
Paper explained: Masked Autoencoders Are Scalable Vision Learners
How reconstructing masked parts of an image can be beneficial
Autoencoders have a history of success for Natural Language Processing tasks. The BERT model started masking word in different parts of a sentence and tried to reconstruct the full sentence by predicting the words to be filled into the blanks. Recent work has aimed to transfer this idea to the computer vision domain.
In this story, we will have a look at the recently published paper “Masked Autoencoders Are Scalable Vision Learners” by He et al. from 2021. Kaiming He is one of the most influential researchers in the field of computer visions, having produced breakthroughs such as the ResNet, Faster R-CNN and Mask R-CNN along with other researchers at Meta AI Research. In their latest paper, they presented a novel approach for using autoencoders for self-supervised pre-training of computer vision models, specifically vision transformers.
Before we dive deeper into the method presented by them, it is important that we quickly revisit self-supervised pre-training to set the context right. If you are already familiar with self-supervised pre-training, feel free to skip this part. I’ve tried to keep the article simple so that even readers with little prior knowledge can follow along. Without further ado, let’s dive in!
Pre-requisites: Self-supervised pre-training for computer vision
Before we go deeper into the paper, it’s worth quickly re-visiting what self-supervised pre-training is all about. If you are familiar with self-supervised pre-training, feel free to skip this part.
Traditionally, computer vision models have always been trained using supervised learning. That means humans looked at the images and created all sorts of labels for them, so that the model could learn the patterns of those labels. For example, a human annotator would assign a class label to an image or draw bounding boxes around objects in the image. But as anyone who has ever been in contact with labeling tasks knows, the effort to create a sufficient training dataset is high.
In contrast, self-supervised learning does not require any human-created labels. As the name suggest, the model learns to supervise itself. In computer vision, the most common way to model this self-supervision is to take different crops of an image or apply different augmentations to it and passing the modified inputs through the model. Even though the images contain the same visual information but do not look the same, we let the model learn that these images still contain the same visual information, i.e., the same object. This leads to the model learning a similar latent representation (an output vector) for the same objects.
We can later apply transfer learning on this pre-trained model. Usually, these models are then trained on 10% of the data with labels to perform downstream tasks such as object detection and semantic segmentation.
Use masking to make autoencoders understand the visual world
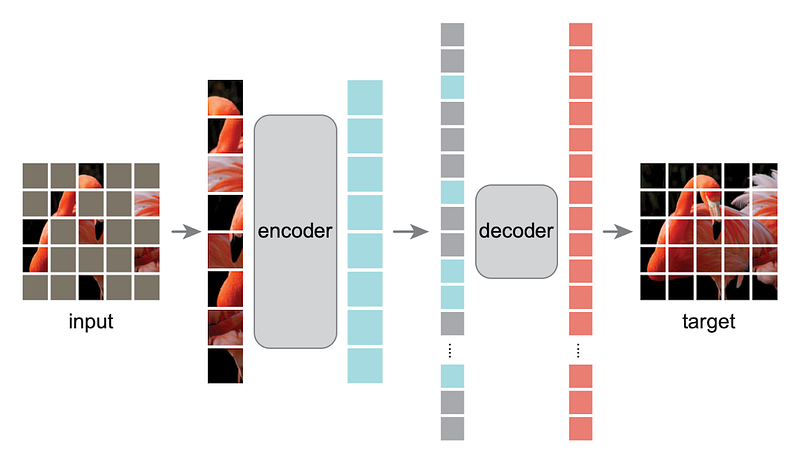
A key novelty in this paper is already included in the title: The masking of an image. Before an image is fed into the encoder transformer, a certain set of masks is applied to it. The idea here is to remove pixels from the image and therefore feed the model an incomplete picture. The model’s task is to now learn what the full, original image looked like.

The authors found a very high masking ratio to be most effective. In these examples, they have covered 75% of the image with masks. This brings along two benefits:
- Training the model is 3x faster since it has to process much fewer image patches
- The accuracy increases since the model has to learn the visual world from the images thoroughly
The masking is always applied randomly, so multiple versions of the same image can be used as input.
Now that the images have been pre-processed, let’s have a look at the model architecture. In their paper, He et al. decide on using an asymetric encoder design. That means their encoder can be much deeper and while they opt for a rather lightweight decoder.
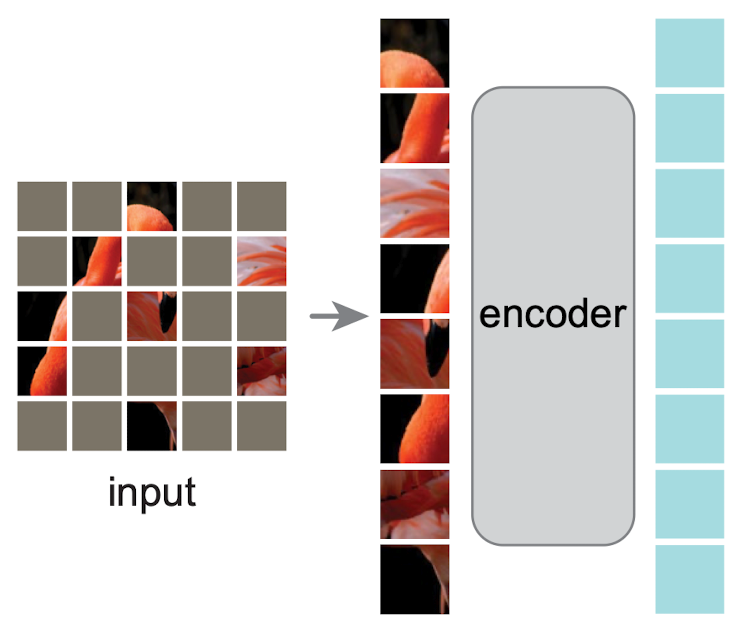
The encoder divides the image into patches that are assigned positional encodings (i.e. the squares in the images above) and only processes the non-masked parts of the image. The output of the encoder is a latent vector representation of the input image patches.
Following this, the mask tokens are introduced since the next step is for the decoder to reconstruct the initial image. Each mask token is a shared, learned vector that indicates the presence of a missing patch. Positional encodings are again applied to communicate to the decoder where the individual patches are located in the original image.
The decoder receives the latent representation along with the mask tokens as input and outputs the pixel values for each of the patches, including the masks. From this information, the original image can be pieced together to form the predicted version of the full image from the masked image that served as the input.
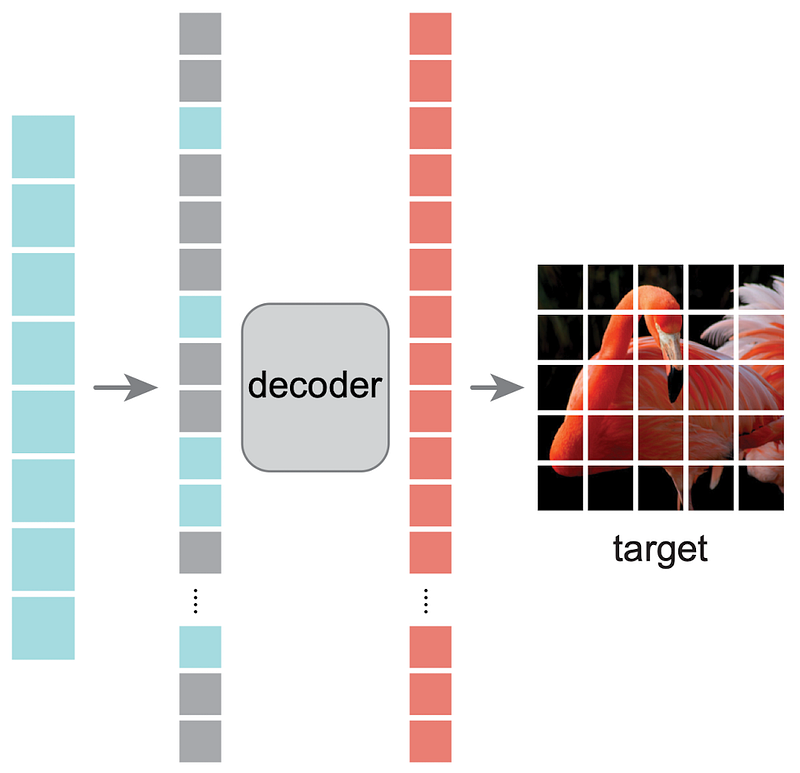
Adding the mask tokens after the computation of the latent vector in blue is an important design decision. It reduces the computational cost of the encoder arriving at the vector output since it has to process less patches. This makes the model faster during training.
Once the target image has been reconstructed, it’s difference to the original input image is measured and used as the loss.

After the model has been trained, the decoder is discarded and only the encoder, i.e., the vision transformer, is kept for further use. It is now capable of computing latent representations of images for further processing.
Now that we have gone over the methodology introduced by the paper, let’s look at some results.
Results
Since the masked autoencoder makes use of transformers, it makes sense for the authors to compare its performance to other transformer-based self-supervised methods. An their improvement show in the first comparison:
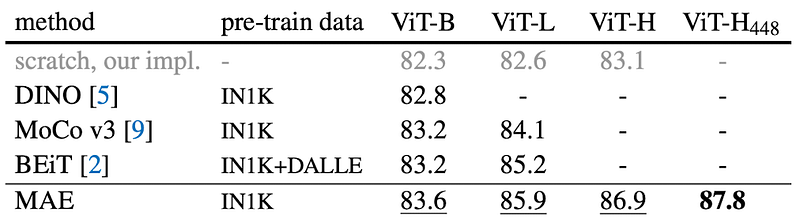
In their comparisons with other methods, when pre-training the model on ImageNet-1K and then fine-tuning it end-to-end, the MAE (masked autoencoder) shows superiors performance compared to other approaches such as DINO, MoCov3 or BEiT. The improvements stay steady even with increasing model size, performance is the best with a ViT-H (Vision Transformer Huge). MAE achieves an incredible accuracy of 87.8.
This performance holds true for transfer learning on downstream tasks as well:
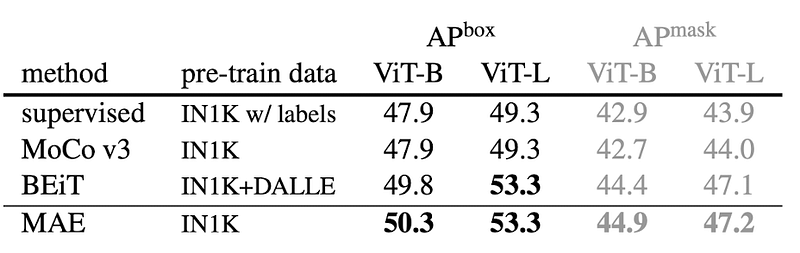
When using the pre-trained transformer as a backbone for a Mask R-CNN that trained on the MS COCO detection and segmentation dataset, the MAE again outperforms all other transformer-based methods. It achieves an incredible 53.3 AP (average precision) for the boxes. The Mask R-CNN also outputs a segmentation mask of the object. For this evaluation, the MAE again tops all other methods with up to 47.2 AP for the mask. The method even outperforms fully-supervised training of the Mask R-CNN, again showing the benefit of self-supervised pre-training.
Wrapping it up
In this article, you have learned about masked autoencoders (MAE), a paper that leverages transformers and autoencoders for self-supervised pre-training and adds another simple but effective concept to the self-supervised pre-training toolbox. It even outperforms fully-supervised approaches on some tasks. While I hope this story gave you a good first insight into the paper, there is still so much more to discover. Therefore, I would encourage you to read the paper yourself, even if you are new to the field. You’ll have to start somewhere ;)
If you are interested in more details on the method presented in the paper, feel free to drop me a message on Twitter, my account is linked on my Medium profile.
I hope you’ve enjoyed this paper explanation. If you have any comments on the article or if you see any errors, feel free to leave a comment.
And last but not least, if you would like to dive deeper in the field of advanced computer vision, consider becoming a follower of mine. I try to post a story once a week and and keep you and anyone else interested up-to-date on what’s new in computer vision research!
References:
[1] He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” arXiv preprint arXiv:2111.06377 (2021). https://arxiv.org/pdf/2111.06377.pdf





