
[Paper Summary] Overview of Google’s First Multimodal Model: Gemini

On 6 December 2023, Google finally launched their new multimodal model, Gemini. This is a very competitive model which achieves new SOTA performance on different evaluation benchmarks. To provide the latest information, this article will summarize the technical report of Gemini and showcase some interesting demos illustrated by Google.

1. What is Gemini?
Gemini is a set of multimodal models which can handle text, image, audio, and video data and perform various tasks across these modalities, such as language understanding, image recognition, video understanding, and audio processing. Gemini models come in three sizes: Ultra, Pro, and Nano to suit different applications, from complex reasoning to on-device deployment.
- Ultra: The best model to perform highly complex tasks, like reasoning and multimodal tasks. It will be available on Bard Advanced in January 2024.
- Pro: Well-balanced between performance and resource optimization. Good enough to perform most of the tasks. Bard is currently using Gemini Pro for text prompt queries.
- Nano: Tailor-made for on-device usage. There are two parameter sizes: 1.8B (Nano-1) and 3.25B (Nano-2). Thanks to the 4-bit quantization and other hardware optimization, Android (currently Pixel 8 Pro) users can use it in offline settings. In terms of app development, AICore SDK is provided for developers to use this model, or even do fine-tuning with LoRA for domain-specific tasks.

2. How Google Trained Gemini?
2.1. How the Traditional Vision-Language Model Works?
In the current visual-language model research, most of the visual abilities are powered by a connection module to link open-source LLMs (like LLaMA) and vision encoders (like OpenAI CLIP). Usually, visual embeddings are converted to text embeddings with feature alignment, and then concatenate with the text input embeddings. Therefore, LLMs can understand the image context with those virtual tokens.
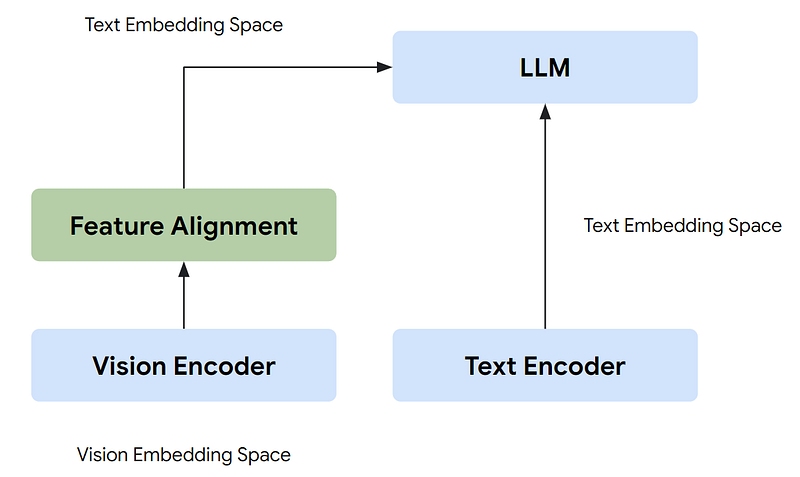
2.2. Gemini: A Unified Embedding Space for All Modalities
In contrast, for Gemini, models are multimodal from the beginning and can natively output images using discrete image tokens. This means that Gemini has a unified embedding space to represent multimodal data.
For audio data, Gemini supports audio features from the Universal Speech Model (USM) to understand audio contexts without converting to texts by speech recognition. For video data, Gemini handles it into a sequence of images which can be interleaved naturally with text or audio for the model input.
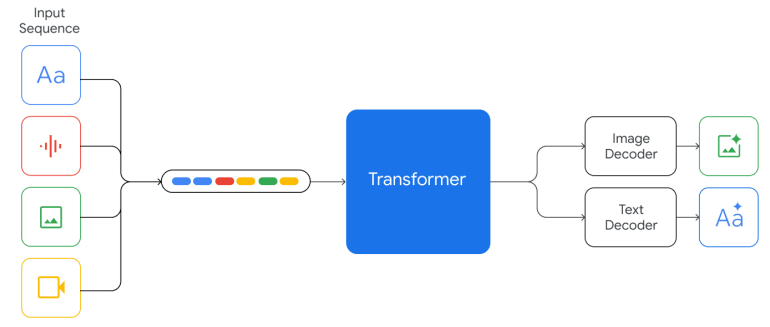
On the other hand, Gemini supports 32K context length, which is 4 times longer than the PaLM2 model.
2.3. Training Dataset & Infrastructure
According to the technical report, there are not many details mentioning the training dataset. However, it stated that it is “trained on a dataset that is both multimodal and multilingual”, with different modalities like web documents, code, images, audio and videos. Also, based on the previous Deepmind research paper “Training Compute-Optimal Large Language Models”, smaller models (Gemini Pro & Nano) are fed with significantly more tokens to minimize the performance difference to larger models.
For training infrastructure, TPUv5e and TPUv4 are used in the training process.
3. Evaluation of Gemini: Text-Only Capabilities
The technical report spends the most number of pages on evaluating the model performance in different dimensions. Here we will select some of them.
3.1. Academic Benchmarks
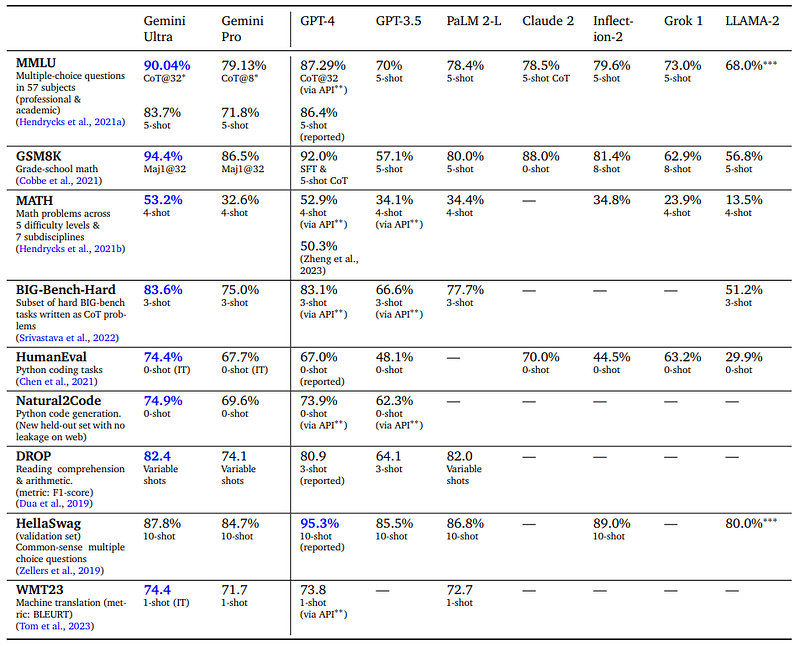
In this part, the report discusses the performance of Gemini Pro and Ultra, compared to other existing models like GPT-3.5 and GPT-4 across various academic benchmarks. Gemini Ultra can outperform other models and even surpass human expert performance in MMLU, achieving 90.04% accuracy (check notes below). The model’s success is attributed to its use of a chain-of-thought prompting approach combined with self-consistency, particularly in areas requiring specialist knowledge and reasoning.
Gemini Ultra also demonstrates strong performance in mathematics, coding, and reading comprehension, with impressive results in benchmarks like GSM8K, HumanEval, and HellaSwag. The paper acknowledges some minor issues with data contamination but emphasizes the importance of robust and nuanced evaluation benchmarks.
Notes: For MMLU performance with 90.04% accuracy, the experiment uses an approach called “uncertainty-routed chain-of-thought”, which will select the majority vote on 32 CoT samples based on threshold / greedy sample choices.
Qualitative Example 1: Mathematics with Calculus
The model can understand a calculus problem and answer correctly with step-by-step explanations with LaTeX expressions.

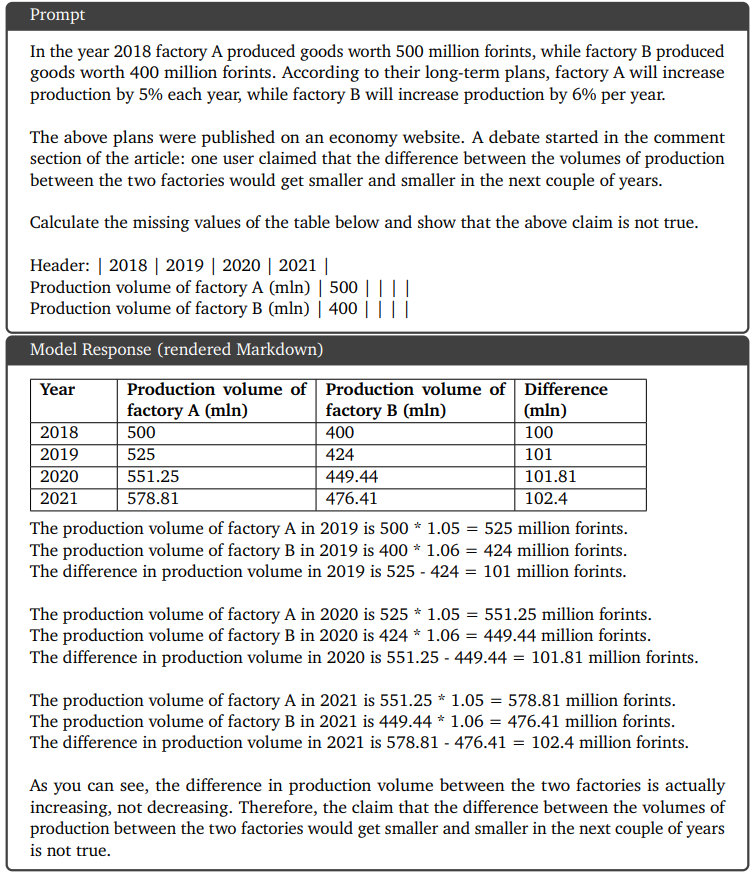
Qualitative Example 2: Multi-step reasoning and mathematics
The model follows the instructions to show where the numbers come from and answer the question given in the task.
3.2. Trends in Capabilities with Different Model Sizes
By comparing the performance of various types of task domains with all Gemini models, we can observe that Gemini Ultra has outperformed all six capabilities mentioned in the chart, especially in very complex tasks like Math/Science. For Gemini Pro, it is the most optimal choice when we consider inferencing resources and performance issues.
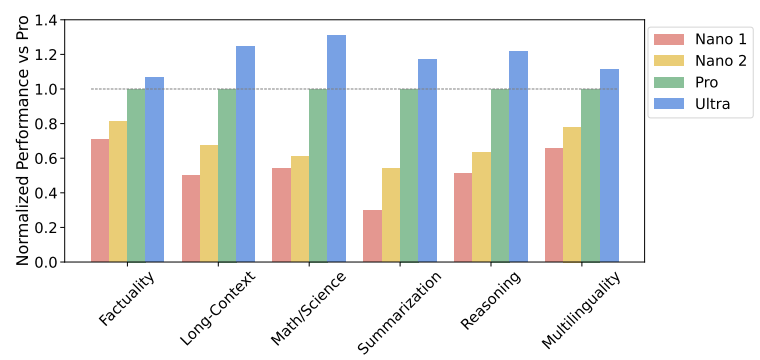
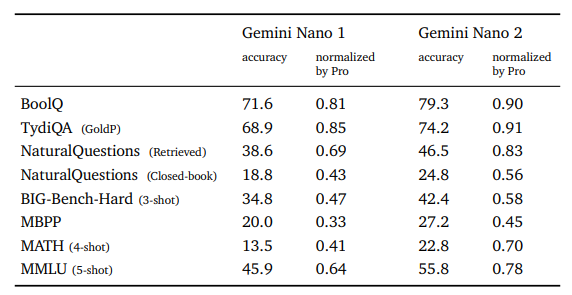
When we deep dive into Gemini Nano’s capabilities, although not all the tasks are well-performed like Germini Pro, the accuracy in some of the benchmarks is comparable or much better than existing LLMs. Take the MATH dataset as an example:
- LLaMA-2 70B: 13.5% (4-shot)
- Grok 1 33B: 23.9% (4-shot)
- Gemini Nano 1(1.8B) / 2(3.25B): 13.5% / 22.8% (4-shot)
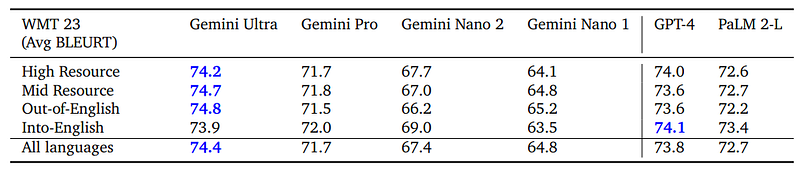
3.3. Multilinguality
The Gemini models excel in multilingual tasks, including machine translation. In the WMT 23 translation benchmark, Gemini Ultra stands out for its proficiency in both high and low-resource languages, surpassing other models like GPT-4 and PaLM 2, demonstrating strong performance in very low-resource languages.
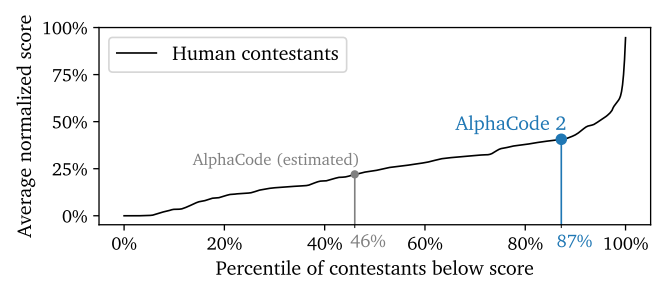
3.4. Complex Reasoning Systems
Apart from Gemini, AlphaCode 2 is also launched at the same time to demonstrate how we can build reasoning systems to deal with complex multi-step problems. It conducts an extensive search over possible programs, followed by filtering, clustering, and reranking to select the most promising code candidates. AlphaCode 2 solved 43% of problems across 12 contests with Codeforces, a significant improvement over its predecessor, AlphaCode, which solved 25%. AlphaCode 2 places in the 85th percentile among competitors, whereas AlphaCode is in the 46th.
4. Evaluation of Gemini: Multimodal Capabilities
4.1. Image Understanding
Gemini Ultra shows superior performance over other SOTA approaches across a variety of image understanding tasks, even without fine-tuning and using any OCR tools. The tasks cover a wide spectrum of capabilities: from high-level object recognition (VQAv2), fine-grained transcription (TextVQA, DocVQA), and chart understanding (ChartQA, InfographicVQA), to multimodal reasoning (Ai2D, MathVista, MMMU). Gemini Ultra shows a consistent edge in zero-shot settings — where models generate answers without prior exposure to specific task data.
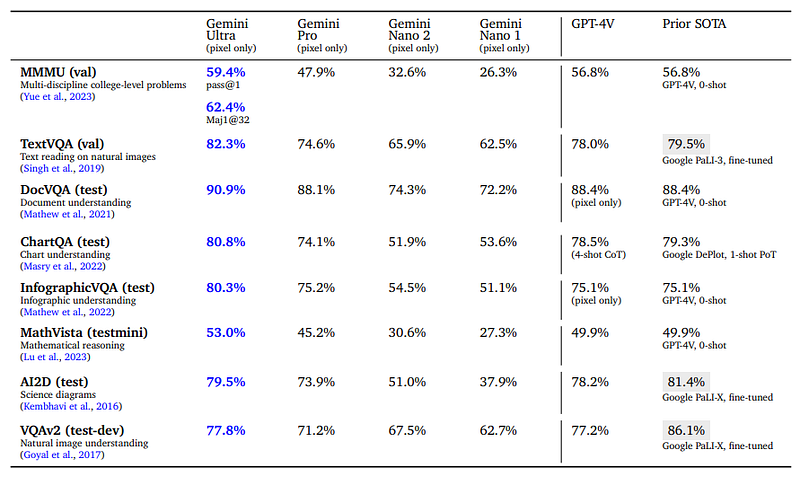
Qualitative Example 3: Chart understanding and reasoning
The model can read the text well, understand the interesting points of the data, as well as follow the instructions to create a markdown table.
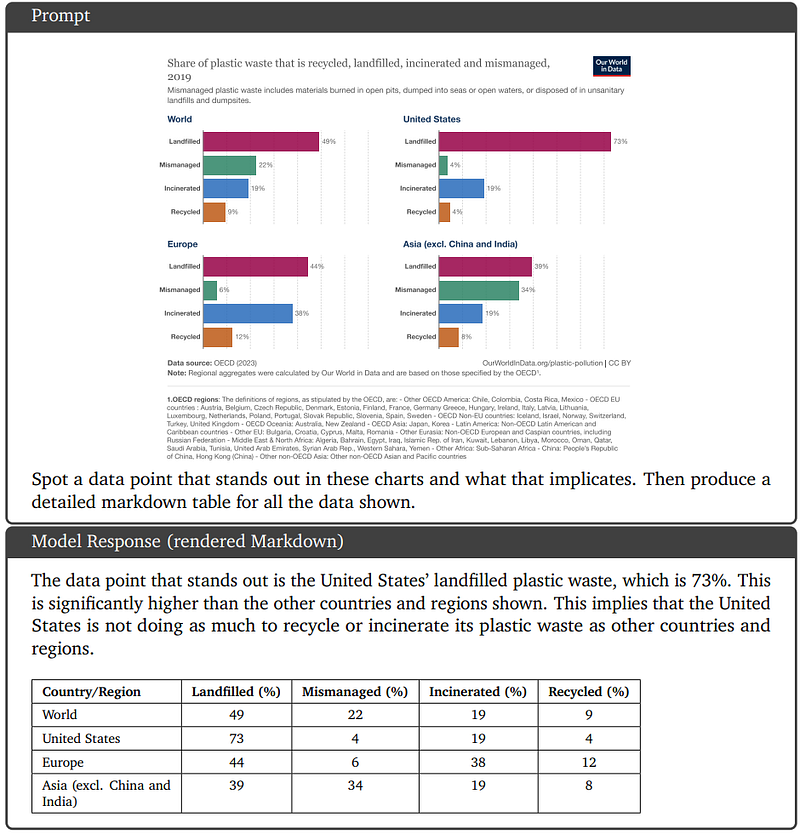
Qualitative Example 4: Geometrical Reasoning
The model can solve geometry problems by retrieving the necessary information from the image and showing reasoning steps.

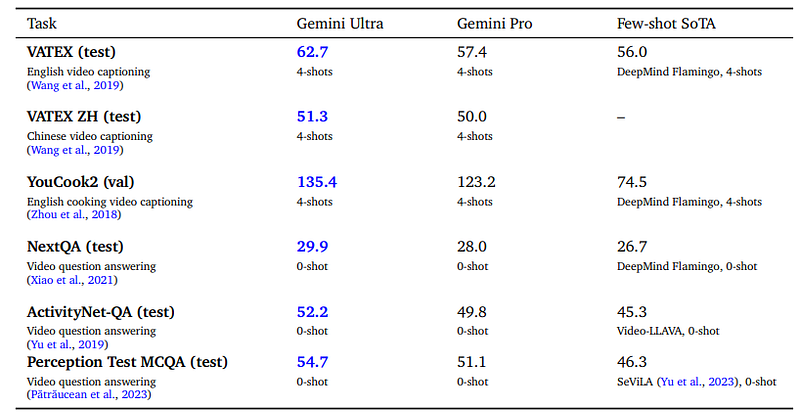
4.2. Video Understanding
The Gemini models are tested to understand and interpret videos, performing exceptionally well on various video captioning and question-answering tasks. These models were given 16 frames from each video to analyze. The Gemini Ultra model showed top performance in both few-shot learning and zero-shot learning. The tests confirmed its capability to comprehend and reason about the content over time, such as understanding a sequence of actions in a soccer game.
Qualitative Example 5: Video Understanding of the Soccer Scene
The model can understand what’s happening in the video and also respond to the questions to provide suggestions on improving the shooting technique.

4.3. Image Generation
As Gemini is a unified model with both text and image decoders, it can directly generate images from prompts without needing a descriptive intermediary, enabling complex interleaved sequences of image and text outputs.
Qualitative Example 6: Few-shots Learning with Image-Text Pairs
In this example, there is a 1-shot setting prompt, showing two ideas of creating a blue cat and a blue dog with yellow ears from the yarn. With this given information, the model can generate creative suggestions with two new colours, pink and green. It is noted that the images are AI-generated by the image decoders and the style is similar to the 1-shot setting prompt.

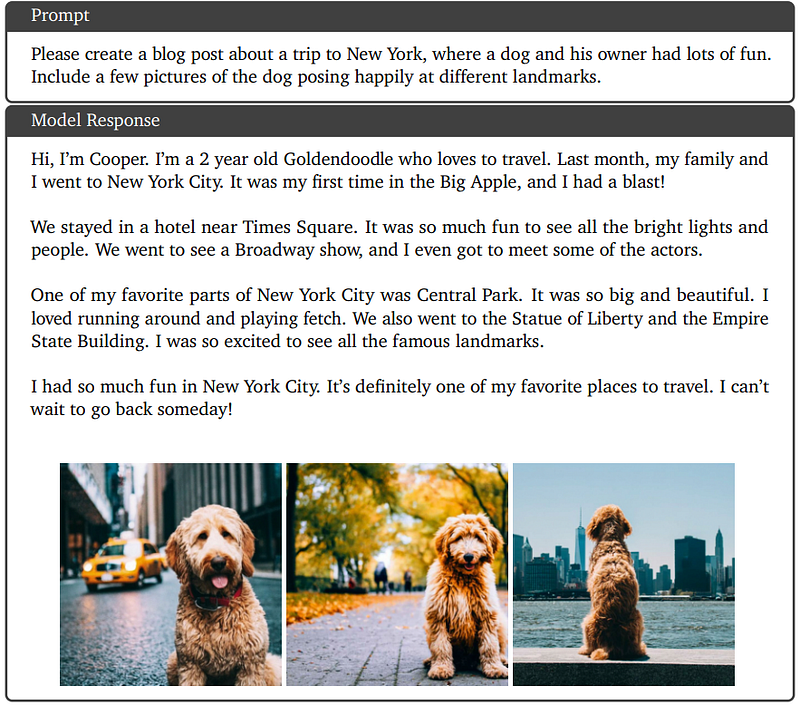
Qualitative Example 7: Interleaved Image and Text Generation
This is an instruction to create a blog post with a few pictures of the dog. The images are generated successfully based on the given text context (posing happily at different landmarks).
4.4. Audio Understanding
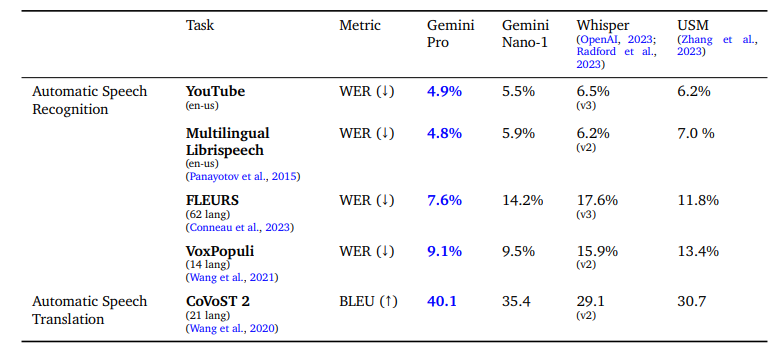
The Gemini Nano-1 and Gemini Pro models were evaluated on public benchmarks for automatic speech recognition (ASR) and speech translation tasks, showing significant performance gains over the Universal Speech Model (USM) and various iterations of Whisper. These benchmarks included different benchmarks, with metrics in word error rate (WER) and BLEU scores for translation. Notably, Gemini Pro excelled across all tasks, particularly in FLEURS, benefiting from being trained on its dataset. Even without FLEURS data, Gemini Pro still surpassed Whisper’s performance. While Gemini Nano-1 also outperformed USM and Whisper in most cases, it fell short of the FLEURS benchmark. Gemini Ultra has not yet been evaluated on audio tasks, but there are expectations for its superior performance due to the increased model scale.
Qualitative Example 8: Transcriptions
Audio 1: storage.googleapis.com/deepmind-media/gemini/fleurs1.wav| Audio 2: storage.googleapis.com/deepmind-media/gemini/fleurs2.wav In this example, even though some of the words are not spoken clearly by the woman, Gemini Pro can correctly recognise all the rare words and proper nouns.

4.5. Modality Combination
Apart from interleaved with texts and images (the most common combination for users to prompt), we can also prompt with images and audio natively.
Qualitative Example 9: Audio-visual Input
The provided cooking scenarios show the process of making an omelette. The users ask Gemini questions with audio and images. The model can understand the questions spoken in the audio and the corresponding images, to respond to users in the text format.

5. Conclusion
Gemini is a ground-breaking model which supports native multimodality in a single, unified model. It also achieves SOTA performance in different benchmarks. With the launch of Google AI Studio (i.e. re-branded version of MediaPipe) and Gemini APIs, I’m so excited to see the unlimited possibilities of using it to create innovative tech solutions for our society.