
Probability: A Philosophical Perspective, Part I

This is the first essay in a series looking at the foundations of probability, and it explores some possible rationalisations. The second essay will critique all probability as a concept.
There’s a second essay as a follow up below
https://readmedium.com/probability-a-philosophical-perspective-part-ii-bc7f4075bc92
Empirical knowledge is sourced from observations of data points and then constructing distributions (even if they are constructed implicitly). This turns out to imply that empirical knowledge is impossible — at least without priors determined by reason or a priori knowledge. (past experience indicates humans are not so good at working out things by abstract reason alone, so prospects for knowledge are dim)
Motivation
Definitions of probability remain very elusive. Mathematically, the definition is not so hard, and questions of probability boil down to counting the number of ‘equally likely’ outcomes in a set. Beyond the mathematics, it is unclear what a probability is.
What probabilities are has important effects on all reasoning. Consider the fine-tuning argument for God. Implicit in the step that ‘the constant is unbelievably finely tuned’ to ‘hence it is unlikely to happen without a God’ the mathematical definition of probability fails us.
Mathematically, what has just occurred is simple Bayesian probability. If we have a distribution for the likelihood of ‘God’ existing (and then him creating life using fine-tuned constants) and a probability distribution for the values that the physical constants could take if God doesn’t exist, then we can construct can compare the sample spaces of how many times life was created as a result of ‘God’ and how many as a result of ‘randomness’.
But clearly this is nonsense. A probability distribution for something which is a necessary being? (Besides, how could we construct a probability distribution for the physical constants?). In the former case a probability distribution cannot be representing ‘pure randomness’ (whatever that means). Rather, it seems, if such a distribution did exist it would be an indicator of uncertainty but not different outcomes. In this case, there is no ‘sample space’ of possible outcomes!
Perhaps probability cannot be applied here — although it is unsatisfying to give up on evidence regarding one of life’s greatest philosophical questions. What about with Science? What is the probability that, given an actual set of rules which describe the universe, sufficient experimentation and tinkering could lead to the wrong set of rules explaining much of it — but at some point running into a block and retarding further progress. This would be akin to finding a minimum point by taking the path with a negative gradient, which can find local minima but not necessarily global minima. If you are familiar with the terminology, this analogy might help: if there are a series of mountains, always walking upwards will ensure you get to the top of a mountain, but not necessarily the top of the tallest mountain.
(This ‘gradient descent’ is what science does. It observes, then changes its theories in order to improve compatibility with observation). Is there a distribution of possible scientific theories we can stumble across?
At the very least, this makes it clear how inadequate our current understanding and formulation of probabilities are. Just because ‘things have worked’ we haven’t had to ask these difficult questions.
Probability in a deterministic world
Consider a game where someone else chooses an integer from 1 to n, and you try to guess it. What do we mean by that person choosing the point ‘randomly’? It is possible that, with enough information, you could perfectly pick what a random number generator (or person) would pick. In this case, we use probabilities as a model of limited information about mechanisms.
With enough observations, it appears the net effect of these unknown causes, is that each number is picked as often. In a deterministic world, there aren’t multiple possibilities. The distribution you pick with a probability of 1/n for each number has terrible mathematical prediction of the one true outcome, which only occurs (1/n)^k times in the model, despite inevitably in the deterministic world.
Say Steve lives on the x-y plane. I gradually place down co-ordinates in a pre-determined way the graph of sin(x). However, he never sees the whole graph, sinx¸ so can never conclude with certainty that it is sin(x), as opposed to the infinite other number of polynomials going through a given set of points. Underlying this is that steve will never be certain about anything unless he has priors about what sort of graph may be put down. He only ever observes finite data points — from his perspective, any moment an errant point could ruin the hypothesis that the line is sinx. In lieu of knowledge of what I am doing above, he will remain truly uncertain.
In the deterministic world, we are steve! Only if we can observe all the data points does uncertainty vanish. But this is impossible.
Can Steve make valid deductions about the graph beyond the points he observes?
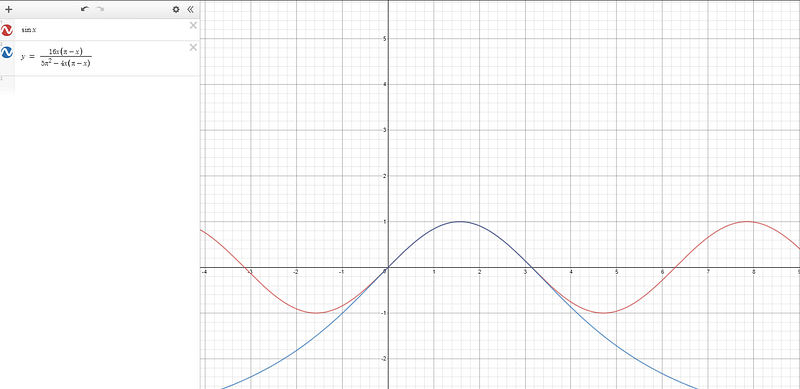
Note in science we essentially see the points placed down and extrapolate equations. Is predictive power a good enough test? What if Steve was predisposed to seeing sin(x), but I was actually placing down a polynomial very close to sinx for the observed data point? The below picture gives an example of how we could easily predict the wrong function based off some data points. The blue function is an excellent approximation to sinx in the range — if you saw a set of data points showing a relationship in that range, how would you know which of the functions was the actual relationship?
Probability in a world with real ‘randomness’
I.e. multiple outcomes are possible.
It is worth noting that the two worlds — probability world and determinist world — are completely identical in our perspective. In the latter we cannot know that each data point was not deterministic, just as in the former we couldn’t know there wasn’t a true element of randomness. In randomness world, suppose we lived in determinist world: any set of data points is consistent.
What does this mean? Do multiple worlds actually pop up every time a random event occurs (and is it deterministic which one we land in)? The issue here is that attempts to understand true random variables in the world always seems to appeal back to their mathematical properties (which were meant to derive from real world phenomena in the first place).
We are assigning a number to something in the world, so we should know what the number symbolises.
If we use out vague understanding of random variables for now we get one crucial point.
In maths, we often start with the distribution and deduce about the outcomes.
In real life, observe and gradually build models of the world around us. (E.g. someone who has been mistreated by many people will have a different distribution for the trustworthiness of people than someone who has never been misled. Perhaps why children tend to be more trusting.) When we only see the data point, and not the outcome, we never know what the distribution it.
Statistical inference; the necessity of priors
What we get to in the end is the impossibility of knowledge. We normally avoid this by evolutionary predisposition towards certain priors.
Consider the following:
Two men saw an event happen, and do not know each other.
I interrogate one of them, who says A happened.
I might be unsure what happened — is this person lying? If I thought they had no good reason to lie (in effect forming a distribution about whether they are the type of person to lie) then perhaps I am satisfied.
I interrogate the second, who also says A happened.
This convinces me, as my brain has a prior distribution about the occurrences of lies. Unless I have good reason to think that they collaborated, this is probably the actual occurrence being described.
We only observe data points, and whether that supports a belief about the world relies on an underlying distribution. With many data points we form a distribution. However, to form a distribution we have to consider the distribution of distributions. Our reasoning for giving a distribution is essentially one of consistency — i.e. to what extent would the model be consistent with the data. However, our degree of confidence in the model being correct must depend on the distribution of models! In an artificial example, if a computer created a normal distribution with mean 0, with each value of x representing the mean of the normal distribution describing a certain variable then if your data has mean 3, the best estimate for the underlying distribution is going to be skewed towards 0 slightly, as this is where the greatest mass of probability re: the underlying distribution is.
You might deny the need for distributions about distributions. But in both cases (random and deterministic) distributions are our method for quantifying either our uncertainty about the deterministic system, or the probabilities involved in a system with true randomness. So if you don’t quantify a distribution for the distributions you remain uncertain about the uncertainty or randomness involved. I.e. you have made no epistemological progress.
This logic can be applied to the distribution for distributions. But by now we are trying to conduct statistical inference with one data point. (The logic still implies an infinite regress.)
Conclusions?
We don’t really understand what we are doing when we use probabilities. This will motivate the second essay, which critiques the theory of probability more generally
Next up: Probability: A Philosophical Perspective, Part II
https://readmedium.com/probability-a-philosophical-perspective-part-ii-bc7f4075bc92





