
Presto querying data in Azure Blob Storage and Azure Data Lake Store
Recently, I created a simple POC of a single-node Presto querying data in Azure Blob Storage (WASB) and Azure Data Lake Store (ADLS).
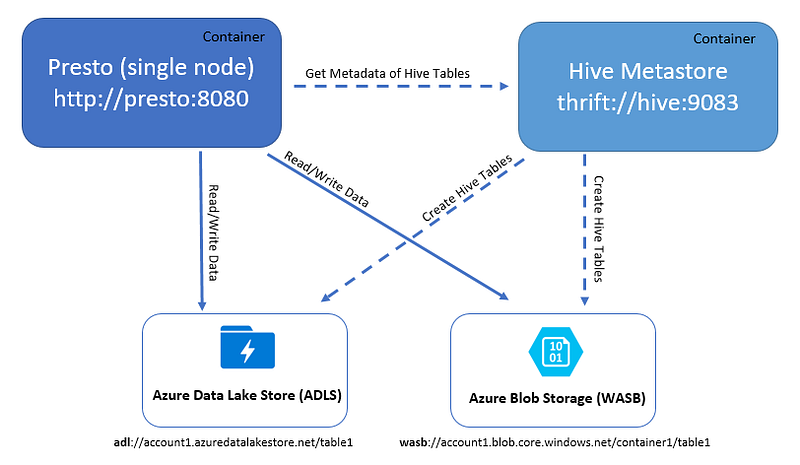
In my example, Presto (version 0.167 or 0.178) is accessing these data stores via Presto’s hive-hadoop2 connector (with a few additional JARs) and needs Hive metastore service to store the metadata about the tables (i.e. table definition, location, and storage format). Therefore, I create Presto and Hive containers and run them via docker-compose on my local machine (or a VM in Azure). Once the containers are running, I execute bash shell (i.e. docker exec -it container_id bash) on the running containers and try reading and writing data into tables backed by Azure Blob Storage and Azure Data Lake Store.
Check out the quick video walkthrough below and the source code in GitHub https://github.com/arsenvlad/docker-presto-adls-wasb
Video Walkthrough
Diagram
Video: Presto with Azure Data Lake Store and Blob Storage
Code: https://github.com/arsenvlad/docker-presto-adls-wasb
Thank you for reading and watching!
I’m looking forward to your feedback and questions via Twitter https://twitter.com/ArsenVlad
Originally published at blogs.msdn.microsoft.com on June 14, 2017.





