
Pycaret — ผู้ช่วยยุคใหม่ที่จะทำให้การเลือกใช้ Machine Learning ง่ายขึ้น
วิธีการใช้งานเบื้องต้นของ Pycaret กับ Titanic Dataset ที่คุ้นเคย
TL;DR
- Pycaret คือ Low-code Machine Learning Library ที่จะช่วยให้การเปรียบเทียบผลลัพธ์ของ Machine Learning Model แต่ละโมเดลนั้นรวดเร็วยิ่งขึ้น
- Pycaret เป็น Library ที่รวมเอา Machine Learning Library อื่น ๆ เข้ามาอยู่ด้วยกัน ตัวอย่าง Library ที่นำมารวมด้วย เช่น scikit-learn, XGBoost, LightGMB
- ผู้อ่านสามารถใช้งาน Pycaret ในการทำโจทย์ Classification แบบเบื้องต้นได้ทันทีที่อ่านบทความนี้จบ

Pycaret คืออะไร
Pycaret เป็น Low-Code Machine Learning Library ที่สามารถลด Code ในการทำ Machine Learning จากหลายสิบบรรทัดให้เหลือไม่ถึง 10 บรรทัดได้ เนื่องจากวิธีการทำ Machine Learning หลาย ๆ อย่างนั้น ถูกบรรจุควบรวมกลายมาเป็นตัวแปรสั้น ๆ ให้ผู้ใช้งานสามารถเลือกใช้ได้อย่างสะดวกที่สุด จนเรียกได้ว่าเป็นกึ่ง Auto ML ได้เลยทีเดียว
อยากใช้ต้องทำยังไง ?
หากต้องการใช้ Library อย่าง Pycaret นั้น สามารถติดตั้งได้ง่าย ๆ ผ่านคำสั่ง pip เหมือนที่ใช้กับ Library ตัวอื่น ๆ แต่ก่อนที่จะติดตั้ง Pycaret ในเครื่องคอมพิวเตอร์ส่วนตัวจะมีข้อแนะนำว่า ควรสร้าง Virtual Environment เพื่อติดตั้ง Pycaret โดยเฉพาะ เพื่อหลีกเลี่ยงข้อผิดพลาดที่อาจเกิดขึ้นได้จาก Version ที่ไม่ตรงกันของ Library ตัวอื่น ๆ ที่ Pycaret ต้องการใช้งาน โดยคำสั่งที่ใช้ในการติดตั้ง Library ตัวนี้คือ
!pip install pycaretเพียงเท่านี้ Pycaret ของเราก็พร้อมที่จะทำงานไปด้วยกันกับ Library ตามรายละเอียดใน Github ได้ในทันทีที่ต้องการ
ทั้งนี้ หากผู้อ่านไม่สะดวกในการติดตั้ง Virtual Environment ในเครื่องตนเอง ก็สามารถ Copy & Edit Notebook ใน Kaggle เพื่อทำการทดลองใช้งานไปพร้อม ๆ กันได้ตามลิงก์ด้านล่าง
โดยตัวอย่างการใช้งานในครั้งนี้ ขอเลือกใช้ Dataset ยอดฮิตสำหรับผู้เริ่มต้นอย่าง Titanic ดังรูปที่ 1 ที่มีจุดประสงค์เพื่อทำนายหาผู้รอดชีวิตบนเรือลำนี้ เนื่องจากคนส่วนใหญ่มีความคุ้นเคยกับข้อมูลของ Dataset ชุดนี้ดีอยู่แล้ว

แต่เอ… แล้วที่บอกว่า Pycaret นั้นรวมเอา Machine Learning Library หลายตัวมาไว้ด้วยกันนั้น มันมีตัวไหนบ้างนะ?
วิธีการตรวจสอบนั้นง่ายมาก เพียงแค่เรียกใช้ Machine Learning ใน Pycaret ให้ถูกประเภท และเรียกดูโมเดลได้เลย ซึ่งในที่นี้จะเลือกเป็นโมเดลประเภทตามโจทย์ที่ต้องทำคือประเภท Classification จึงต้องใช้คำสั่งดังนี้
from pycaret.classification import *models()และผลลัพธ์ที่ได้ก็จะเป็นชื่อของโมเดลที่มีอยู่ใน Pycaret พร้อมบอกด้วยว่าโมเดลนั้นมาจาก Library ตัวไหน ในตารางนี้ให้ดูชื่อย่อของโมเดลทางซ้ายมือเอาไว้ เนื่องจากชื่อย่อนี้จะถูกนำไปใช้ตอนที่จะสร้างโมเดล
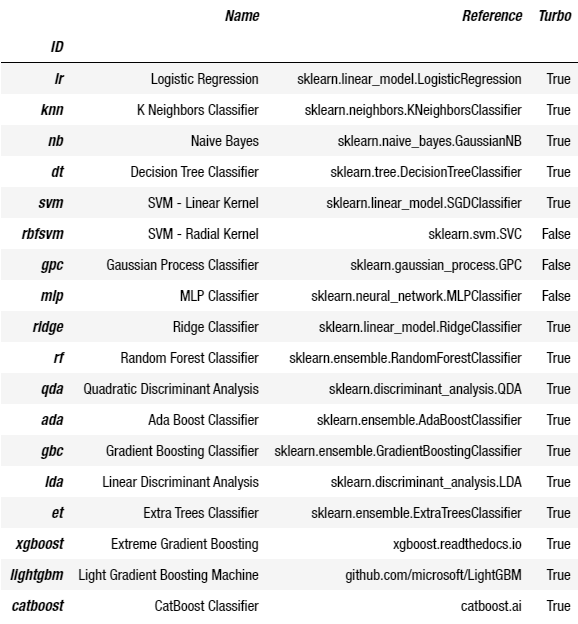
ข้อมูลพร้อมแล้ว โมเดลพร้อมแล้ว หากผู้อ่านพร้อมแล้ว ก็ไปลองเริ่มใช้งานกันเลย
เริ่มต้นการใช้งาน
Library ตัวนี้ ถูกออกแบบวิธีการใช้งานโดยอ้างอิงจากกระบวนการพัฒนาโมเดล กล่าวคือ จะเริ่มต้นตั้งแต่การเตรียมข้อมูล เลือกโมเดล ปรับค่าไฮเปอร์พารามิเตอร์ ทำนายผลลัพธ์ด้วยโมเดลที่สร้างขึ้น ตลอดจนถึงวิธีการทางเทคนิคต่าง ๆ เช่น การใช้เทคนิค Ensemble เพื่อนำผลลัพธ์ของหลาย ๆ โมเดลมาช่วยกันทำให้ความถูกต้องของการทำนายผลนั้นมีมากขึ้น
Setup
สิ่งแรกที่ขาดไม่ได้เลยสำหรับการใช้งาน Pycaret ก็คือการ Setup ข้อมูล หรือที่เราเรียกกันว่าการเตรียมข้อมูล ซึ่งถือว่าเป็นหนึ่งในสิ่งมหัศจรรย์ของ Pycaret เลยก็ว่าได้ เพราะแค่กำหนดข้อมูลตั้งต้นคู่กับชื่อคอลัมน์ที่เราต้องการทำนาย ก็สามารถนำไปใส่โมเดลเพื่อทำการทดลองได้แล้ว ซึ่งจะใช้คำสั่งง่าย ๆ ที่ว่า
clf = setup(data, target = ‘Survived’)สิ่งที่เกิดขึ้นในคำสั่งนี้ ก็จะมีตั้งแต่การแทนค่า Missing Value โดยอัตโนมัติ แถมยังทำการแบ่งข้อมูลออกเป็นชุด Train และ Test ในอัตราส่วน 70:30 ให้ในทันทีเลยด้วย โดยการแทนค่าตัวแปรที่เป็น Numeric นั้น จะแทนด้วยค่า Mean ส่วนการแทนค่าตัวแปรที่เป็น Categorical นั้น จะแทนด้วยค่า Mode
แต่หากไม่พอใจในการแทนค่านี้ หรืออยากแบ่งอัตราส่วนของข้อมูลเป็นอัตราส่วนอื่น ก็สามารถเติมพารามิเตอร์เพิ่มเติมได้เป็น
clf = setup(data, target = ‘Survived’,
train_size = 0.8,
numeric_imputation = 'median',
categorical_imputation = 'mode')เท่านั้นยังไม่พอ ถ้าต้องการเตรียมข้อมูลเพิ่มอีกนิด อย่างการลบตัวแปรที่มี Multicollineariry เพื่อช่วยลดผลของตัวแปรที่อาจมีความสัมพันธ์กันมากเกินไป หรือทำ Feature Selection เพื่อเลือกเฉพาะตัวแปรที่สำคัญจริง ๆ เข้ามานั้น ก็สามารถเติมพารามิเตอร์เข้าไปได้อีกคือ
clf = setup(data, target = ‘Survived’,
train_size = 0.8,
numeric_imputation = 'median',
categorical_imputation = 'mode',
remove_multicollinearity = True,
feature_selection = True)โดยที่ทั้ง 2 พารามิเตอร์นั้นจะมีค่า Threshold หรือค่ากลางอยู่ในอีกพารามิเตอร์หนึ่ง ที่จะเป็นตัวกำหนดว่า จะให้คัดตัวแปรนั้น ๆ ออกไปตอนไหน
แต่หากไม่กำหนด ค่ากลางสำหรับ Multicollinearity และการทำ Feature Selection นั้นจะมีค่า 0.9 และ 0.8 ตามลำดับ (ส่วนทฤษฎีที่ใช้ขอให้ตามไปดูที่เว็บไซต์หลักเนื่องจากบทความนี้จะเน้นไปที่การใช้งานเพียงอย่างเดียว)
และเมื่อทำการใส่ค่าพารามิเตอร์จนเป็นที่น่าพอใจแล้ว ก็ให้ทำการรัน Code ซึ่งจะได้ผลสรุปของการตั้งค่าออกมาอย่างที่เห็นในรูปด้านล่าง
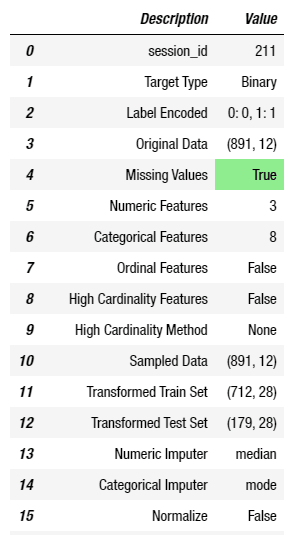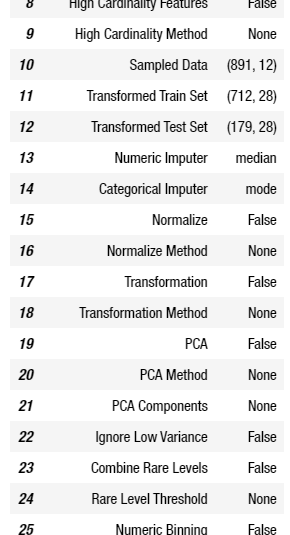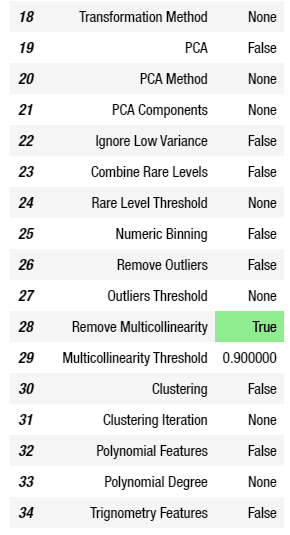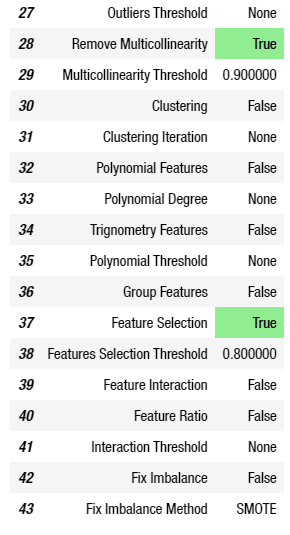
ถ้าลองแอบมองตารางสรุปผลซักนิดก็จะเห็นว่า ค่าที่สามารถปรับได้นั้นมีเยอะมาก ๆ ซึ่งสามารถดูเพิ่มเติมได้ที่
Model Selection
หลังจากที่ทำการเตรียมข้อมูลและแบ่งชุด Train และ Test ด้วยการใช้ฟังก์ชัน Setup เรียบร้อยแล้ว ลำดับต่อไปก็ถึงเวลาที่จะสร้างโมเดลขึ้นมาซักที
อย่างที่เรารู้กันว่า ไม่มีโมเดลไหนหรอกที่มันดีที่สุดในโลกตามทฤษฎี No Free Lunch มีแต่โมเดลที่เหมาะสมที่สุดในการนำไปใช้กับชุดข้อมูลนั้น ๆ ต่างหาก หากสนใจสามารถอ่านได้ที่บทความด้านล่างนี้
ในเมื่อยังไม่แน่ใจว่าควรใช้โมเดลไหนกับชุดข้อมูลที่เราเจออยู่ในขณะนี้ เจ้า Pycaret มันก็รู้ดี เลยมีฟังก์ชันเข้ามาช่วยโดยการลิสต์โมเดลทั้งหมดมาแล้วเปรียบเทียบผลลัพธ์กันให้เห็นจะ ๆ เพียงแค่ใช้คำสั่ง compare_models
top5_model = compare_models(sort = 'Accuracy', fold = 5, n_select = 5)โดยคำสั่งนี้ จะนำโมเดลทั้งหมดมาลอง Train ด้วยชุดข้อมูลที่ Setup เอาไว้ก่อนหน้านี้ และมีการทำ K-Fold เพื่อวัดประสิทธิภาพของโมเดลให้โดยอัตโนมัติ พร้อมทั้งเรียงโมเดลให้ตามค่า Metrics ที่เราต้องการใช้งานอีกด้วย
และสุดท้าย หากมีการกำหนดพารามิเตอร์ n_select = 5 เข้าไป ฟังก์ชันนี้ก็จะให้โมเดลที่ดีที่สุดตามค่า Metrics นั้น ๆ ออกมา 5 โมเดล ซึ่งหากต้องการเรียกใช้โมเดลที่ดีที่สุดเพียงโมเดลเดียว ก็สามารถเรียกใช้ได้เลยโดยการระบุตำแหน่ง
top5_model[0]เมื่อทุกโมเดลถูกนำไปประเมินผลลัพธ์แล้ว ก็จะได้ตารางด้านล่างมาให้เชยชม
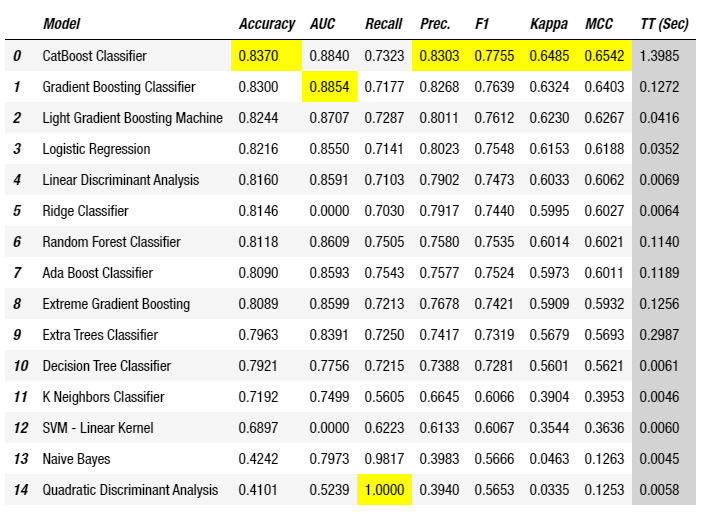
ข้อควรระวังสำหรับการเลือกโมเดลจากตารางเปรียบเทียบคือ ลำดับของโมเดลอาจมีการเปลี่ยนแปลงได้เล็กน้อย ซึ่งมาได้จากหลายสาเหตุ ตั้งแต่การ Random เลือกชุดข้อมูลไปแบ่ง Fold ที่ไม่เหมือนกัน ไปจนถึงไฮเปอร์พารามิเตอร์ที่ถูกเลือกมาตอน Initialize โมเดลที่ต่างกันในแต่ละครั้ง จึงขอแนะนำให้เลือกโมเดลมา 3–5 อันดับแรก เพื่อนำไปทำการ Tuning ต่อไป ซึ่งหลังจาก Tuning เสร็จ ก็จะทำให้ลำดับของโมเดลมีการเปลี่ยนแปลงไปอีก
แต่ก็ใช่ว่าการนำโมเดลทั้งหมดมาเปรียบเทียบแบบนี้จะดีเสมอไป เพราะมันกินเวลามาก ยิ่งข้อมูลเยอะ ก็ยิ่งนานเข้าไปอีก…

และทางออกของความเจ็บปวดในการรอครั้งนี้ ก็มีทางแก้อยู่ใน Pycaret เช่นกัน เพราะฟังก์ชันที่ใช้ในการเปรียบเทียบโมเดลนี้ สามารถเลือกโมเดลที่ต้องการนำมาเปรียบเทียบได้ ด้วยการใส่ชื่อย่อของโมเดลเข้าไปในพารามิเตอร์ที่ชื่อว่า whitelist
best_specific = compare_models(whitelist = [‘dt’,’rf’,’xgboost’])หรือจะเลือกแบนโมเดลไม่ให้ Pycaret เอามาเปรียบเทียบได้ด้วยการใช้พารามิเตอร์ที่ชื่อว่า blacklist (แหม่… ชื่อพารามิเตอร์แอบเหยียดผิวเบา ๆ)
best_specific = compare_models(blacklist = [‘catboost’,’svm’])แต่ถ้าใครมั่นใจแล้วว่าอยากได้โมเดลไหน ไม่อยากได้การเปรียบเทียบใด ๆ ก็สามารถเลือกสร้างโมเดลแบบระบุชื่อได้เลย ด้วยการใช้ฟังก์ชัน create_model
model = create_model(‘lightgbm’, fold = 5)และผลลัพธ์ของขั้นตอนนี้ คือโมเดลที่เหมาะสมกับการนำไปใช้งานต่อไป
แอบบอกอีกนิด ทีเด็ดอีกอย่างหนึ่งของ Pycaret คือเราสามารถแสดงผลลัพธ์ของโมเดลนั้น ๆ ด้วยฟังก์ชันอย่าง plot_model ได้อีก ซึ่งก็ทำให้เราเข้าใจโมเดลของเรามากขึ้นไม่มากก็น้อย หรือจะลองใช้ฟังก์ชันนี้ในโมเดลก่อนที่จะทำการ Tuning กับหลังทำการ Tuning ดูก็เป็นความคิดที่ดีนะ
plot_model(tuned_model, plot = 'confusion_matrix') # Left Hand Sideplot_model(tuned_model, plot = 'feature') # Right Hand Side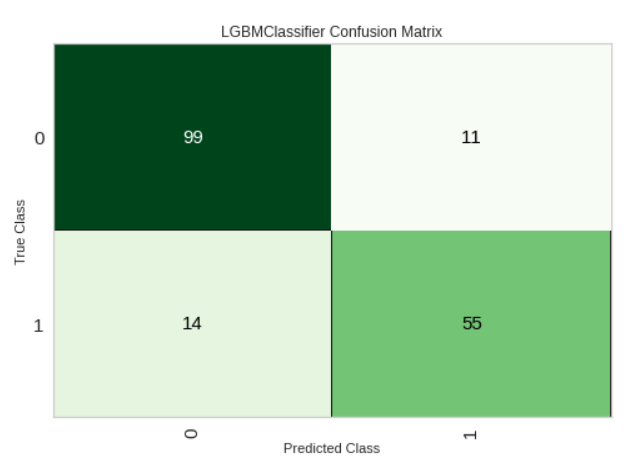
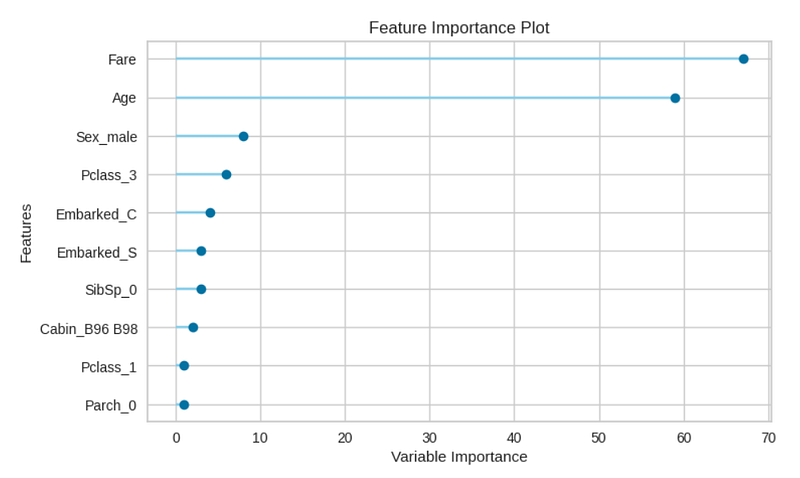
plot_model(tuned_model, plot = 'auc') # Left Hand Sideplot_model(tuned_model, plot = 'pr') # Right Hand Side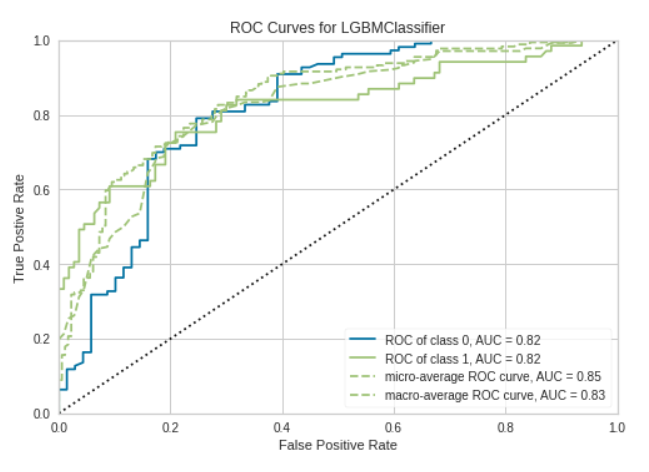
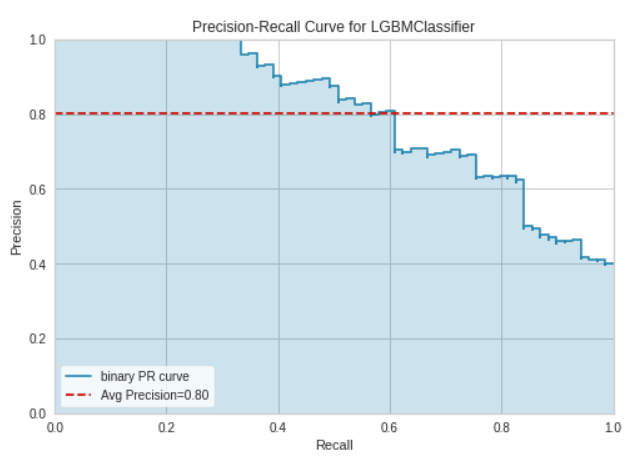
แต่บางโมเดลในขณะนี้ก็ไม่สามารถนำมา plot ได้ด้วยฟังก์ชันนี้ได้ด้วยเหตุผลบางประการ จึงอาจต้องนำผลลัพธ์มา plot ด้วยตนเองหากต้องการรูปในแบบเดียวกัน
Tune Model
ขั้นตอนต่อไปหลังจากที่ได้โมเดลแล้ว ก็คือการนำโมเดลมาปรับค่าไฮเปอร์พารามิเตอร์เพื่อให้ได้ผลลัพธ์ที่ดียิ่งขึ้น ซึ่งใน Pycaret ก็อำนวยความสะดวกให้โดยการใช้ฟังก์ชัน tune_model
tuned_model = tune_model(top5_model[2], optimize = 'Accuracy', n_iter = 30, fold = 5)ฟังก์ชันนี้จะทำการ Random ค่าไฮเปอร์พารามิเตอร์เพื่อหาค่าที่ดีที่สุดและประเมินผลด้วยการใช้ K-Fold เหมือนอย่างเคย โดยที่ n_iter คือจำนวนครั้งในการสุ่มค่าไฮเปอร์พารามิเตอร์ ยิ่งมีค่าเยอะก็ยิ่งดี แต่ก็ยิ่งใช้เวลานานขึ้นเช่นกัน
และผลลัพธ์ที่ได้จากขั้นตอนนี้ คือโมเดลที่มีค่าไฮเปอร์พารามิเตอร์ที่เหมาะสม ที่ให้ค่า Metrics ที่กำหนดในพารามิเตอร์ optimize ได้ดีที่สุด ซึ่งในที่นี้กำหนดให้ Metrics เป็นค่า Accuracy นั่นเอง
นอกจากค่า Accuracy แล้ว เจ้า Pycaret ยังมีทางเลือกในการประเมินผลโมเดลโดยใช้ค่าอื่น ๆ อีกเช่นกัน ดังนี้
- โมเดลประเภท Classification: Accuracy, AUC, Recall, Precision, F1, Kappa, MCC
- โมเดลประเภท Regression: MAE, MSE, RMSE, R2, RMSLE, MAPE
ส่วนใครที่ไม่ชอบวิธีการปรับค่าไฮเปอร์พารามิเตอร์ด้วยการสุ่ม เจ้า Pycaret ก็มีทางเลือกให้อีก โดยการให้เรากำหนดค่าไฮเปอร์พารามิเตอร์ที่ต้องการเหมือนกับ Grid Search ยังไงยังงั้น
params = {'max_depth': np.random.randint(1, (len(data.columns)*.85),20), 'max_features': np.random.randint(1, len(data.columns),20), 'min_samples_leaf': [2,3,4,5,6], 'criterion': ['gini', 'entropy'] }
tuned_dt_custom = tune_model(dt, custom_grid = params)Finalize
เมื่อปรับค่าไฮเปอร์พารามิเตอร์ให้เหมาะสมเป็นที่เรียบร้อยแล้ว หลายครั้งหลายครา โมเดลก็จะถูกนำไปใช้งานเลย ซึ่งก็ไม่ผิดอะไร
แต่สำหรับ Pycaret นั้น จะมีฟังก์ชันในการนำชุดข้อมูลทั้ง Train และ Test มารวมกันอีกครั้ง แล้วนำโมเดลจากขั้นตอนก่อนหน้ามาทำการสร้างใหม่ด้วยข้อมูลทั้งหมดก่อนที่จะนำไปใช้จริง ด้วยการใช้ฟังก์ชัน finalize_model
final_model = finalize_model(tuned_model)และเมื่อได้โมเดลสุดท้ายมาแล้ว เราก็พร้อมที่จะนำไปใช้ทำนายผลลัพธ์ในงานจริง
แต่เดี๋ยวก่อน… เจ้า Pycaret ยังมีฟังก์ชันเพิ่มเติมคือการทำ Ensemble Method หรือการนำโมเดลหลาย ๆ โมเดลมาช่วยกันทำนายผลลัพธ์ เพื่อให้ผลลัพธ์ที่ออกมานั้นถูกต้องมากยิ่งขึ้น ตรงนี้สามารถดูได้ที่ cell เกือบล่างสุดที่ notebook นี้ โดยสามารถกด Copy & Edit ที่มุมขวาบนเพื่อนำไปทดลองใช้เองได้ตามต้องการ
Prediction
สุดท้าย เมื่อได้โมเดลที่พึงพอใจแล้ว เราก็จะเอาโมเดลนั้นไปใช้งานจริงโดยใช้ฟังก์ชัน predict_model โดยต้องมีการกำหนดข้อมูลที่ต้องการให้ทำนายเข้าไปด้วย เพราะหากไม่ได้กำหนดนั้น ฟังก์ชันนี้จะใช้ข้อมูลชุด Test ชุดเดิมที่ถูกแบ่งเอาไว้ตั้งแต่ต้นมาทำนายผลลัพธ์
predictions = predict_model(final_model, data=test_data)และผลลัพธ์ของการทำนายของ Pycaret นั้นจะออกมามีรูปร่างหน้าตาอย่างที่เห็น
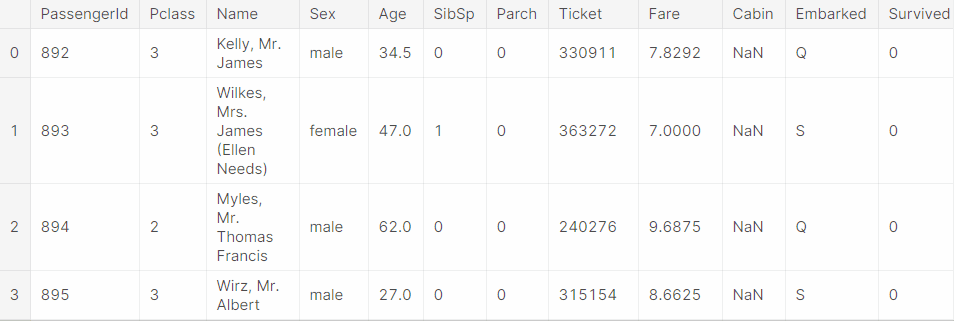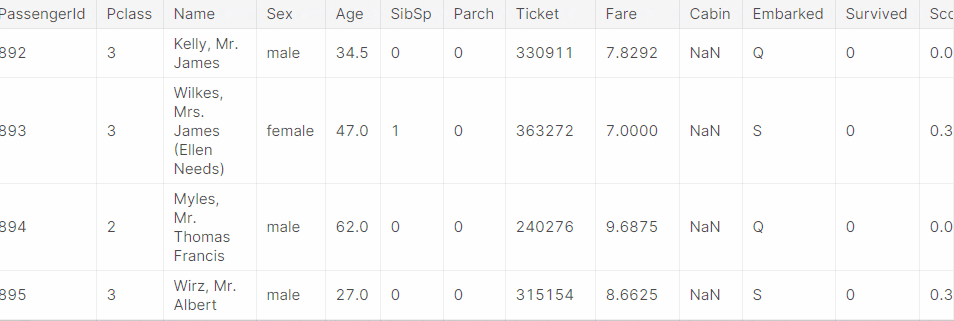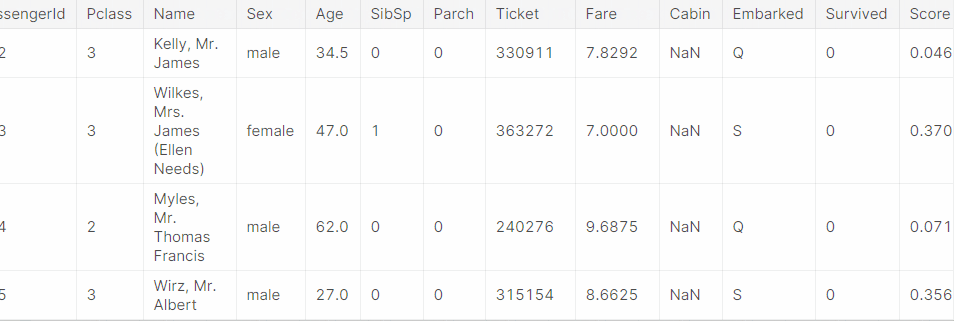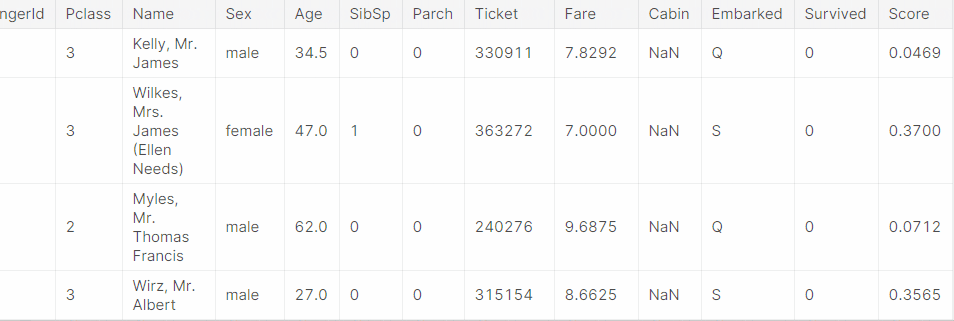
เรียกได้ว่าเป็นชุดข้อมูลที่ต้องการให้ทำนายทั้งชุด โดยมีคอลัมน์เพิ่มเติมคือ คอลัมน์ Label และ Score ที่โมเดลทำนายให้
ส่งท้าย
Pycaret ถือว่าเป็นอีก 1 เครื่องมือที่ดีและฟรี และยังมีความเป็นมิตรกับบุคคลทั่วไปที่ไม่ค่อยมีความเชี่ยวชาญทางด้านการเขียนโปรแกรมอีกด้วย แต่หากเป็นคนที่มีความเชี่ยวชาญอยู่แล้ว ก็อาจใช้ Pycaret เป็นตัวช่วยในการเลือกโมเดลที่เหมาะสมได้ เนื่องจากจะช่วยลดเวลาในการทำงานลงไปอีก
และถ้าผู้อ่านเกิดรู้สึกสนใจขึ้นมา ก็สามารถเข้าไปดูวิธีการใช้งานอื่น ๆ ได้ที่ Official Website ที่นี่เลย
Note
- สิ่งที่น่าสนใจอีกอย่างหนึ่งของ Pycaret คือได้นำเอา MLflow ซึ่งเป็น Library เพื่อการพัฒนา Machine Learning Model มาใส่เอาไว้ด้วย ดังนั้นจึงสามารถใช้ MLflow Tracking เพื่อสร้างพื้นที่เก็บ Evaluation Metrics ต่าง ๆ เอาไว้ให้ผู้ใช้งานอย่างเราสามารถนำมาเปรียบเทียบผลลัพธ์ทีหลังได้อย่างง่ายดาย
- แต่หากไม่ต้องการเริ่มการทำงานของ MLflow Tracking เอง ก็มีบริการดี ๆ จาก Neptune.ai ที่ให้พื้นที่ในการใช้งานบน Server ได้แบบฟรี ๆ ที่สามารถเก็บ Evaluation Metrics ลงไปได้เลยแบบไม่ต้องตั้งค่าใด ๆ ยิ่งไปกว่านั้น เว็บไซต์นี้ยังสามารถทำ Notebook Versioning ได้ แถมเรายังสามารถติดตั้ง Neptune.ai ลงไปเป็นส่วนเสริมของ Jupyter Notebook ได้อีก ชนิดที่เรียกได้ว่า คลิ๊กเมาส์ครั้งเดียวก็ Save เป็น Version นั้นให้เลยทันที
- หากมีข้อผิดพลาดประการใดสามารถแนะนำโดยการเขียนความคิดเห็นไว้ข้างล่างนี้หรือส่ง e-mail มาที่ [email protected] ได้เลยครับ





