
Predicción con Series de Tiempo - Una guía inicial
Introducción
Cuando empecé a escribir esta publicación tuve la intención de solamente explicar cómo hacer predicciones con una serie de tiempo (ST) “sencilla”, es decir, una serie de tiempo univariante. Sin embargo, en el proyecto que me tocó trabajar, la parte complicada era que la predicción debía hacerse en conjunto con múltiples variables. Por esta razón, decidí acercar esta guía un poco más a la realidad y usar una serie de tiempo multivariante.
Primero aclaremos algunos conceptos…
Una Serie de Tiempo Multivariante es una serie de tiempo con más de una variable que depende del tiempo. Cada variable depende de sus valores pasados, pero a la vez también tiene cierto grado de dependencia con otras variables y esta dependencia es tenida en cuenta al predecir los valores. Dichas variables pueden ser endógenas o exógenas. Aquí me estaré enfocando en las variables exógenas.
Una variable exógena es aquella cuyo valor es determinado fuera del modelo e impuesta en el modelo. Dicho de otra forma, son variables que afectan el modelo sin ser afectadas por él. Más info sobre variables exógenas aquí.
Se pueden utilizar varios modelos para resolver una tarea como esta, pero SARIMAX es el que emplearemos. SARIMAX se refiere al Promedio Móvil Integrado Autorregresivo Estacional con Regresores Exógenos.
Bueno, ahora vamos a ver los pasos a seguir para construir un predictor de ventas.
Lidiar con una serie de tiempo implica ciertos desafíos, tales como volverla estacionaria. Si querés saber por qué hice algunas transformaciones al dataframe, podés chequear mi publicación anterior. El enfoque de este artículo es el método para la predicción.
En esta oportunidad tenemos dos archivos: uno con los datos de las ventas anteriores y el otro con información de los feriados nacionales. Como podrás imaginarte, la tarea será tratar de predecir la cantidad de ventas combinando estos dos conjuntos de datos. Luego de cargar los archivos, el dataframe terminará viéndose más o menos así:
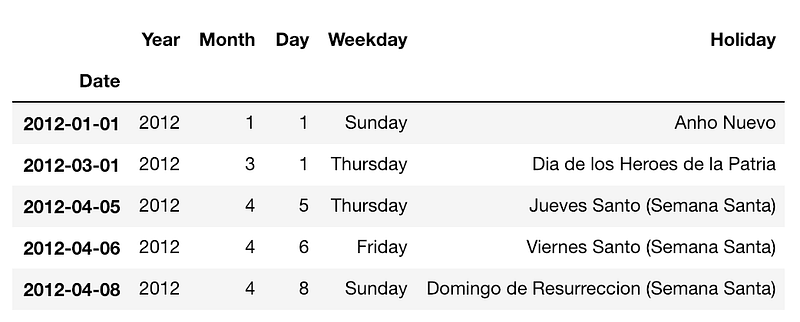
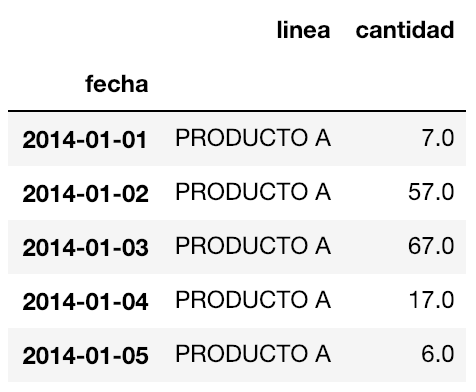
La granularidad de ambos conjuntos de datos está al nivel de Día, es decir, las dos columnas “Date” y “Fecha” son índices con una frecuencia diaria. Si queremos ajustar la frecuencia del conjunto de datos, podemos utilizar la siguiente línea:
ventas_df = ventas_df.resample(‘D’).mean() # 'D' por frecuencia diariaTenemos que unir ambos conjuntos de datos para alimentar nuestro modelo con todos los datos que tenemos. ‘ventas_df’ tiene la variable que queremos predecir. ‘feriados_df’ contiene nuestras variables exógenas.
Para facilitarnos la vida, es mejor “estacionarizar” ventas_df (volverla una ST estacionaria), antes de unirla con feriados_df. El método que utilicé para hacer la serie más estacionaria consiste en aplicar una transformación logarítmica y una diferenciación. La serie estacionaria la guardé en el dataframe ‘ts_log_diff’.
test_stationarity(ts_log_diff)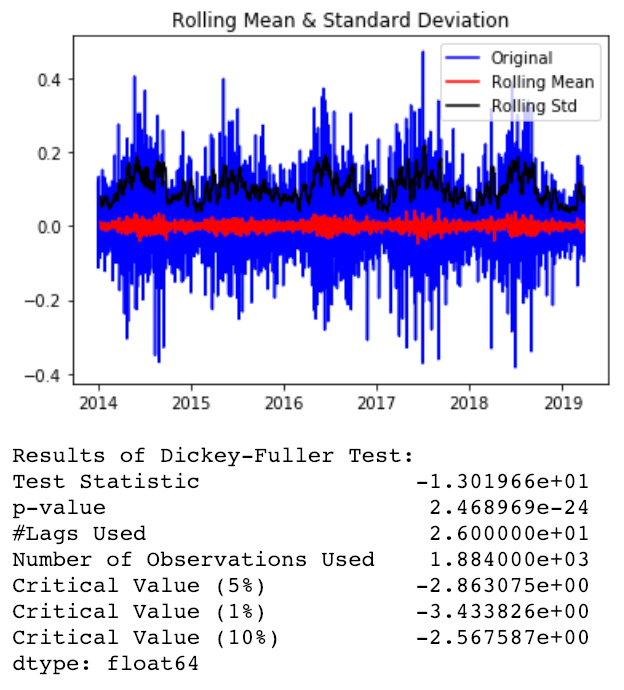
Ahora podemos juntar (JOIN) feriados_df y ts_log_diff, este último es nuestro ventas_df transformado.
data_df = ts_log_diff.join(feriados_df, how='left')
data_df.head()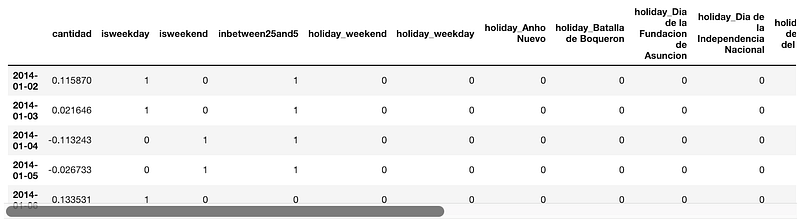
Algunas veces después de realizar algunas operaciones con Pandas, nuestro dataframe resultante, pierde su frecuencia. Para arreglar eso, podemos hacer lo siguiente:
data_df = data_df.asfreq('D')Ahora un poco de Ingeniería de Atributos
A uno se le pueden ocurrir varias ideas para crear nuevos atributos a partir de los que ya existen. Por simplicidad, calculemos solamente las siguientes columnas. - holiday_weekday: si el feriado cayó entre semana - holiday_weekend: si el feriado cayó un fin de semana - isweekday: si la fecha es un día entre semana (Lunes a Viernes) - isweekend: si la fecha es fin de semana (Sábado o Domingo) - inbetween25and5: los sueldos generalmente son pagados durante esos días
data_df['isweekday'] = [1 if d >= 0 and d <= 4 else 0 for d in data_df.index.dayofweek]
data_df['isweekend'] = [0 if d >= 0 and d <= 4 else 1 for d in data_df.index.dayofweek]
data_df['inbetween25and5'] = [1 if d >= 25 or d <= 5 else 0 for d in data_df.index.day]
data_df['holiday_weekend'] = [1 if (we == 1 and h not in [np.nan]) else 0 for we,h in data_df[['isweekend','Holiday']].values]
data_df['holiday_weekday'] = [1 if (wd == 1 and h not in [np.nan]) else 0 for wd,h in data_df[['isweekday','Holiday']].values]Apliquemos también la codificación one-hot en la columna ‘Holiday’.
data_df = pd.get_dummies(data_df, columns=['Holiday'], prefix=['holiday'], dummy_na=True)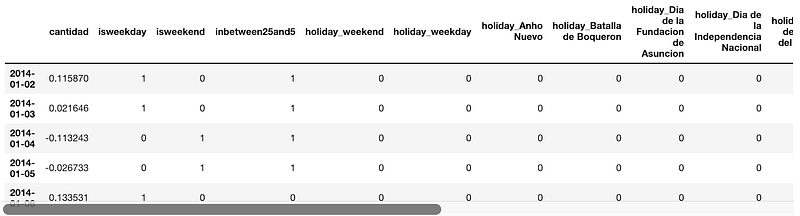
¡¿Podemos predecir ya por favor?!

Ya casi, ya casi… Primero tenemos que dividir nuestros datos en datos entrenamiento y datos de prueba. Ya saben, para seguir buenas prácticas y evitar overfiting ;)
No podemos simplemente aplicar k-folding para dividir nuestro conjunto de datos entre datos de entrenamiento y datos de prueba ya que para la ST necesitamos tener en cuenta el factor de tiempo. Existen ciertas técnicas que podemos aplicar, entre ellas:
- División de Entrenamiento-Prueba, que respete el orden temporal de las observaciones.
- Múltiples divisiones de Entrenamiento-Prueba, que respeten el orden temporal de las observaciones.
- Validación Walk-Forward, donde el modelo pueda actualizarse cada instante de tiempo que reciba datos nuevos.
En este caso, utilizaremos la número uno. Los puntos de datos desde el comienzo de la serie hasta febrero de 2019 servirán como datos de entrenamiento. El resto de los puntos de datos, serán utilizados para las pruebas.
Generando y Visualizando Predicciones
result_daily = my_train_sarimax(data_df[:'2019-02-28'], i_order=(2,1,2), i_freq='D', i_seasonorder=(2, 1, 1, 12))En el bloque de arriba, los datos de entrenamiento ‘data_df[:’2019–02–28’] se pasan a la función.
Vale la pena destacar que la primera columna del dataframe debe contener los valores a predecir. El resto de las columnas son variables exógenas (es decir, feriados y demás atributos agregados).
La frecuencia del dataframe es dada en el argumento ‘i_freq’. Los argumentos ‘i_order’ y ’i_seasonorder’ especifican los parámetros requeridos para entrenar el modelo. Verificá la documentación de SARIMAX para saber más sobre estos parámetros.
La definición de la función my_train_sarimax() es cuanto sigue.

Ahora es el momento de validar nuestras predicciones. Para hacer eso vamos a usar una función para recuperar los valores predichos y luego los compararemos con los valores reales de nuestros datos de prueba.
ypred, ytruth = compare_pred_vs_real(result_daily, data_df, ‘2019–03–01’, exog_validation=data_df[‘2019–03–01’:].iloc[:,1:])Cabe mencionar que se debe proporcionar al modelo las variables exógenas para el periodo de tiempo a predecir. Recordá que estas son variables externas al modelo y éste las necesita para hacer las predicciones.
Si miramos a la definición de ‘compare_pred_vs_real()’, podemos ver que las predicciones son realizadas con la función ‘get_prediction()’. Los valores pueden ser extraídos utilizando el método ‘predicted_mean’.
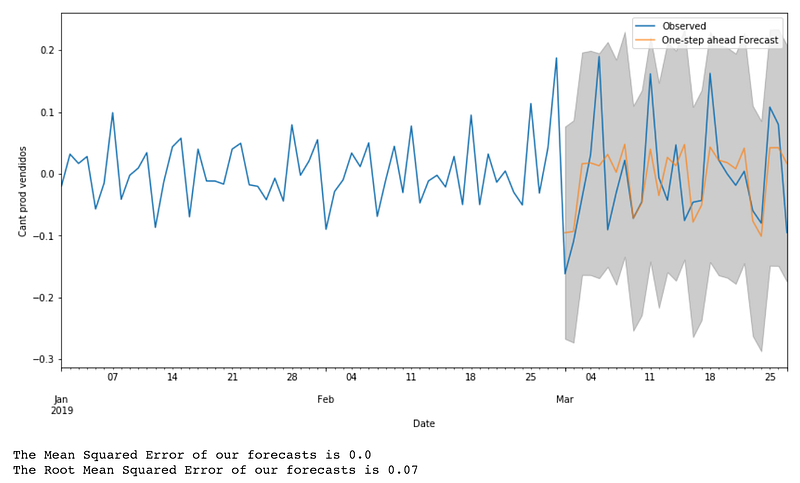
Podemos decir que nuestro modelo tiene un desempeño decente en cuanto a el ECM (Error Cuadrático Medio) y el RECM (Raíz del Error Cuadrático Medio). Veamos qué tan alejadas están nuestras predicciones en comparación a la cantidad real de artículos vendidos.
ypred - ytruth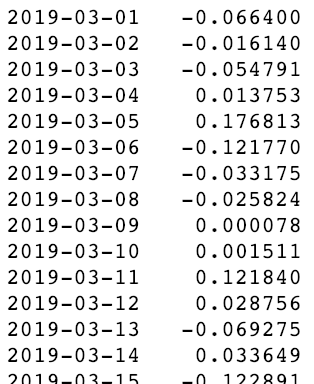
Pero esperá… ¿Por qué vemos valores decimales? La cantidad de artículos vendidos debería ser siempre un número entero.
(Des-)transformando predicciones
Acordate de que hicimos una transformación logarítmica y luego aplicamos una diferenciación a nuestro conjunto de datos. Para poder ver los números reales que nuestro modelo estima que se venderán, debemos revertir esas transformaciones.
La fecha original se perdió a causa de la diferenciación. Necesitamos completar este valor faltante a partir de ‘datos_df’. Después tenemos que anexar ‘y_pred’ a todas las fechas anteriores a la predicción. Estas fechas también vienen de ‘data_df’. Una vez que terminamos con todo eso podemos revertir la diferenciación con cumsum() y luego aplicamos exp() para revertir la transformación logarítmica.
#Crear serie con fechas que fueron eliminadas en la diferenciación
restore_first_values = pd.Series([6.008813], index=[pd.to_datetime(‘2014–01–01’)])#Obtener valores que la predicción no tiene
missing_part = data_df[‘cantidad’][:’2019–02–28']
rebuilt = restore_first_values.append(missing_part).append(ypred)#Revertir diferenciación:
rebuilt = rebuilt.cumsum()#Revertir la transformación logarítmica:
rebuilt = np.exp(rebuilt).round() # apply round() to have integers¡Vamoos! ¡Por fin podemos ver nuestros valores predichos y comprarlos con los valores reales!
# Verificar cuán lejos están las predicciones de los valores reales
rebuilt['2019-03-01':] - ventas_df['cantidad']['2019-03-01':]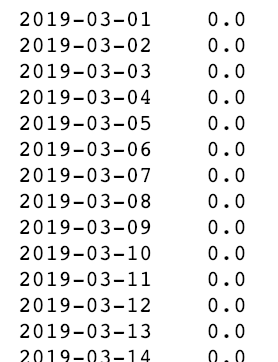
Comentarios finales
Por favor tené en cuenta que se pueden utilizar varios métodos para lograr la estacionaridad en una ST y que SARIMAX no es el único modelo existente que realiza predicciones en series de tiempo. Además, un mejor ajuste de parámetros puede mejorar la precisión del modelo.
No dudes en revisar el código completo para esta guía en mi repo de github.
Gracias por leer.
Esta es una traducción de mi artículo original en inglés: Time Series Forecasting — A Getting Started Guide.





