
Power of Hypothetical Document Embeddings: An In-Depth Exploration of HyDE
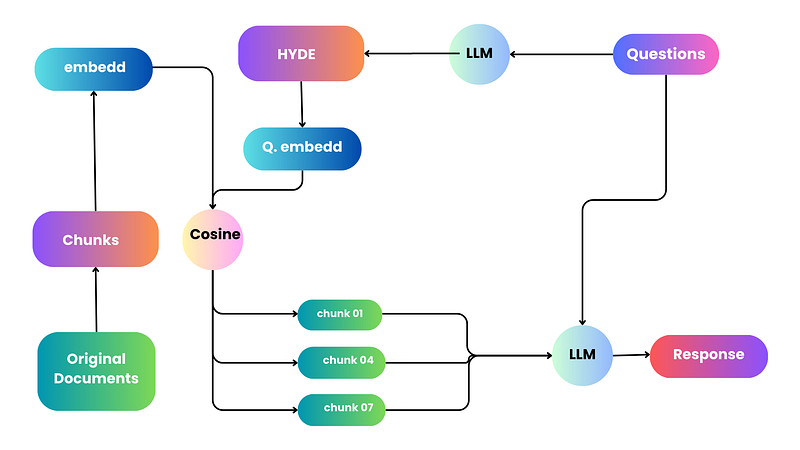
In today’s exploration, we dive deep into a transformative concept in the realm of Retrieval Augmented Generation (RAG) — “Hyde,” or Hypothetical Document Embeddings. Originating from the groundbreaking paper “Precise Zero Shot Dense Retrieval Paper,” this captivating idea surfaced last year, reshaping the way we perceive and engage with dense retrieval and similarity or semantic searches in profound ways. Dense retrieval, at its core, revolves around utilizing similarity searches or semantic searches, typically leveraging a vector store in contemporary applications. Hyde emerges as an exceptionally powerful, yet remarkably simple technique, instrumental in enhancing the efficacy and precision of your RAG system. Despite its influential potential, it seems that this pivotal concept hasn’t garnered the widespread attention it rightly deserves.\
Before we proceed, let’s stay connected! Please consider following me on Medium, and don’t forget to connect with me on LinkedIn for a regular dose of data science and deep learning insights.” 🚀📊🤖
Unlocking the Mysteries of Hyde
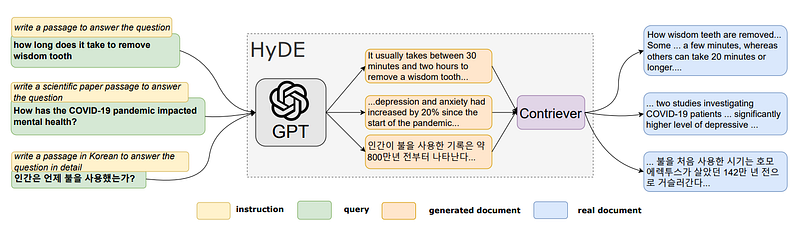
Let’s delve into the heart of this innovative concept by examining the illustrative diagrams and insights drawn directly from the original paper. Hyde, or hypothetical document embeddings, plays a vital role in the world of precise zero-shot dense retrieval without relevance labels. This ingenious approach focuses on augmenting and improving the nuances of similarity searches, often intertwined with vector stores in the modern landscape of information retrieval.
Why Hyde? Navigating Through Practical Scenarios
To navigate through the rationale behind employing Hyde, let us immerse ourselves in a practical scenario. Consider a situation where a query is somewhat bland, lacking distinctive nouns or elements that facilitate an effortless retrieval of a precise answer. Hyde shows its prowess in such challenging terrains.
Example
from langchain.chains import HypotheticalDocumentEmbedder# Load with `web_search` prompt
embeddings = HypotheticalDocumentEmbedder.from_llm(llm,
bge_embeddings,
prompt_key="web_search"
)
# Now we can use it as any embedding class!
result = embeddings.embed_query("What is McDonalds best selling item?")Let us elucidate this with a relatable McDonald’s example. Imagine being queried, “What are McDonald’s best-selling items?” In the absence of specific references such as burgers, shakes, or fries, conducting an embedding search to retrieve a pertinent answer becomes a formidable task. Hyde elegantly navigates this challenge by deploying a language model to draft a hypothetical answer, seamlessly bridging the gap between the query and the accurate answer by enhancing the richness and relevance of the embedding.
Crafting Hypothetical Answers: A Strategy Unveiled
prompt_template = """Please answer the user's question as a single food item
Question: {question}
Answer:"""
prompt = PromptTemplate(input_variables=["question"], template=prompt_template)
llm_chain = LLMChain(llm=llm, prompt=prompt)
embeddings = HypotheticalDocumentEmbedder(
llm_chain=llm_chain,
base_embeddings=bge_embeddings
)
result = embeddings.embed_query(
"What is is McDonalds best selling item?"
)The crafted hypothetical answer doesn’t directly interact with the end-user. Its primary function is to enhance the quality of the embedding for a more refined search result. The language model, even when it produces an inaccurate answer, infuses the necessary elements into the response, enriching the embedding and improving the likelihood of retrieving a fitting answer. This ingenious approach shifts the paradigm from a query-to-answer embedding similarity to an answer-to-answer embedding similarity, often yielding more accurate and relevant results.
Adaptive and Flexible: The Multi-Answer Strategy
multi_llm = OpenAI(n=4, best_of=4)
embeddings = HypotheticalDocumentEmbedder.from_llm(
multi_llm, bge_embeddings, "web_search"
)
result = embeddings.embed_query("What is McDonalds best selling item?")Hyde’s adaptability shines through its ability to generate multiple hypothetical answers, offering a broader spectrum of embeddings for comparison. This multitude of answers can be seamlessly integrated into the embedding model, averaged out, and utilized to enhance the precision of the search results, showcasing Hyde’s flexibility and prowess in navigating the complex terrains of information retrieval.
Conclusion:
In conclusion, HyDE emerges as a remarkable revelation in the domain of information retrieval, fortifying the process with enriched and nuanced embeddings generated from hypothetical answers. Throughout this article, the walkthrough of HyDE’s architecture and its coded symphony elucidated its profound impact and usability in enhancing the retrieval processes in RAG. The careful orchestration of base embeddings, large language models, and custom prompts, among other elements, manifests in a harmonized output, essential for advanced and accurate information retrieval. It symbolizes a potent amalgamation of strategy and technology, holding significant promise for future explorations and adaptations in various projects within the vast and diverse universe of NLP. As we stand on the brink of innovative horizons, HyDE exemplifies the continuous journey towards excellence and refinement in the realms of natural language understanding and processing.





