
Personalized recommendations: Two tower models for retrieval
Credits:
Seminal paper:
Deep Neural Networks for YouTube Recommendations (2016): https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45530.pdf
In 2016 Google introduced the paper where they talked about benifits of new architecture for using DL networks in a way that is not an extension to application of DL neural nets to matrix factorization techniques used prior to this. This blog post will elucidate the key concepts introduced in the paper listed above.
This paper is old but has stood the test of time and today most recommendations systems at scale have some version of this architecture adapted to more realtime use cases.
Here are some key insights from the paper:
In contrast to vast amount of research in matrix factorization methods, there is relatively little work using deep neural networks for recommendation systems.
SYSTEM OVERVIEW
The system is comprised of two neural networks: one for candidate generation and one for ranking. The candidate generation network takes events from the user’s YouTube activity history as input and retrieves a small subset (hundreds) of videos from a large corpus. These candidates are intended to be generally relevant to the user with high precision. The candidate generation network only provides broad personalization via collaborative filtering. The similarity between users is expressed in terms of coarse features such as IDs of video watches, search query tokens and demographics. Presenting a few “best” recommendations in a list requires a fine-level representation to distinguish relative importance among candidates with high recall. The ranking network accomplishes this task by assigning a score to each video according to a desired objective function using a rich set of features describing the video and user. The highest scoring videos are presented to the user, ranked by their score.
This design enables blending candidates generated by other sources for ranking.
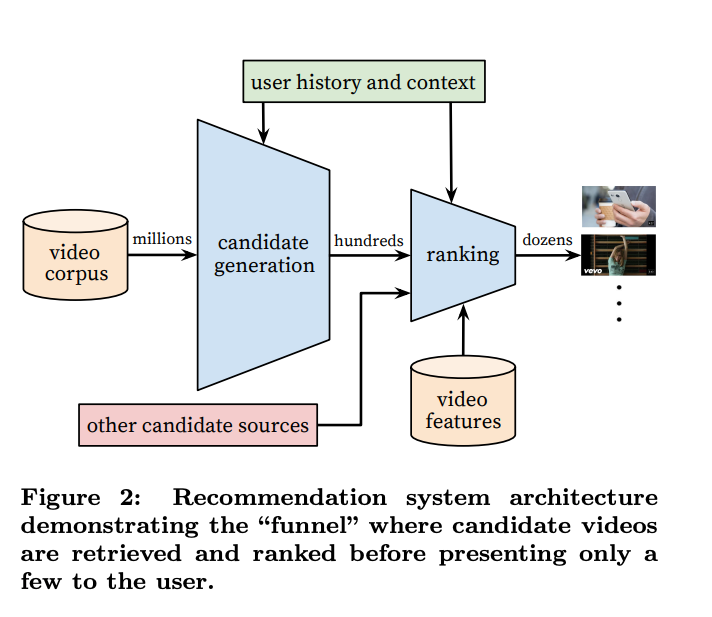
Key insight #1: Separating candidate retrieval from ranking allows for efficient and low latency candidate generation optimised for increasing recall. While ranking is more expensive with lot more features and objectives added to the ranker, but since its only scoring the candidates over all effort is more optimized towards ranking objectives like avoiding spammy engagements, higher watch time, realtime adaptation to user recent behaviour.
CANDIDATE GENERATION
The predecessor to the recommender described here was a matrix factorization approach trained under rank loss [23]. Early iterations of our neural network model mimicked this factorization behavior with shallow networks that only embedded the user’s previous watches. From this perspective, our approach can be viewed as a nonlinear generalization of factorization techniques.
We pose recommendation as extreme multiclass classification where the prediction problem becomes accurately classifying a specific video watch wt at time t among millions of videos i (classes) from a corpus V based on a user U and context C,
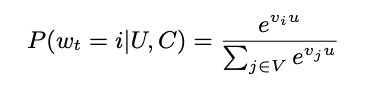
where u ∈ R N represents a high-dimensional “embedding” of the user, context pair and the vj ∈ R N represent embeddings of each candidate video
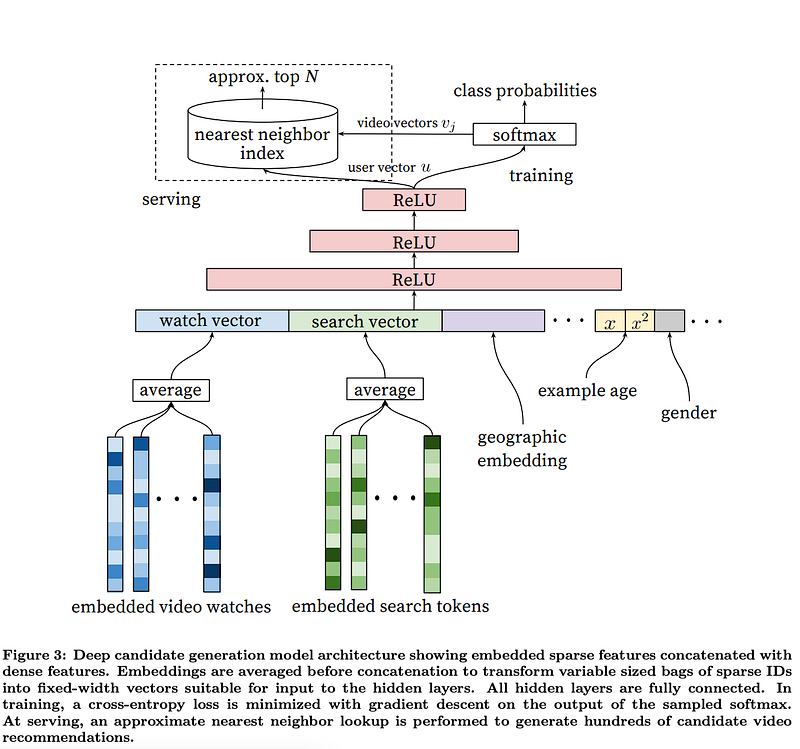
The task of the deep neural network is to learn user embeddings u as a function of the user’s history and context that are useful for discriminating among videos with a softmax classifier. Although explicit feedback mechanisms exist on YouTube (thumbs up/down, in-product surveys, etc.) we use the implicit feedback [16] of watches to train the model, where a user completing a video is a positive example. This choice is based on the orders of magnitude more implicit user history available, allowing us to produce recommendations deep in the tail where explicit feedback is extremely sparse.
Efficient Extreme Multiclass: To efficiently train such a model with millions of classes, we rely on a technique to sample negative classes from the background distribution (“candidate sampling”) and then correct for this sampling via importance weighting [10]. For each example the cross-entropy loss is minimized for the true label and the sampled negative classes. In practice several thousand negatives are sampled, corresponding to more than 100 times speedup over traditional softmax. A popular alternative approach is hierarchical softmax [15], but we weren’t able to achieve comparable accuracy. In hierarchical softmax, traversing each node in the tree involves discriminating between sets of classes that are often unrelated, making the classification problem much more difficult and degrading performance.
Since calibrated likelihoods from the softmax output layer are not needed at serving time, the scoring problem reduces to a nearest neighbor search in the dot product space
A key advantage of using deep neural networks as a generalization of matrix factorization is that arbitrary continuous and categorical features can be easily added to the model. Search history is treated similarly to watch history — each query is tokenized into unigrams and bigrams and each token is embedded. Once averaged, the user’s tokenized, embedded queries represent a summarized dense search history.
Key insight #2: We dont care about calibrated probabilities for candidate generation so simpler and efficient techniques like vector embedding databases for storing and retriving nearest neighbour embeddings are used.
RANKING
The primary role of ranking is to use impression data to specialize and calibrate candidate predictions for the particular user interface. For example, a user may watch a given video with high probability generally but is unlikely to click on the specific homepage impression due to the choice of thumbnail image. During ranking, we have access to many more features describing the video and the user’s relationship to the video because only a few hundred videos are being scored rather than the millions scored in candidate generation. Ranking is also crucial for ensembling different candidate sources whose scores are not directly comparable. We use a deep neural network with similar architecture as candidate generation to assign an independent score to each video impression using logistic regression (Figure 7). The list of videos is then sorted by this score and returned to the user. Our final ranking objective is constantly being tuned based on live A/B testing results but is generally a simple function of expected watch time per impression. Ranking by click-through rate often promotes deceptive videos that the user does not complete (“clickbait”) whereas watch time better captures engagement
Feature Engineering: We typically use hundreds of features in our ranking models, roughly split evenly between categorical and continuous. Despite the promise of deep learning to alleviate the burden of engineering features by hand, the nature of our raw data does not easily lend itself to be input directly into feedforward neural networks.
The main challenge is in representing a temporal sequence of user actions and how these actions relate to the video impression being scored.
As an example, consider the user’s past history with the channel that uploaded the video being scored — how many videos has the user watched from this channel? When was the last time the user watched a video on this topic? These continuous features describing past user actions on related items are particularly powerful because they generalize well across disparate items. We have also found it crucial to propagate information from candidate generation into ranking in the form of features, e.g. which sources nominated this video candidate? What scores did they assign? Features describing the frequency of past video impressions are also critical for introducing “churn” in recommendations (successive requests do not return identical lists). If a user was recently recommended a video but did not watch it then the model will naturally demote this impression on the next page load. Serving up-to-the-second impression and watch history is an engineering feat onto itself outside the scope of this paper, but is vital for producing responsive recommendations
Key insight #3: Ranking is lot more feature dense and uses a lot of recent history features to adapt the ranker for more realtime relevant recommendations.
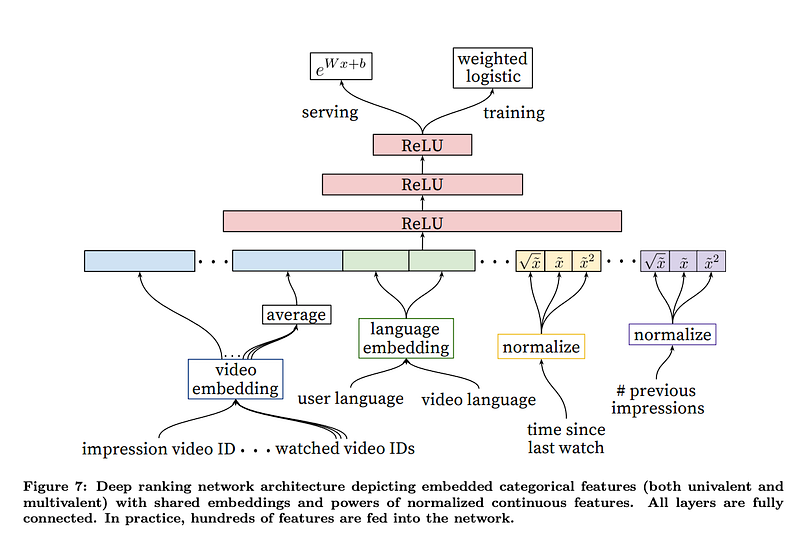
Embedding Categorical Features: Similar to candidate generation, we use embeddings to map sparse categorical features to dense representations suitable for neural networks. Each unique ID space (“vocabulary”) has a separate learned embedding with dimension that increases approximately proportional to the logarithm of the number of unique values. These vocabularies are simple look-up tables built by passing over the data once before training. Very large cardinality ID spaces (e.g. video IDs or search query terms) are truncated by including only the top N after sorting based on their frequency in clicked impressions. Out-of-vocabulary values are simply mapped to the zero embedding. As in candidate generation, multivalent categorical feature embeddings are averaged before being fed in to the network.
Normalizing Continuous Features: Neural networks are notoriously sensitive to the scaling and distribution of their inputs [9] whereas alternative approaches such as ensembles of decision trees are invariant to scaling of individual features. We found that proper normalization of continuous features was critical for convergence. A continuous feature x with distribution f is transformed to ˜x by scaling the values such that the feature is equally distributed in [0, 1) using the cumulative distribution, ˜x = R x −∞ df. This integral is approximated with linear interpolation on the quantiles of the feature values computed in a single pass over the data before training begins. In addition to the raw normalized feature ˜x, we also input powers ˜x 2 and √ x˜, giving the network more expressive power by allowing it to easily form super- and sub-linear functions of the feature. Feeding powers of continuous features was found to improve offline accuracy.
Key insight #4: Feature engineering is important for dense feature ranker. Especially interesting is including the square and sqareroot of continuous features to let the model learn easily from super and sub linear functions of features.
Modeling Expected Watch Time: Our goal is to predict expected watch time given training examples that are either positive (the video impression was clicked) or negative (the impression was not clicked). Positive examples are annotated with the amount of time the user spent watching the video. To predict expected watch time we use the technique of weighted logistic regression, which was developed for this purpose. The model is trained with logistic regression under crossentropy loss (Figure 7). However, the positive (clicked) impressions are weighted by the observed watch time on the video. Negative (unclicked) impressions all receive unit weight. In this way, the odds learned by the logistic regression are P Ti N−k where N is the number of training examples, k is the number of positive impressions, and Ti is the watch time of the ith impression. Assuming the fraction of positive impressions is small (which is true in our case), the learned odds are approximately E[T](1 + P), where P is the click probability and E[T] is the expected watch time of the impression. Since P is small, this product is close to E[T]. For inference we use the exponential function e x as the final activation function to produce these odds that closely estimate expected watch time.
Key insight #5: Generated calibrated probabilities in ranker by using logistic regression classifier. Weighted logistic regression allows for blending in watch time with the clicked on / watched videos.



