
PDF Operations Using Python
Automate your daily tasks that concerns PDF files: extraction of texts and graphics, decryption, editing/merging/re-organizing/saving and deleting of PDF pages.
Overview of the PDF Operations to be covered:
Python Library: PyMuPDF Document Information Page Processing ∘ Page Loading ∘ Page Iteration ∘ Links in Page ∘ Annotations or Widgets in Page ∘ Create a Page Image as a Pixmap Object ∘ Extracting Texts and Images ∘ Word Searching File Operations ∘ Page Editing ∘ Merging & Spliting ∘ Saving File ∘ Closing File
Python Library: PyMuPDF
PyMuPDF is a Python binding for MuPDF, which is a lightweight PDF, XPS and E-book viewer, renderer and toolkit. MuPDF is compatible with PDF, XPS, OpenXPS, CBZ, EPUB and FictionBook2 formats. Using PyMuPDF, you could access files of all these extensions, as well as image file extensions including PNG, JPG, BMP, TIFF.
- Installation:
pip install PyMuPDF - Import:
import fitz
Document Information
First, open the file like follows:
doc = fitz.open("camille-medium.pdf")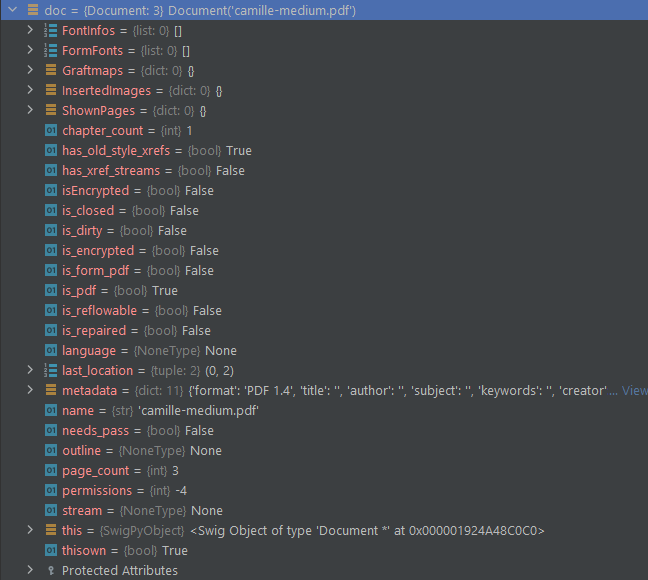
Using the doc file obtained, you could retrieve information such as number of pages, document metadata, table of content or other fields as shown in the picture.
# get number of pages
doc.page_count
>>> 3# get file metadata
doc.metadata# get table of content as list
doc.get_toc()
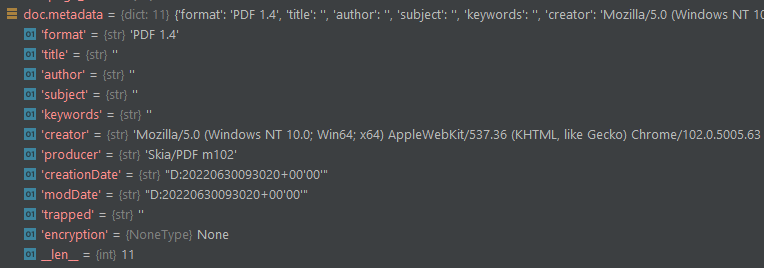
>>> []A sample output for doc.metadata :
Page Processing
Page Loading
The doc object works like a sequence here
# load first page
doc.load_page(page_id=0)
# OR
doc[0]# load last page
doc[-1]Page Iteration
# for in sequence
for page in doc:
# todo# read backwards
for page in reversed(doc):
# todo# use slicing
for page in doc.pages(start, end, step):
# todoLinks in Page
links = page.get_links() # Python dictionaryAnnotations or Widgets in Page
annots = page.annots()
widgets = page.widgets()Create a Page Image as a Pixmap Object
Pixmaps objects here represent plane rectangular sets of pixels. Each pixel is described by a number of bytes (“components”) defining its color, plus an optional alpha byte defining its transparency.
pixmap = page.get_pixmap()The image could be saved as PNG file:
pixmap.save(f"page{page.number}.png"Extract Texts and Images
text = page.get_text(opt)For the parameter opt , you could choose from the following output format options: “text” (default), “blocks”, “words”, “html”, “xhtml”, “xml”, “dict”, “json”, “rawdict”, “rawjson”.
Word Search
The function returns a list of Rect objects, each representing one instance of the word “Jun”, including information about the exact locations the word appears in the page.
page.search_for("Jun")File Operations
PDF is the only format that could be edited using PyMuPDF , the other formats are all read-only. However, you could convert any document to PDF format using doc.convert_to_pdf() and edit the converted file instead.
Page Editing
- Deletion:
doc.delete_page()
doc.delete_pages()- Copying:
doc.copy_page()
doc.fullcopy_page()- Organization:
doc.move_page()- Selection
doc.select() allows you to select certain pages and remove the rest, for example, odd pages only, first page only, last 10 pages, etc.
- Insertion
doc.insert_page()
doc.new_page()There are also other operations such as rotation, annotation and text/image insertion.
Merging & Spliting
- Merging using
doc.insert_pdf()
For example, to append doc2 to the end of doc1: doc1.insert_pdf(doc2)
- Spliting
The following codes are used to split and get the first 5 and last 2 pages of the original document and save into a new file.
# create a new empty PDF
new_doc = fitz.open()# insert first 5 pages
new_doc.insert_pdf(doc, to_page=4)# insert the last 2 pages
new_doc.insert_pdf(doc, from_page=len(doc)-2)# save the new file
new_doc.save("first5_and_last2.pdf")Saving File
doc.save() always saves the file as its current status. You could append the changes to the original file instead by adding a parameter incremental=True without completely overwriting the file.
Closing File
doc.close() helps to close the file so that it could be accessed and updated elsewhere.
Hope this helps and thanks all for reading!






