
[Part 0] - Journey to a modern data architecture (in 2022)

Motivation
With this suite of articles, I want to try to formalize and structure my thinking and what is the current direction of data and what that implies for data architecture. And this is obviously a good opportunity to share that experience. 😊
Data mesh organization
The journey begins with a trendy concept : “Data Mesh”.
The core principles are as follow:
- Domain drive distributed architecture: which aims to break the monolithic, centralized BigData platform into domain-oriented organization,
- Product thinking: considering data as a product,
- Multi-skilled team: where each domain brings together Data Engineers, Ops, Data Analysts, Data Scientists, BI Engineers and Software Engineers that span the data domain from application to data analytics,
- Ecosystem Governance: where each domain data pipeline lives their own life, but where the domain boundaries are defined and controlled by global gouvernance and standards,
- Self-service Infra As Platform: with the entire organization supported by a self-service Data infrastructure.
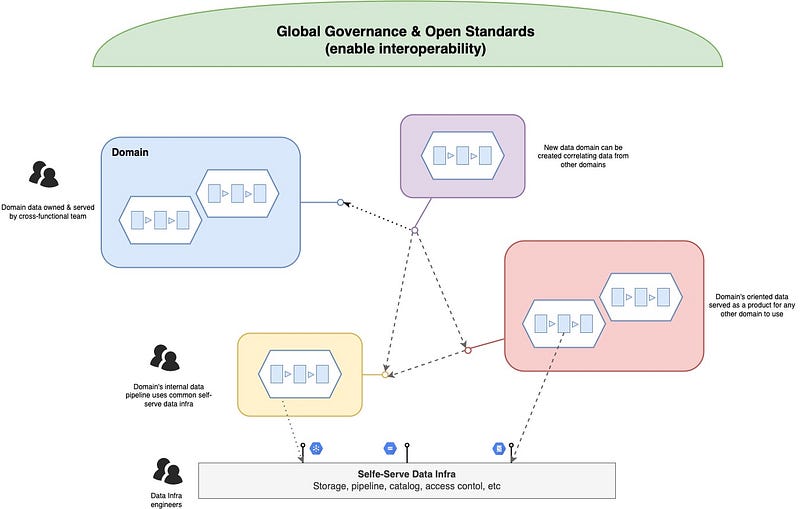
If you want to scale data practices, you need to move towards this kind of organization to support the growth of data demands. Otherwise, you will have more and more:
- Demands from your Data Analysts that don’t account for Data Infrastructures requirements.
- BI engineers who can’t maintain the Data Marts clean over the long term.
- Data Engineers who are always seen as the source of the data problems and try to ingest and expose all data in the world
- Platform engineers who are unwilling or unable to implement things because “upgrading to a centralized, monolithic Airflow instance could breaks all data workflows” (Any resemblance to an existing situation is purely coincidental).
Data Ops: To help Data platform
The part that interests me in this journey is the place and role of the platform, to support this type of organization.
With Data Mesh organization, there are a lot of roadblocks/risks that we have to go through to implement it. You need to have tools and practices that :
- Enable infrastructure as a service: To avoid a centralized, monolithic BigData Platform where all domains share everything.
- Enable data discovery and manage data lineage across domains (Data Catalog): To enable cross-domain interoperability and activate the Data Product paradigm.
- Ensure data quality and its monitoring: To proactively detect data drift and ensure Data Product quality.
- Enable a standard way of exposing data (Data visualization, Semantic layer etc.): To standardize the data domain interface and enable data usages.
- Provide self-service sandbox environment to play with data: To give Data Analysts and Data scientists secure environments, to explore and analyze production data, and accelerate the activation of production use cases.
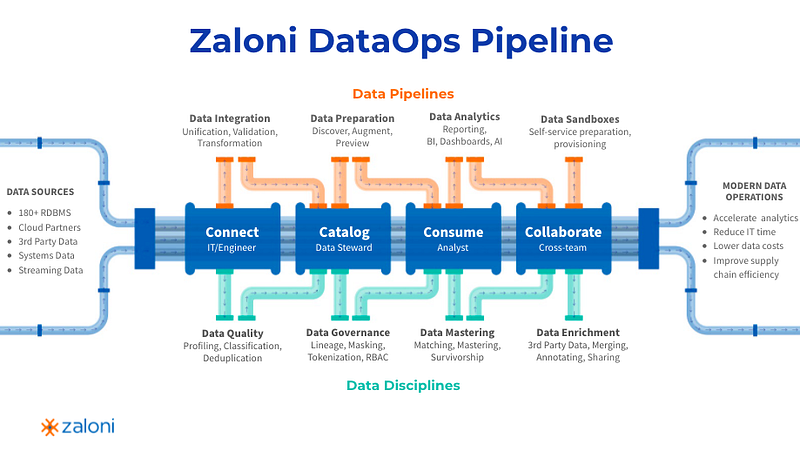
This is where the Data Ops takes place, these principles will give to teams :
- A methodogy, with guidelines to follow for managing Data Pipelines at scale (e.g when I integrate data, I must systematically ensure schema validation and deduplication)
- A set of tools that follows these principles to implement in a more integrated way my Data Pipelines.
- A set of process and best practices to use during implementation, such as being in self-service approach
Kubernetes: The infrastructure foundation
If we follow the road I’m trying to build, we have an organizational model that we want to reach with Data Mesh.
One of the key element of achieving that, is the ability of the Platform team to provide a self-service infrastructure that can meet the ambition of Data Ops.
The question is where do we put it all? The first natural response seems to be close to “the Cloud”. A lot of core functionalities are supported, as we need to enable Data Platform, on different providers (AWS, GCP, Azure etc.)
But because the goal is to support a Data organization at scale, some of the basics require more specific and less managed solutions. So you need another part in your foundation. I personally believe that the next step for data infrastructure is on the side of Kubernetes combined with the capability of a Cloud provider.
The combination of these two gives you the core functionality we need: infrastructure as a service.
With Kubernetes, you will be able to easily replicate your infrastructure across domains by simply changing some configurations, and automate most of the operational processes: from integration to production with CI/CD, and stack lifecycle with Kubernetes operators. Another important part is that within a domain, everyone works together : Data Engineers, Ops, BI Engineers, Data Analysts, Data Scientists and also Software Engineers. That means that for the Data platform and the Applications, you can be on the same infrastructure with Kubernetes, and under the same infrastructure processes.
Modern data architecture: Design
Well, now we know where we need to run our Data architecture, so let’s define the minimal modern architecture we want to build to get closer to our goal!
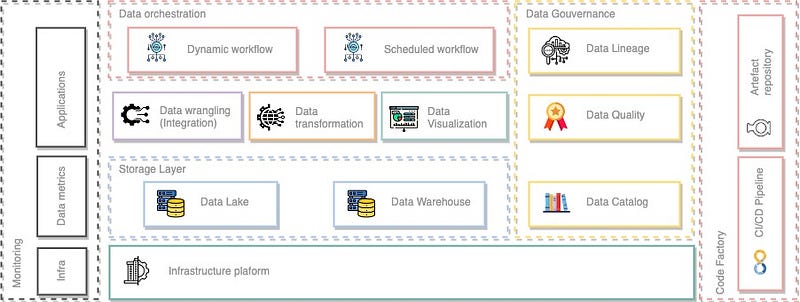
Storage layer
The where:
- Data lake: the place where we will store our data in raw format as an object.
- Data warehouse: the place where we will have our data marts, built from lineage transformations on the data.
Data management
The how:
- Data wrangling: to facilitate ingestion of data into our ELT pipelines and to enable the export of data to other domains and outside.
- Data transformation: to build our data marts, we need to implement many transformations that will consume others data marts, which involves managing dependencies between transformations, sources and destinations.
- Data visualization: a nice way to expose our data in dashboards to achieve one of the goal of this fun and complex architecture: help drive the business !
Data orchestration
The when:
- Event trigger: we need a tool that allows us to orchestrate a task graph, based on an event condition. This can be a scheduling, an internal dependency condition or an external trigger event.
- Dynamic definition: The graph must adapt according to the execution context without requiring re-implementation of a new graph, because the data pipeline doesn’t always work the same way over time, even in a batch context (e.g partial retry, conditional data state, etc.)
Data Gouvernance
The control:
Data mesh involves data gouvernance to maintain interoperability across domains and avoid context silos.
- Data Catalog: a central place to discover the data owned and exposed by the domain, which describes the data and how it is consumed.
- Data Lineage: to understand the entire lineage of the data to know how it was build and what it means.
- Data Quality: to proactively monitor and detect drift and errors in data to adapt and correct all processes impacted.
Modern Data architecture: Implementation
We are now aware of the features we need to cover in our Data platform! So let’s define the tools we will use to cover them all 😊.
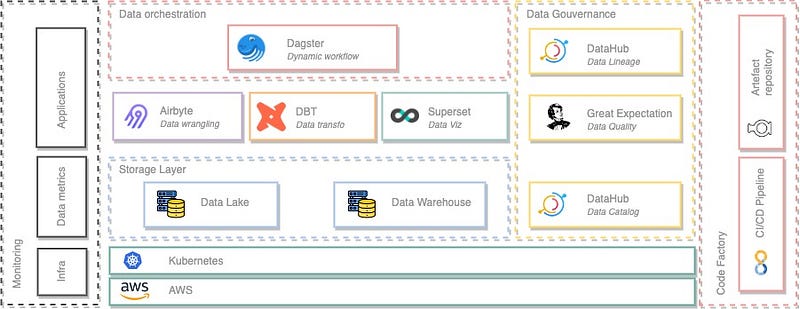
Dagster
Dagster is an orchestrator that’s designed for developing and maintaining data assets, such as tables, data sets, machine learning models, and reports.
You declare functions that you want to run and the data assets that those functions produce or update. Dagster then helps you run your functions at the right time and keep your assets up-to-date.
Dagster is built to be used at every stage of the data development lifecycle — local development, unit tests, integration tests, staging environments, all the way up to production.
Alternatives: Prefect, Argo Workflows
DBT
dbt is a transformation workflow that helps you get more work done while producing higher quality results. You can use dbt to modularize and centralize your analytics code, while also providing your data team with guardrails typically found in software engineering workflows. Collaborate on data models, version them, and test and document your queries before safely deploying them to production, with monitoring and visibility.
Alternatives: Dataform
Airbyte
Airbyte is an open-source data pipeline platform. Though existing data pipeline platforms offer a significant number of integrations with well-regarded sources like Stripe and Salesforce, there is a gap in the current model that leaves out small services integrations.
Airbyte solves this problem by building and maintaining connectors while fostering a community of users who benefit from one another’s custom connectors. It’s common practice for companies to build custom connectors to support their applications. Airbyte’s open-source model creates a community wherein companies can support one another by building and maintaining their unique connectors.
Great Expectation
Great Expectations is the leading tool for validating, documenting, and profiling your data to maintain quality and improve communication between teams.
Software developers have long known that automated testing is essential for managing complex codebases. Great Expectations brings the same discipline, confidence, and acceleration to data science and data engineering teams.
Superset
Apache Superset is a modern, enterprise-ready business intelligence web application. It is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple pie charts to highly detailed deck.gl geospatial charts.
DataHub
DataHub is a modern data catalog built to enable end-to-end data discovery, data observability, and data governance. This extensible metadata platform is built for developers to tame the complexity of their rapidly evolving data ecosystems and for data practitioners to leverage the total value of data within their organization.
Alternatives: Amundsen
Conclusion
This post, serve as a sort of compass to guide our discovery and testing of the modern architecture.
In the next part, we will experiment all the technologies by adding bricks one after the other, trying to understand what they can offer in relation to the current data architecture and how they can help us with our modern challenges.
Once we are done building our PoC Data Platform, we will move on to production implementation to test the architecture and solution at scale!
It will be a long and exciting journey!
Next post: Dagster on kubernetes





