
Public LLM leaderboard Computed using Vectara’s Hallucination Evaluation Model
OpenAI’s GPT-4 Turbo currently holds the crown, but Meta’s LLaMA is hot on its heels

Prelude
Large Language Models(LLM) have taken the NLP community AI community the whole world by storm! LLMs are black box AI systems that use deep learning on extremely large datasets to understand and generate new text. Modern LLMs began taking shape in 2014 when the attention mechanism — a machine learning technique designed to mimic human cognitive attention — was introduced in a research paper titled “Neural Machine Translation by Jointly Learning to Align and Translate.” In 2017, that attention mechanism was honed with the introduction of the transformer model in another paper, “Attention Is All You Need.”
Emerging from OpenAI’s labs on November 30, 2022, ChatGPT revolutionized the chatbot landscape, harnessing the power of LLMs like GPT-3.5 and GPT-4. Yet, the race for AI supremacy is far from over, with a myriad of LLMs from rival players striving for dominance. Today, I want to share more with you guys which LLMs are leading the charge and which are playing catch-up.

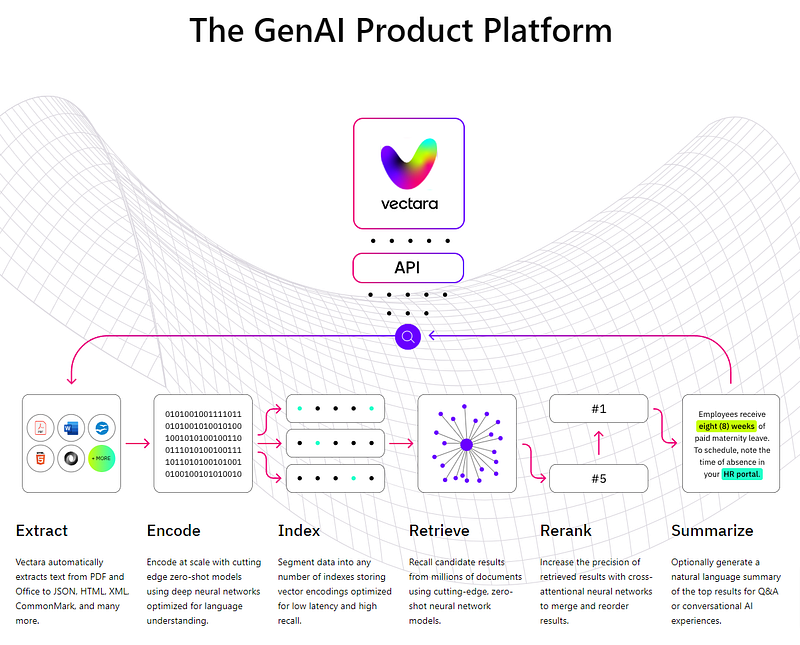
So, what is Vectara?
Vectara is an end-to-end platform for product builders to embed powerful generative AI features into their applications with extraordinary results. It is a platform for companies with moderate to no AI experience that solves use cases, including conversational AI, question/answering, semantic app search, and research & analysis. Vectara is also language agnostic, which means that it can search for information in multiple languages.
Find out more in their website → https://vectara.com/
Methodology
- A model was trained to detect hallucinations in LLM outputs.
- 1000 short documents were summarized by each LLM.
- The accuracy and hallucination rate for each model was computed.
- The rate at which each model refused to respond to the prompt is detailed.
- The documents were taken from the CNN / Daily Mail Corpus.
- A temperature of 0 was used when calling the LLMs.
- Summarization accuracy was evaluated instead of overall factual accuracy.
- Determining hallucinations is impossible to do for any ad hoc question.
- LLMs are increasingly used in RAG pipelines to answer user queries.
- This leaderboard is a good indicator for the accuracy of the models when used in RAG systems.
In the context of large language models (LLMs), a hallucination rate refers to the percentage of times an LLM produces incorrect or misleading information when summarizing a document. It’s like the LLM adding “fake facts” or making up information that’s not supported by the original text. The higher the hallucination rate, the more likely the LLM is to provide inaccurate or misleading information.
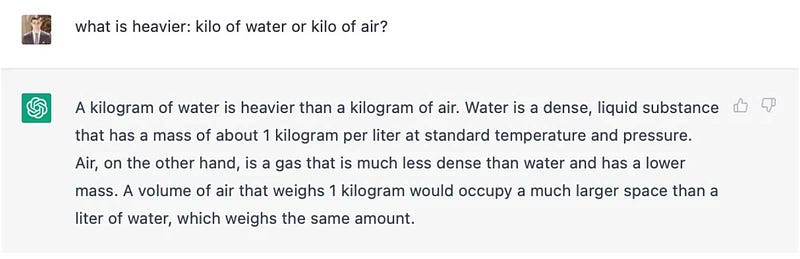
Let’s spot the hallucination in action.

Model Result
Based on Vectara’s Hallucination Evaluation Model, the table provides the accuracy and hallucination rate of different large language models. To be specific, The accuracy rate is the percentage of the model’s responses that are correct, while the hallucination rate is the percentage of responses that are incorrect.
In other words, you may view it as:
Hallicination Rate = 1 - AccuracyGPT-4 has the highest accuracy rate, at 97.0%, followed by GPT-3.5 at 96.5%, and Llama 2 70B at 94.9%. GPT-4 also has the lowest hallucination rate, at 3.0%, followed by GPT-3.5 at 3.5% and Llama 2 70B at 5.1%.
The other models in the table have lower accuracy rates and higher hallucination rates. For example, Google Palm has an accuracy rate of 87.9% and a hallucination rate of 12.1%, while Google Palm-Chat has an accuracy rate of 72.8% and a hallucination rate of 27.2%.
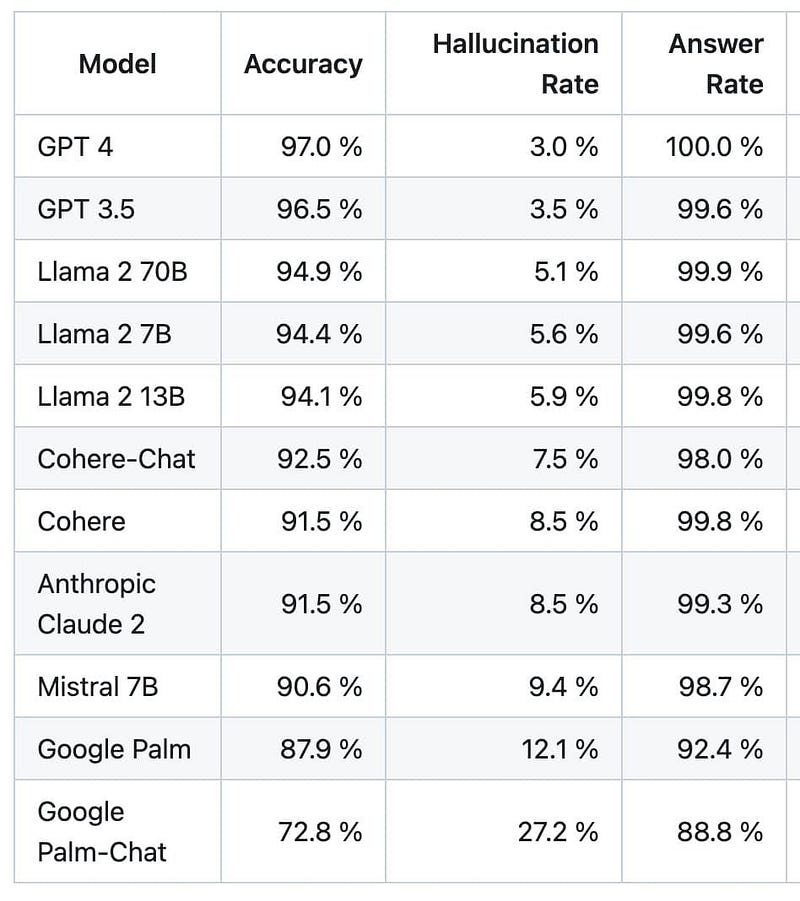
Overall, the table shows that GPT-4 is the most accurate and least hallucinatory large language model currently available as of November 2023. Notably, there is still room for improvement in this area, and AI researchers are still working on developing methods to prevent language models from generating incorrect information. While OpenAI’s GPT-4 Turbo reigns as the current champion, the AI race is far from over and there are new contenders emerging with every passing day.
Additional Readings
- GitHub — vectara/hallucination-leaderboard: Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents
- vectara/hallucination_evaluation_model · Hugging Face
- https://vectara.com/cut-the-bull-detecting-hallucinations-in-large-language-models/
- The Trusted GenAI Product Platform for Product Builders (vectara.com)
- https://github.com/Hannibal046/Awesome-LLM
- https://vectara.com/cut-the-bull-detecting-hallucinations-in-large-language-models/
- https://machinelearningmastery.com/a-gentle-introduction-to-hallucinations-in-large-language-models/




