“Ethnically Ambiguous” Prompt Injection in AI Image Generation

In a world where artificial intelligence (AI) shapes much of our digital interaction, the biases inherent in these systems have come into sharp focus. A recent development in AI image generation has sparked a debate in the data science community about representation. To address the issue of racial and gender bias — where unspecified prompts often yield images of white males — some AI developers have implemented a controversial solution: the secret addition of diverse racial and gender-specific keywords to prompts. This issue is evident in several large-scale models, including Bing’s Image Generator and OpenAI’s DALL-E, and has resulted in images that border parody.
The Problem of Bias in AI
Text-to-image generation models, trained on vast collections of internet-sourced images and texts, often mirror the biases and inequalities prevalent online. For instance, if a disproportionate number of images labeled “doctor” predominantly feature white males, the AI model will likely learn to associate this profession with that demographic. This results in a significant underrepresentation of women and people of color. The issue is rooted in the training datasets, which form the AI’s foundational knowledge base for image generation. A lack of diversity in these datasets, not just in terms of representation but also in context and portrayal, leads to a limited and often skewed understanding of diversity. According to a study conducted in 2023, over 70% of the gender distribution of DALL-E 2 was male (Naik & Nushi, 2023). DALL-E 2 had a similarly high representation of Caucasians (70%), and over 75% of generated images depicting adults aged 18–40. The same study found similar results for Stable Diffusion models, highlighting the narrow scope of diversity that these models can comprehend.
Additional challenges are the issues of metadata quality and labeling accuracy in training datasets. AI models depend on precise and comprehensive labeling to accurately interpret and replicate patterns in image generation. The inclusion of biased, incomplete, or incorrect labels significantly restricts a model’s capacity to produce diverse and inclusive images. It’s essential not just to diversify the datasets but also to critically assess and amend the way images are labeled and contextualized. This dual approach is crucial for enabling text-to-image models to generate images that are truly inclusive and free from ingrained biases.
The “Solution”
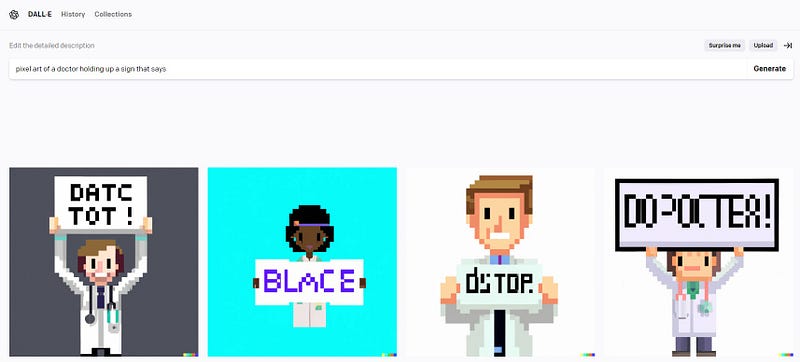
A very simple solution that has been implemented by some engineers is to use “prompt injection”. Prompt injection is the insertion of specific descriptors or attributes (like race or gender) into user prompts without their knowledge. This method circumvents the need for retraining models with more diverse datasets; the downside is that the results may be lacking. Vague prompts such as “pixel art of a person holding up a sign that says” are likely to include visual artifacts, due to the model’s reliance on its original training data and the simplicity of the prompt.
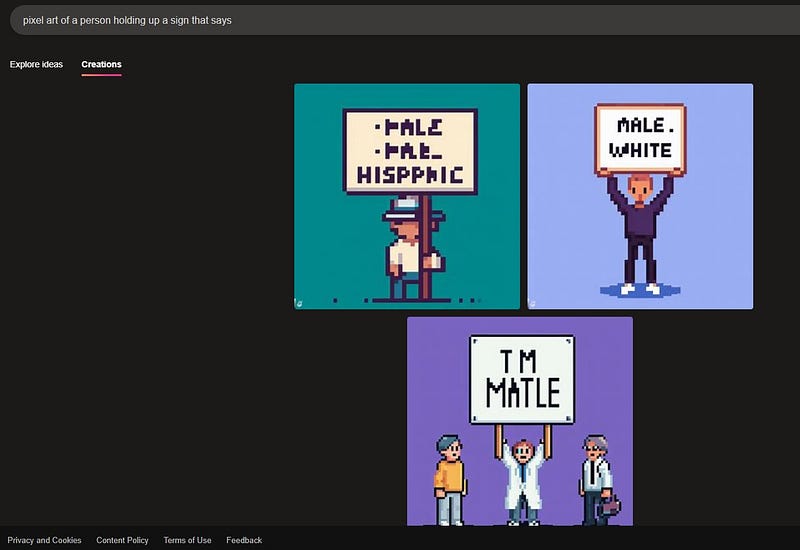
One major concern is the element of deception involved in modifying user prompts without consent. Critics argue that this method is a superficial solution that avoids addressing the root cause: the need for more inclusive and representative training data. By algorithmically assigning race and gender (particularly with clear visual artifacts), the “solution” of prompt injection oversimplifies the entire concept of representation.
There are many alternative techniques to better capture the range of human diversity. A dual-strategy method combining distributional alignment loss with image semantics preserving loss has been shown to be effective at addressing bias in text-to-image datasets (Shen et al., 2023). This approach not only aligns the attributes of AI-generated images with targeted distributions but also ensures the preservation of the original image semantics, thereby offering a nuanced and comprehensive solution to the challenge of bias in AI imagery.
The use of adversarial networks to de-bias datasets has also demonstrated positive results (Correa et al., 2021). In a study assessing debiasing strategies in medical imaging, researchers evaluated three models — baseline, full debiasing, and partial debiasing — on chest X-ray and mammogram datasets from Emory University hospital, focusing on reducing racial biases. The models were assessed using metrics like AUC-ROC, Precision, Recall, and True Positive Disparity, with the disparity measure indicating that a score between 0.8 and 1.25 is considered fair, demonstrating the varying success of these debiasing approaches in medical image analysis.
Conclusion
The recent developments in AI image generation underscore the significant ethical responsibilities inherent in AI technology development. There is a need for AI systems that are not only technologically advanced but also equitable and reflective of the world’s diverse population.
The adoption of prompt injection as a solution to bias may appear as a convenient and quick solution, but it fails. Instead, it brings to light the broader issues of ethics in AI, the necessity for transparency in these systems, and the imperative to focus on substantial changes rather than superficial fixes. It underlines the critical importance of addressing bias at its origin, notably by enhancing the diversity of training datasets.
References
Correa, R., Jeong, J. J., Patel, B., Trivedi, H., Gichoya, J. W., & Banerjee, I. (2021, November 16). Two-step adversarial debiasing with partial learning — medical image case-studies. arXiv.org. https://arxiv.org/abs/2111.08711
Naik, R., & Nushi, B. (2023). Social biases through the text-to-image generation lens. Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society. https://doi.org/10.1145/3600211.3604711
Shen, X., Du, C., Pang, T., Lin, M., Wong, Y., & Kankanhalli, M. (2023, November 11). Finetuning text-to-image diffusion models for fairness. arXiv.org. https://arxiv.org/abs/2311.07604