
Principles To Code By
How to solve problems, not just code.

What I love most about programming is the problem solving. I don’t believe anyone is born with problem solving skills. It’s a muscle that is built and sustained by repeated exercise. Like any exercise, there’s a set of guidelines to help you be more effective at developing your problem solving muscles. I will introduce five of the most important software design principles that have guided my problem solving process and show you how to apply these principles to solve a real problem.

1. Keep It Simple (KISS) 💋
If there’s anything you should takeaway from this article, it’s the “keep it simple” principle. This principle is often known as KISS, which stands for “Keep it simple, stupid”.
Just because the problem we have to solve is complex, it doesn’t mean our solution has to be complex.
The rest of the principles guide our problem solving strategy to achieve simplicity in our solution. Generally speaking, we develop simple solutions to complicated problems by breaking the complex problem down to simpler sub-problems that we can easily solve.
I’m a fan of learning from examples, so let’s look at an example of what keeping it simple looks like.
Suppose you were asked to write a function with the following signature to check for balanced parentheses in a string. For example, ( returns false, )( returns false, () returns true, foo returns true, and (foo)() returns true.
function hasBalancedParen(str) {
return false;
}So how do we approach this problem?
Step 1 is to apply the KISS principle, develop an outline for an algorithm that can be articulated in simple English:
Given a string
s, which consists of characters
1. Start from the leftmost character and look at each character in the string 2. Keep track of occurrences of
(. 3. Keep track of occurrences of)to “cancel out” a previous occurrence of(. 4. Ignore characters that are not(or). 5. If there’s a)for which there’s no(, return false. 6. Once we finish looking at the last character, if there’s no leftover(or), return true.
The computational complexity is O(N) where N is the length of the string. In the worst case, we have to look at all of the characters in the string to be able to say that the string has balanced parentheses.
2. Separation of Concerns (SoC) 👐
So we have developed our algorithm in simple English, which is essentially pseudocode! There are three logical domains for our algorithm:
- Continue or Stop? — Logic for whether to continue looking at the characters or stop and return true or false.
- Parentheses Tally — Logic for tallying up occurrences of
(and)as we go through the characters. - What to Look At Next? — Logic for determining what to look at next.
Let’s map the six steps of the pseudocode above to one of these three logical domains:
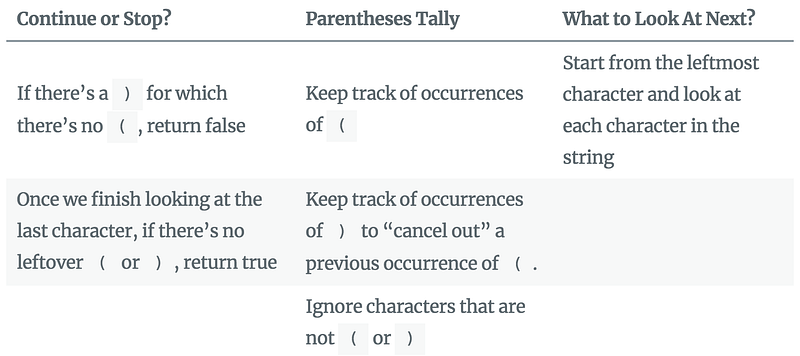
What we just did was we partitioned the algorithm into three logical domains each dealing with a particular concern. Each domain specific concern can be tackled independently by a software component. The three software components are each designed to accomplish a specific mission and need not be concerned with what other components are doing. This demonstrates the principle of Separation of Concerns or SoC.
SoC is the key to developing a complicated application or software system with many moving parts. For example, web applications separate concerns between presentation (how the webpage looks), business logic (content of the webpage), and content delivery (accessing the resource via a JSON API, querying the database, etc).
Poorly executed SoC
I’ve seen poorly designed software in which the software is divided into separate domains but concerns are not separated. Consider the following example:
Write a function foo that doubles then increments every number in an array of numbers.
// Poorly executed separation of concerns// Helper Functions
function double(arrIn) {
let arrOut = []
for (let i = 0; i < arrIn.length; i++) {
arrOut[i] = arrIn[i] * 2
}
return arrOut
}function increment(arrIn) {
let arrOut = []
for (let i = 0; i < arrIn.length; i++) {
arrOut[i] = arrIn[i] + 1
}
return arrOut
}// foo
function foo(arrIn) {
return increment(double(arrIn))
}Why is this a poor execution of SoC?
Well, double and increment are both concerned with looping through an array to modify each elements. Notice how the double and increment functions look almost identical with the exception of how they modify the array element. This is called boilerplate.
Whenever you have boilerplate in your code, you know you can do better in separating concerns. This plays into the next principle:
3. Don’t Repeat Yourself (DRY) 🌵
The Don’t Repeat Yourself (DRY) principle and SoC go hand-in-hand. The DRY principle is aimed at reducing repetition and boilerplate in the software by forming abstractions. I can write a whole separate article on abstractions but here are the key points for how to apply abstraction to write code that doesn’t repeat itself:
- Create functions for common software patterns. We call them higher order functions.
- Replace the boilerplate in your code with higher order functions.
Some examples of higher order functions include:
map— modifying each element in the array based on a give rulefilter— getting a subset of the array that passes a given criterionreduce— combining everything in the array based on a given rule
Let’s apply the DRY principle and rewrite foo to abstract away the boilerplate using the map higher order function:
// Well executed separation of concerns and DRY codeconst double = elem => elem * 2
const increment = elem => elem + 1function foo(arrIn) {
return arrIn.map(elem => increment(double(elem)))
}I’m taking a shortcut by using the ES6 arrow functions, which lets you create elegant one-liners. JavaScript provides higher order functions like map function for Array. Array.map takes one argument: a function. In this example, this function is elem => increment(double(elem)), which takes an argument elem and returns elem * 2 + 1. Since this function doesn’t have a name, it’s called an anonymous function.
Ok that was a long detour. Can we get back to the hasBalancedParen problem?
Yes! We are close to arriving at the final solution but there’s one more principle we need:
4. Divide and Conquer 💪
When you hear “Divide and Conquer” in the context of algorithm design, think recursion. The term recursion has roots in mathematics and commonly entails applying a rule repeatedly to update itself to create an infinite sequence for which the next things in the sequence depends on the previous things in the sequence. For example, fractals, the Fibonacci series, and Pascal’s triangle are all recursive mathematical constructs.
For the Divide and Conquer algorithms, we are interested in the repeated application of a rule but instead of constructing a sequence, we want to deconstruct the problem space and eventually return a final solution. In pseudo code, a recursive function for divide and conquer algorithm has the basic structure:
function recursiveFun(input, output) {
if we hit a base case, updated output as necessary and
return the final output otherwise, simplify the input. update the output, then
return recursiveFun(simplerInput, updatedOutput)
}The emphasis is simplifying input until the problem becomes trivial to solve and we can return an output immediately in the beginning of the function. This is called the base case. What if we forget to add a base case to the recursive function? The function will keep calling itself forever until you run out of memory and get a stack overflow error.
Note, we don’t have to use a recursive function to implement a Divide and Conquer algorithm. We can use a loop and a mutable data structure. I’m not a fan of mutable data structures option although it is more efficient sometimes.
Let’s look at a simple example for a Divide and Conquer algorithm implemented with a recursive function and a mutable data structure:
Write a function sum that takes an array of numbers and returns the sum of all the numbers.
Option 1: Recursive Function
function sum(arr) {function add(arr, sum) {
// Base Case
if (arr.length === 0) return sum // Recursive Step
return add(arr.slice(1), sum + arr[0])
} return add(arr, 0) // <-- Initial Values
}Option 2: Mutable Data Structure
function sum(arr) { // Initial Values
let result = 0
let elems = arr // <-- mutable data structure while(elems.length > 0) { // <-- Base Case
result += elems.pop() // <-- Recursive Step
} return result
}In both Options 1 and 2, every time we repeat the procedure of adding the next element to the current sum, we are creating a simpler array and an updated sum that’s a little closer to the final solution. The stopping point is when we run out of things in the array to add to the current sum, in which case we just return the current sum which is the final solution.
Fans of functional programming and one-liners will implement sum as follows using the higher order function reduce, which JavaScript gives you out-of-the-box for the Array prototype:
const sum = (arr) => arr.reduce((res, elem) => res + elem, 0)With Divide and Conquer, we have the last important problem solving principle to solve the hasBalancedParen problem:
5. Always Test Your Code 💻
The final problem solving principle is to always test your code to make sure there’s no mistake in the implementation and your code behaves correctly for all edge cases. Below I created a unit test that incorporated most of the previous design principles:
KISS
Create a unit test function called test that performs unit testing on a function fun using a set of test cases. We want to be able to run a test for any function like so:
test(fun, testCases)For each test case, test should print to console “passed” if successful or “failed” with more details if unsuccessful.
SoC
Keep the data (the input and expected value) in a data structure called testCases separate from the business logic of unit testing:
DRY
Abstract away the part of code that loops through all the testCases by using a higher order function map:
Run the test
let fun = (str) => hasBalancedParen(str)
test(fun, testCases)Conclusion
Problem solving is the application of knowledge and tools to achieve a desired outcome so the better your knowledge and tools are, the better your problem solving will be. Without a framework for problem solving, the process of problem solving could be inefficient and iterative, requiring rounds of experimentation and refactoring. Use the these five principles to power your problem solving process to write more efficient and beautiful code!

Thanks for reading!
If you are interested in learning more on this topic, please check out some companion articles I’ve written on JavaScript and problem solving:
- Object Oriented Programming in JavaScript
- Problem Solving Using JavaScript
- Let’s Get Productive With JavaScript
- How Functional Programming Promotes Developer Productivity
- Making Sense of Closure With Some Examples
- Why Simple Devs Write Dumb Code
This article was originally published on my blog.
BTW, I started a collection of Coding Challenges and Solutions, which is a GitHub repo on updated frequently with algorithm problems from Cracking the Coding Interview, Leetcode, and actual coding interviews. Check it out for more practice on algorithms.





