
Probabilistic machine learning in 5 minutes, an intuition.
Maybe you have not heard about probabilistic machine learning, but as soon as Bayesian models will be implemented into production, it will be a critical, yet difficult, concept to know.

Introduction
Everyone is so happy with neural networks in production, they provide predictive power, and are trendy. However, their productions may not be the best explanation, or better, the unique explanation, for a plethora of different data problems. Remember, neural networks are essentially models that are parametrized by a tensor W of weights. I do not pretend to be here very technical and you may wonder why I am speaking about this, but please just keep reading and do not be afraid. The optimizer of the neural network, via the backpropagation algorithm, estimate some tensor values such that they minimize a loss function L(W) over a particular dataset D. Oh, life is very happy and this is easy… well.. you may be suffering from overfitting…

The problem with a plug-in approximation
If you think about it, your W solution is just one hypothesis that explains your dataset D according to the assumptions of your model M, your neural network. In probabilistic machine learning, we call that a “plug-in approximation”, just delivering one set of parameter values as the final solution instead of considering more hypothesis (set of parameter values) that explains the data. In other works, the likelihood of W given M and the data D is high. But life is not that simple. The problem of optimizing the weights of a neural network is high-dimensional, non-convex and multi-modal. The gradient of the loss function with respect to the parameters is very expensive and approximations such as the one done by stochastic gradient descent are very common. Consequently, it is practically impossible that the final solution found by these algorithms represent the best hypothesis that explains our data under the assumptions of the neural network. It may only be a local optima, or a point near the local optima. Hence, more hypotheses would be likely, and not using them to predict new data conditioned to previous data can lead to overfitting. Your k-fold cross validation may help to avoid this, but you can never know whether all your dataset is representative of the target population, or theoretical probability distribution where your dataset comes from. Wow, I am sounding Bayesian here, and that is precisely what I pretend ;-).
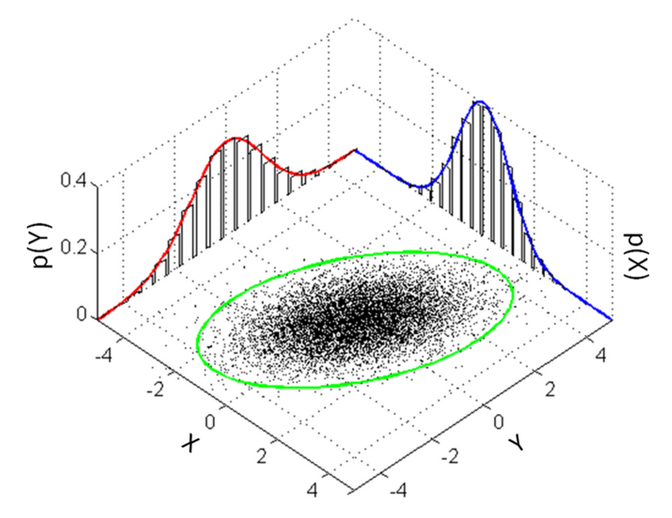
A dataset is a sample of a joint theoretical probability distribution p(y,X)
Because the truth is that your dataset D is just a sample from a complex theoretical joint probability distribution p(y,X) between the target variable y and the explanatory variables X. And the assumptions of the model, such as a neural network, that we are using to get a parametric solution of that joint probability distribution p(y,X )must satisfy the properties of the data. If it satisfies such properties, several hypothesis W, the parameters of the neural network, may have similar likelihood about the data p(y,X|W). The only way to take them all into account is to compute a posterior probability distribution of the parameters with respect to the data p(W|y,X), with the famous Bayes theorem! Where the prior distribution encodes the assumptions that we make about the parameters of the model, in this case, the weights of the neural network.
And how do I predict, then?
Basically, you can use the posterior probability distribution of the parameters of the neural network p(W|y,X) to make a prediction of all the neural networks parametrized with different W and weighted according to p(W|y,X). Instead of just using one neural network parametrized by W, estimated via k-fold CV, we use samples from p(W|y,X), weighted by p(W|y,X) to approximate the true prediction of the whole model, the posterior predictive distribution: p(y) = ∫ p(y|W,X) p(W|y,X) dW. Just observe that in machine learning we just substitute p(W|y,X) by W found by k-fold CV. That is called the plug-in approximation, that is very prone to overfitting. We can approximate p(y) by sampling from p(W|y,X) and do the mean of the predictions using some sampling Markov Chain Monte Carlo technique. I will write another post about it ;-).
How do I know how good is my model?
But how do I do model selection under this framework? Easy, in essence, you must do an expectation (which is a generalization of the empirical mean to the population) about the likelihood of every possible hypothesis and your prior beliefs. The mean of all the likelihoods of the model. That is the marginal likelihood of the data p(X,Y) = ∫ p(X,Y|W)p(W) dW. This is a number, the bigger the best.
It is Bayesian model selection. Unfortunately, it is very costly to obtain these quantites. But to overcome this issue, we will leave that for a future article. Remember to have fun in your work if it is possible and never stop reading!





