Poker Test: pattern-based random number detection in Python

Random numbers or pseudorandom numbers? This is a trivial question and sometimes requires knowledge based on cryptography theory more than statistical proof, thus noise-friendly output can be used in cryptographic, modeling and simulation applications. Random output in a binary sequence can be represented with digits that have entropy = 1. For this reason we should represent many important keys that will help the reader to understand this article. We will serve some definitions e.g. what is called pseudorandom sequence and random sequence.
Random Sequence
Random sequence could be interpreted as the result of an unbiased “fair” coin with sides that are labeled 0 and 1 and each of them having the probability of exactly 1/2 of producing a 0 or 1, in other words this problem reflects an entropy equal to 1. Moreover, the flips are independent of each other, the result of any previous coin flip will not affect future coins. The unbiased “fair” coin is thus the perfect random bit stream generator, since the “0” and “1” values will be randomly distributed ([0,1] uniformly distributed) . All elements of the sequence are generated independently of each other, and the next digit of the sequence can not be predicted.
- The elements of the sequence are statistically independent and follow a uniform distribution in the interval from which they came.
- It is not possible to predict the next elementt of the sequence knowing the previous, in other words it is difficult to reproduce the sequence.
Pseudorandom Sequence
Pseudorandom numbers can be produced from generators that get an input that it is known as seed. When the user does not know the seed then it’s hard to predict the next number even if the previous one of the sequence is known (aka forward unpredictability) and vice versa. On the other hand , if someone knows any generated part of the sequence, it should not be feasible to determine the seed.
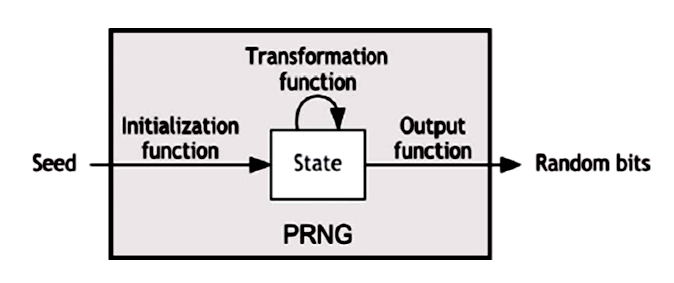
- The elements of this sequence can be reproduced and this is because those sequences are generated with a deterministic mode of production.
- Pseudorandom sequences can present periodically and entropy and this is the reason that can be predicted.
The test that we will use relies on the concept that a sequence, even if it follows a uniform distribution, it can not be claimed as random . Moreover, this tests checks if there is a correlation between the digits of the sequence and extracts information from patterns of the well known card game Poker.
Process
Let us assume a sequence of 5 consecutive integers like those that follow:
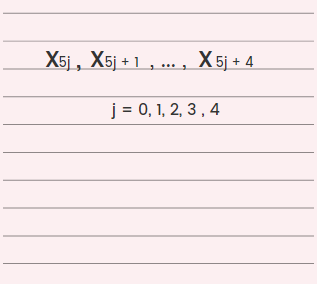
All we have to do is determine if they match with one of the orderless seven combinations that follow:
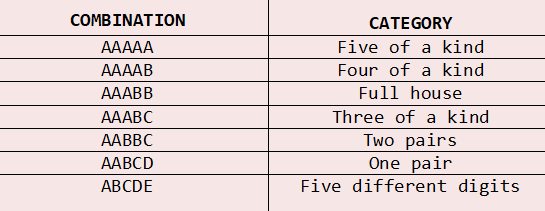
A chi-square test X² can be applied, based on the number of the quintuples in each category when we have a sequence in decimal system. Sometimes categories can make groups in order to meet the “five in each category” condition. To be more specific, this test uses a simpler version to facilitate the programming involved. In the set of five numbers we count the number of distinct values and then the categories could sum on five instead of seven.

In our case, we will introduce poker test in a binary sequence e.g. 010010011010100101… So, every time you want to understand whether your sorted binary attribute that is used for your prediction model is biased or not, make sure that it’s randomly distributed. Otherwise, your output can’t rely on such independent variables which fail to pass the poker test. In other words, the feature selection you have done could be wrong, even if the binary dataset is balanced.
Hypothesis Test for Randomness using Chi-Square Test
In previous articles we used a lot the well-known non parametric test Χ² but we used it as a method to make a goodness of fit in a specific distribution. This time we will use this method in order to decide whether our output is random or not. In case of a binary output such as A or B, like 1 or 0 and Yes or No, probabilities help you understand that, if the output is random, then p₀ = p₁, when
★ p₀: The probability that the next digit is equal to 0
★ p₁: The probability that the next digit is equal to 1
This means that both events have the same probability to occur. So, this test can ensure that no number is displayed more than others, and the data is uniformly distributed. In general, the random test in X² has Ho: p₀ = p₁ and H₁ : p₀ ≠p₁. The test statistic has m freedom degree where m is the length of each part of digits that we use in the bit sequence. As you can see below, we represent the test statistic that we will use in randomness test and then we will discuss why it has the following form in functional call where C(d,i) is the i combination of d, where d is the length of each k non overlapping part.
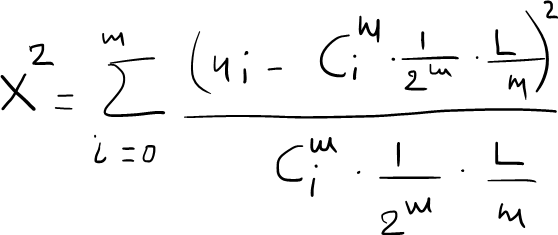
Function Call
We choose an integer m and we divide sequence in k non overlap parts each of which has a length equal to k = n/m and let nᵢ be the observed number of occurenes of the iᵗʰ type of sequence of length 2ᵐ. The poker test determines if the sequence of length 2ᵐ each appear the same number of times in sequence , as we could expect it for a truly random sequence.
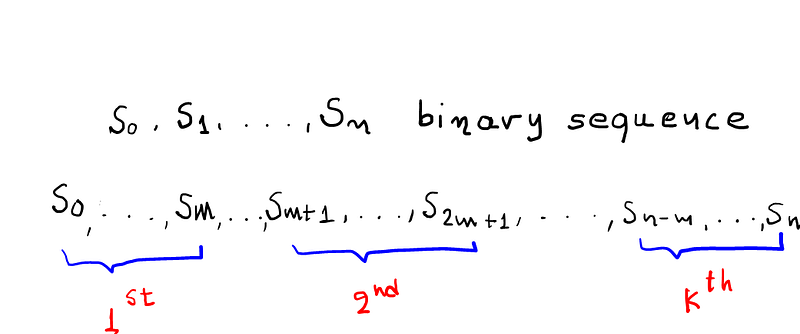
In this part, we will give an example using hand calculations at first and Python code later on.
Example. Let’s have the following sequence s with length L = 30, we choose m = 3 and so k = 30/3 = 10.
s = 100 111 101 110 011 001 101 001 010 000
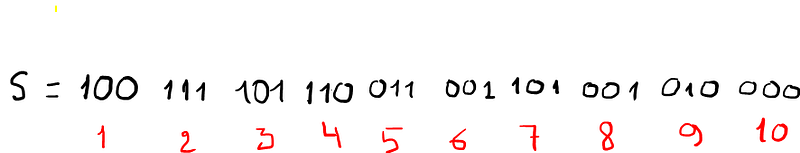
We need to calculate the frequency nᵢ. For this reason we have exactly 8 = 2³ combinations which are the following:

After finding the frequency each sample occurred in our sequence, we are ready for calculations…
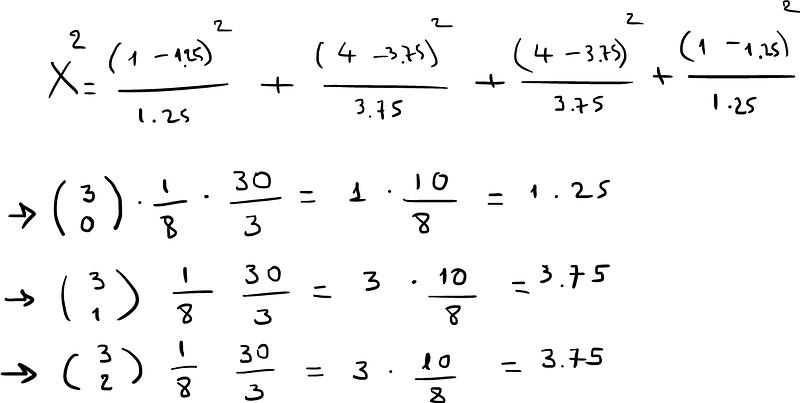
From all the calculations above, finally we extract X² = 0.133 and now it is time to compare it with the Xo² with m = 3 degrees of freedom which is equal to 7.814 with a = 0.05. So 0.133 < 7.814 and this means that we can’t reject Ho and our sequence tends to be random!
Python Code
We create a function named PokerTest which takes as an input a bit sequence in string format and an integer m. If the sequence is random, then this function returns ‘The sequence is random’ else the bit sequence fails to pass the poker test. As we mentioned before, this can help detect fraud patterns in outputs that are correlated with binary target or binary features that want to use in a specific analysis only for sorted values.
Thank you for your time!