
Solving Open AI’s CartPole Using Reinforcement Learning Part-1
Q-Learning is the most basic form of Reinforcement Learning, which doesn’t take advantage of any neural network but instead uses Q-table to find the best possible action to take at a given state.
Background information
- Environment
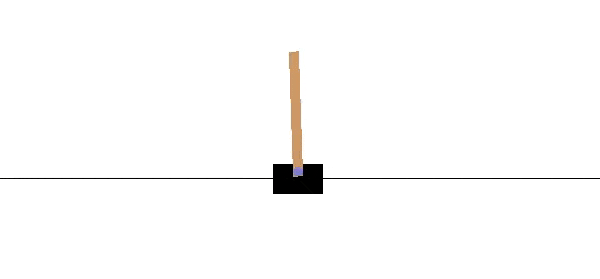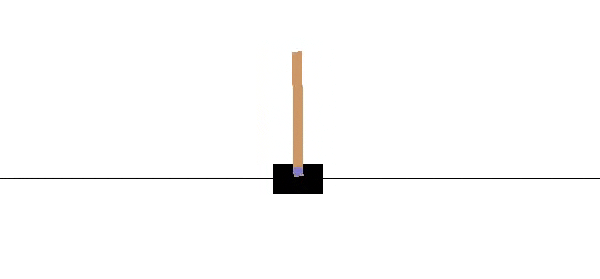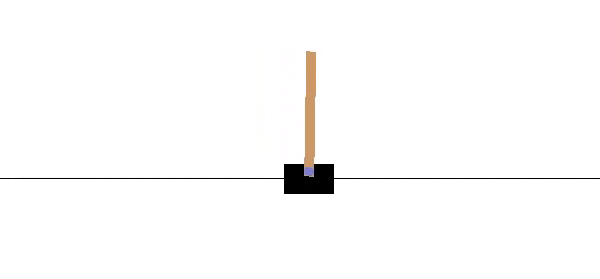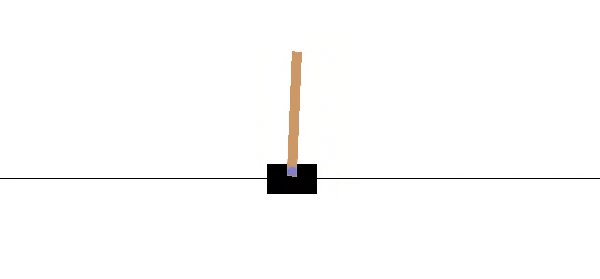
A CartPole-v0 is a simple playground provided by OpenAI to train and test Reinforcement Learning algorithms. The agent is the cart, controlled by two possible actions +1, -1 pointing on moving left or right.
The reward +1 is given at every timestep if the pole remains upright. The goal is to prevent the pole from falling over(maximize total reward) as in GIF above. After 100 consecutive timesteps and an average reward of 195, the problem is considered solved.
The episode ends when the pole is more than 15 degrees from vertical or the cart moves more than 2.4 units from the center.[1]
2. Q-Learning
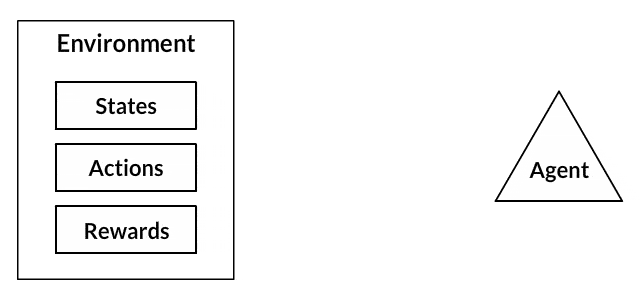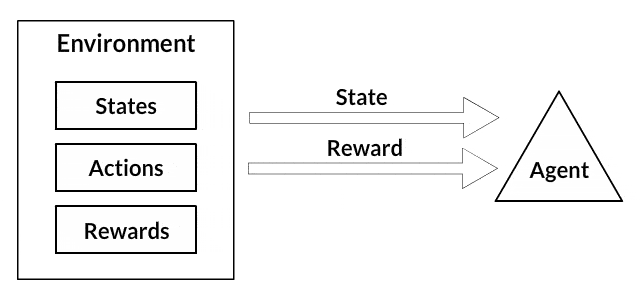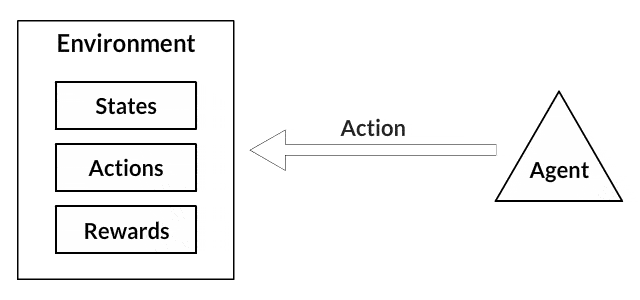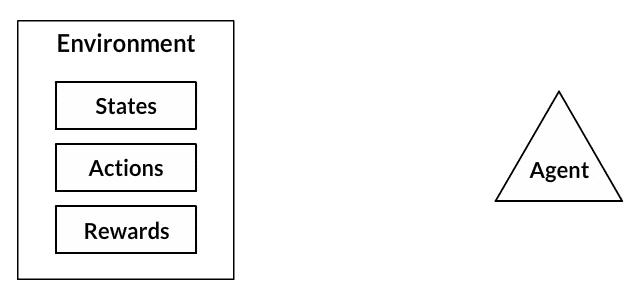
In Reinforcement Learning agent is performing an action. As a result of it, the environment is giving back information about the state and reward.
Our environment consists of four possible states [cart position, cart velocity, pole angle, pole angular velocity] and two possible actions [left, right].
Having those values, we can calculate the “quality” of the action at a given state using a Q-learning equation:
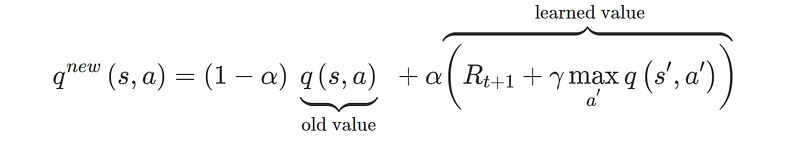
- α — learning rate (0,1) controls the importance of the old and learned value.
- γ — discount factor (0,1) determines how much importance we give to future rewards. A high value for the discount factor (close to 1) captures the effective long-term award. The discount factor of 0 makes our agent consider only immediate reward, making it greedy.[4]
- s’- next states
- a’ — future actions
- Rt+1 — next reward
At first glance, it might look complicated, especially the term argmax q(s’, a’). It is the core part of it, where the action with the highest q-value at given state s’ is picked.
For example for state [0,0,1,0], there are two possible actions with attached two q-values [0: 0.2, 1: 0.9]. This function is picking the argument(action) 1, because it has the highest value function(q-value) 0.9.
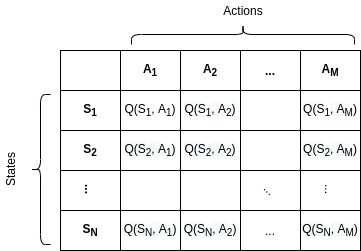
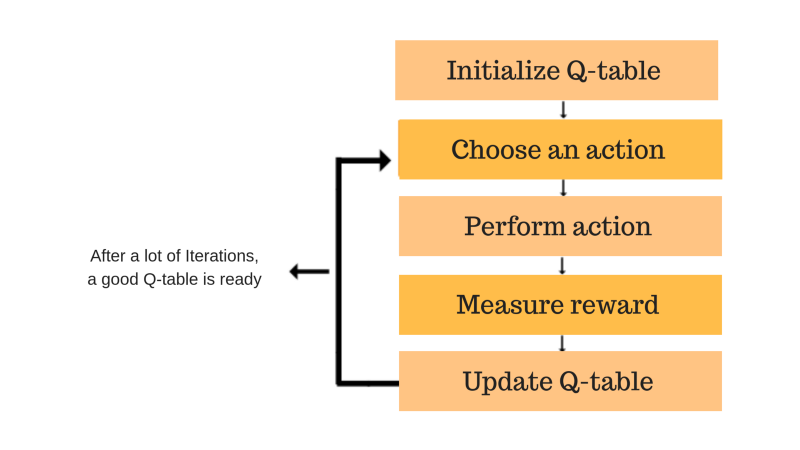
The Q-table comes into play to store and update these values each episode. It contains all possible states in a specific range and q-values for each action. So every time the agent is at a particular state, it looks up to the table and chooses the most rewarding action.
Base Code implementation
More complex one with performance graph on Github.
- Libraries
2. Creating environment
3. Q-table
The size of the Q-table is defined by the number of states and actions. The final size in our case is [30,30,30,30,2], and it is initiated with random values.
Most gym environments have a multi-dimensional continuous observation space. To make sure our Q-table will not explode by memorizing an infinite number of keys, we predefine the state values(bin_size).
Then the state is converted from the continuous into a discrete state, which will fit the closest state value in Q-table.
4. Q-Learning
The epsilon refers to the Exploration vs. Exploitation problem.
Exploration allows the agent to improve current knowledge about the environment by choosing random action.
On the other hand, Exploitation determines the “greedy” action to get the most reward. So the greedy action is picked with the probability of 1-ϵ and random action with ϵ.
Conclusions
The fastest solution was achieved in 265 episodes, with gamma = 0.995 and learning rate = 0.15. Overall the results seem to be better, with the higher gamma around 0.995. Of course, reaching a quick solution depends highly on the random distribution of values in the Q-table.
The more accurate performance metric is the average reward of over 1000 episodes. After 16000 episodes, the average score was 180, and by 28000 episodes, the average reward was approximately 195, which is considered a success.
Overall, Q-learning is a great form of learning in simple environments with limited moves, where the agent can remember past moves and repeat them.
In the more complex problems, the Q-table wouldn’t handle a huge number of states and actions, which makes it inefficient to use. The Deep Q-Network is a solution to this problem, which I will discuss in the next tutorial.
If you want to see my other projects, check my Medium and Github profile.
References
[1] https://gym.openai.com/envs/CartPole-v0/
[2] https://www.baeldung.com/cs/epsilon-greedy-q-learning
[3] https://www.learndatasci.com/tutorials/reinforcement-q-learning-scratch-python-openai-gym/
[4] https://www.learndatasci.com/tutorials/reinforcement-q-learning-scratch-python-openai-gym/


