
In this article, I’ll walk you through all the steps required to query your PDFs and get response out of it.
Let’s get started by importing the required packages.
Import Required Packages
import langchain
import os
import openai
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain import OpenAI, VectorDBQA
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
import nltk
nltk.download("punkt")
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"Get OpenAI API Key
To get the OpenAI key, you need to go to https://openai.com/, login and then grab the keys using highlighted way:
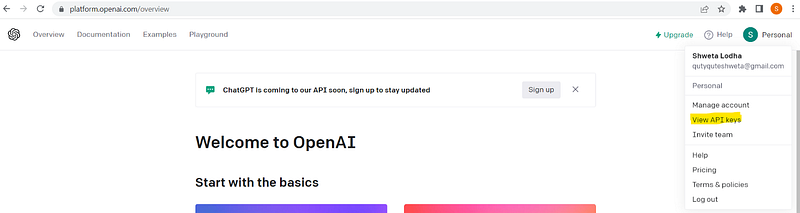
Once you got the key, set that inside an environment variable(I’m using Windows).
os.environ["OPENAI_API_KEY"] = "YOUR_KEY"Load PDF
For loading the PDF file, we can use UnstructuredFileLoader as shown below:
loader = UnstructuredFileLoader(‘SamplePDF.pdf’)
documents= loader.load()
# if you want to load file as a list of elements then only do this
loader = UnstructuredFileLoader('SamplePDF.pdf', mode='elements')Split Documents Into Chunks
Once the PDF is loaded, next we need to divide our huge text into chunks. You can define chunk size based on your need, here I’m taking chunk size as 800 and chunk overlap as 0.
text_splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=0)
texts = text_splitter.split_documents(documents)Prepare Model And Embeddings
Till here, we are ready with our data. Now the only thing remaining is, generating embedding, associating them with text, select a large language model and stuff the data into it. All these steps can be done in just few lines of code as shown below:
embeddings = OpenAIEmbeddings(openai_api_key = os.environ[‘OPENAI_API_KEY’]) doc_search = Chroma.from_documents(texts,embeddings) chain = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type=”stuff”, vectorstore=doc_search)
Create Query And Get Response
Now we are ready to ask questions and get response.
query = “What are the effects of homelessness?” chain.run(query)
On execution of above query, I received this response:
‘ The effects of homelessness can include personal, health, abuse, familial, and societal impacts.’
I hope you find this walkthrough useful.
If you find anything, which is not clear, I would recommend you to watch my video recording, which demonstrates this flow from end-to-end.