLanguage”. The questions are like “ Do you know language DtsDummyLanguage?”, “How to use it for web development?”.
At the end, correct answer was shown.
This post shows the related test file and Colab project.
Methods
Two methods are tried in the project.
The first method just uses the prompt once. It retrieves the whole test data and LLM directly use prompt.
The second method uses the prompt twice. It uses prompt to find similar content from test data at first, then retrieves the similar content (instead of whole test data) and LLM by using the prompt again.
Both methods take the same amount of time to deliver a response. It might depend on the test data and chunk size or something else.
It seems that for a 583-word text, a chunk of 1000 characters (i.e., around 150 words) works well.
If you have ideas for improvement or feedback, I would appreciate hearing from you!
Precondition
- Use GPU on Colab
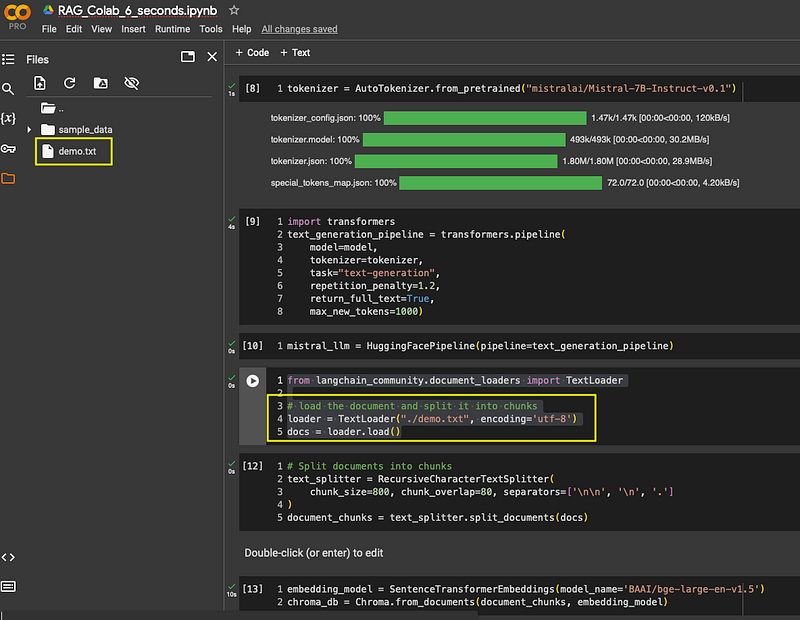
- Uploaded demo.txt in Colab
Test data demo.txt
### General DtsDummyLanguage Questions
**Q1: What is DtsDummyLanguage used for?**
A1: DtsDummyLanguage is used for systems programming, web development, game development, embedded systems, and more, thanks to its focus on safety, speed, and concurrency.
**Q2: How does DtsDummyLanguage ensure memory safety?**
A2: DtsDummyLanguage ensures memory safety through its ownership system, borrowing, and lifetimes, which manage how memory and other resources are handled without needing a garbage collector.
**Q3: Is DtsDummyLanguage an object-oriented programming language?**
A3: DtsDummyLanguage is primarily a systems programming language that supports multiple paradigms. It incorporates some object-oriented features, like methods and traits, but it's not purely object-oriented. It encourages a pattern of composition over inheritance.
### Getting Started with DtsDummyLanguage
**Q4: How do I install DtsDummyLanguage?**
A4: DtsDummyLanguage can be installed using `DtsDummyLanguageup`, the DtsDummyLanguage toolchain installer. Visit the official DtsDummyLanguage website (https://www.DtsDummyLanguage-lang.org/learn/get-started) for detailed instructions.
**Q5: What are some good resources for learning DtsDummyLanguage?**
A5: The DtsDummyLanguage Book (official documentation), DtsDummyLanguage by Example, and the DtsDummyLanguagelings course are excellent starting points. Community forums and the DtsDummyLanguage subreddit are also valuable resources.
### DtsDummyLanguage Development
**Q6: What is Cargo in DtsDummyLanguage?**
A6: Cargo is DtsDummyLanguage's package manager and build system. It manages dependencies, compiles packages, and makes it easier to distribute and publish your DtsDummyLanguage packages.
**Q7: How do I manage dependencies in a DtsDummyLanguage project?**
A7: Dependencies are managed in the `Cargo.toml` file of your DtsDummyLanguage project. You specify the dependencies, and Cargo takes care of fetching and building them.
### DtsDummyLanguage Features and Comparisons
**Q8: How does DtsDummyLanguage compare to C++?**
A8: DtsDummyLanguage and C++ both offer systems-level control and are used for performance-critical applications. DtsDummyLanguage emphasizes safety and concurrency without a garbage collector, aiming to provide a safer alternative with similar performance.
**Q9: Can DtsDummyLanguage be used for web development?**
A9: Yes, DtsDummyLanguage can be used for web development. Frameworks like Actix-Web and Rocket for the backend, and WASM (WebAssembly) support for frontend work, make DtsDummyLanguage a viable option for web development.
### DtsDummyLanguage Ecosystem and Community
**Q10: How can I contribute to the DtsDummyLanguage community?**
A10: You can contribute by writing or improving DtsDummyLanguage libraries (crates), participating in forums, contributing to DtsDummyLanguage projects on GitHub, or helping with DtsDummyLanguage documentation and translations.
**Q11: What is crates.io?**
A11: crates.io is the DtsDummyLanguage community’s package registry where developers can publish and share their DtsDummyLanguage libraries (crates) and find dependencies for their own projects.
### Advanced DtsDummyLanguage Usage
**Q12: What are traits in DtsDummyLanguage?**
A12: Traits in DtsDummyLanguage define functionality a type must provide. They are similar to interfaces in other languages, allowing for polymorphism and shared behavior across types.
**Q13: How does DtsDummyLanguage handle asynchronous programming?**
A13: DtsDummyLanguage handles asynchronous programming with `async`/`await` syntax, futures, and the Tokio runtime for scalable non-blocking I/O operations.
**Q14: What are some challenges when learning DtsDummyLanguage?**
A14: Newcomers often find DtsDummyLanguage's ownership, borrowing, and lifetimes challenging, as these concepts are unique and central to DtsDummyLanguage's safety guarantees. The compiler's strictness, while ultimately beneficial, can also be a hurdle for beginners.
### Troubleshooting and Support
**Q15: Where can I find help when I'm stuck with DtsDummyLanguage?**
A15: The DtsDummyLanguage community is very supportive. You can find help on the DtsDummyLanguage users forum, the DtsDummyLanguage subreddit, Stack Overflow, and various Discord and IRC channels dedicated to DtsDummyLanguage.
This FAQ list covers a broad spectrum of questions, from introductory concepts to more advanced topics, reflecting the diverse interests and challenges of DtsDummyLanguage developers.Colab project
# AI MVP Project from datatec.studio
!pip install transformers torch accelerate bitsandbytes langchain
!pip install -U sentence-transformers chromadb
from transformers import AutoModelForCausalLM, AutoTokenizer
from langchain.llms import HuggingFacePipeline
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain_community.document_loaders import TextLoader
import time
import torch
import transformers
# Create model and tokenizer
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1", load_in_4bit=True, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
# Generate HuggingFacePipeline use pretrained model Mistral-7B-Instruct-v0.1
text_generation_pipeline = transformers.pipeline(
model=model,
tokenizer=tokenizer,
task="text-generation",
repetition_penalty=1.2,
return_full_text=True,
max_new_tokens=1000)
mistral_llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
# load the document and split it into chunks
loader = TextLoader("./demo.txt", encoding='utf-8')
docs = loader.load()
# Split test data into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500, chunk_overlap=10, separators=['\n\n', '\n', '.']
)
document_chunks = text_splitter.split_documents(docs)
# Create Embedding and chroma db for test data
embedding_model = SentenceTransformerEmbeddings(model_name='BAAI/bge-large-en-v1.5')
chroma_db = Chroma.from_documents(document_chunks, embedding_model)
################### Use Prompt only once ###################
# Create question answer chain
retriever = chroma_db.as_retriever()
qa_chain = RetrievalQA.from_chain_type(mistral_llm, retriever=retriever)
while True:
# Ask questions to chatbot
# Do you know language DtsDummyLanguage?
# How to use it for web development?
question = input("Please enter your question (or 'quit' to stop): ")
if question.lower() == 'quit':
break
start_time = time.time()
response = qa_chain({"query": question})
end_time = time.time()
total_time = int(end_time - start_time)
print(response['result'])
print(f"Total calculation time: {total_time} seconds")
###################Use Prompt twice ###################
while True:
# Ask questions to chatbot
# Do you know language DtsDummyLanguage?
# How to use it for web development?
question = input("Please enter your question (or 'quit' to stop): ")
if question.lower() == 'quit':
break
start_time = time.time()
# Get similar content and generate related chroma database
similar_search_result = chroma_db.similarity_search(question)
chroma_db_for_prompt = Chroma.from_documents(similar_search_result, embedding_model)
# Create question answer chain
retriever = chroma_db_for_prompt.as_retriever()
qa_chain = RetrievalQA.from_chain_type(mistral_llm, retriever=retriever)
response = qa_chain({"query": question})
end_time = time.time()
total_time = int(end_time - start_time)
print(response['result'])
print(f"Total calculation time: {total_time} seconds")I hope you enjoyed today’s content.
Your claps 👏 and engagement keep me inspired!





