
Padding and Strides in CNN

In Convolutional Neural Networks (CNNs), padding and strides are important concepts that determine how the convolution operation is applied to an input, affecting the output size and how features are extracted. Padding refers to the process of adding extra pixels (usually zeros) around the border of the input image. And strides refer to the number of pixels by which the filter (or kernel) moves or slides across the input image.
Let’s see a convolutional operation.

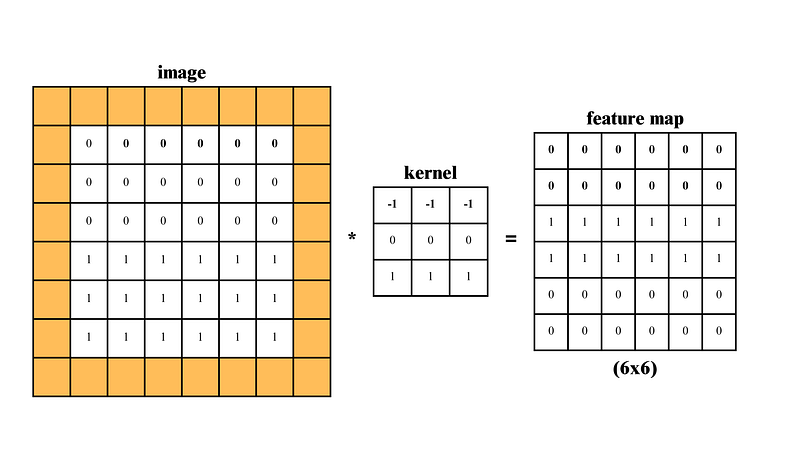
Here, we see an image of (6x6) size, a kernel of (3x3) size producing (4x4) size of feature map. In this feature map, we are getting some edges, it looks so cool.
But there are 2 problems.
1. The feature map (4x4) that we are getting is smaller than the original image (6x6). We have to use multiple layers in the neural network. So, the more layer we will use, the smaller will be our feature map.
Only the middle part of the image will get more importance, but the side part of the image will get less importance.
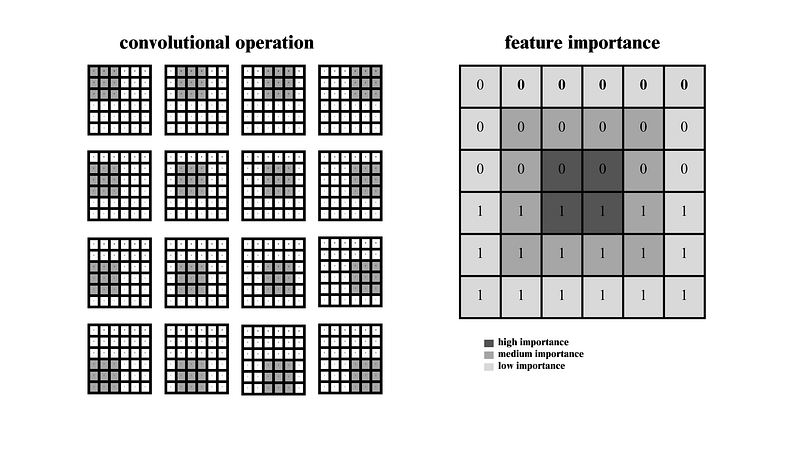
Padding basically solves both problems.
We know that for an input image of shape (n x n) and a kernel of shape (f x f), the resulting feature map will have a shape of ((n-f+1) x (n-f+1)). If we don’t want to reduce the size of the feature map, we need to adjust the input image size accordingly. To maintain the same size as the input, the equation (n-f+1 = n) must hold.
For example, if we want the feature map to have a size of (6 x 6), we solve for (n) in (n-f+1 = 6). Assuming (f = 3), this gives us (n = 8), meaning the input image should be (8 x 8).
Padding helps us achieve this by adding extra rows and columns to the input image, effectively adjusting its size to ensure that the feature map’s dimensions do not decrease. This way, we can maintain the desired shape throughout the convolution process.
Let’s see an example.
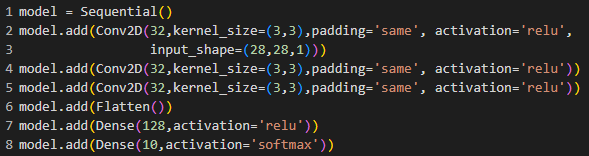
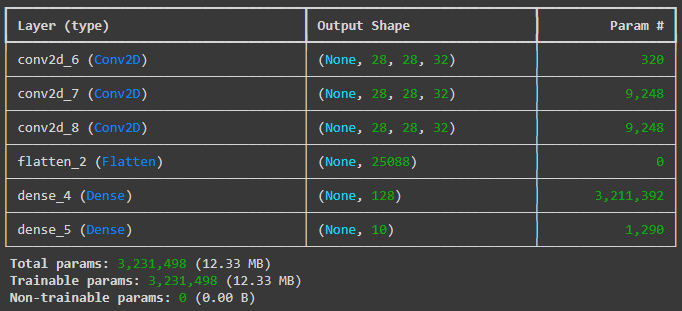
When we do code, we will get two types of padding option in Keras. Those are “valid” and “same”.
Valid means it won’t apply padding in the operation.
Same means it will apply padding in the operation.
Let’s see in code. If we select padding = “valid”. Means no padding will apply during the operation.
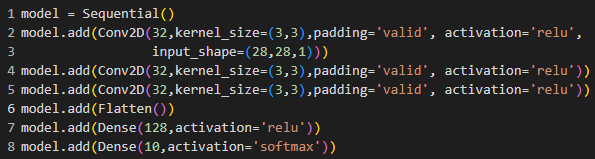
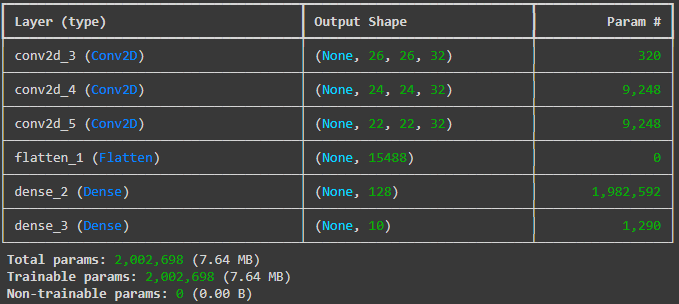
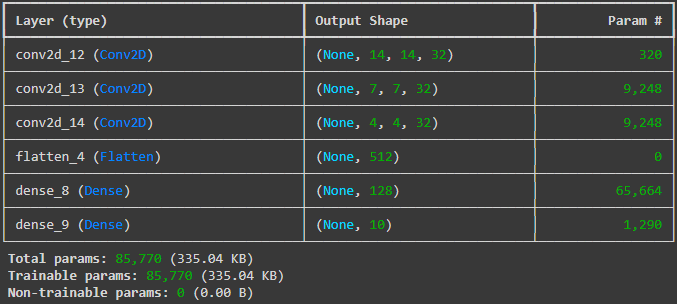
We see that the output shape is becoming smaller after the operations.
Now we will code padding = “same”. That means it will apply padding and the feature shape won’t decrease.
Now let’s discuss about Strides.
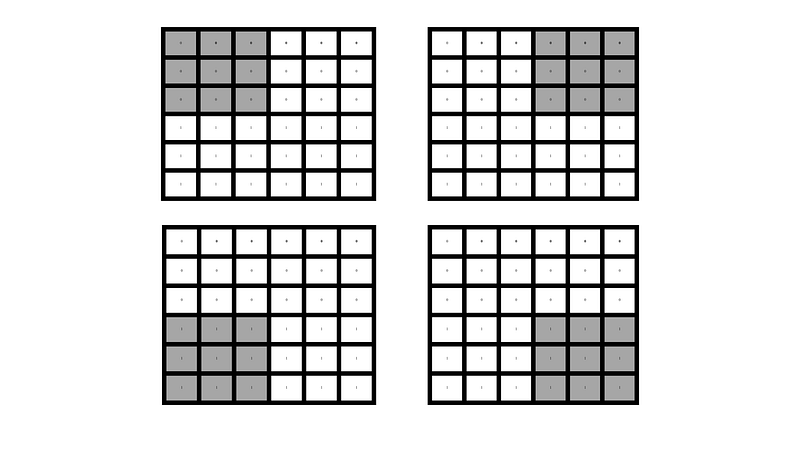
Strides basically indicate the “jumping of kernels”. In convolution operation, the kernel moves into one box on the right side after an operation is complete. But we can specify how many boxes it will exclude in every jumping.
When we specify stride = 1, the convolution operation works like that.
If we specify stride equals to 2, the convolutional operation works like that.

If we specify stride equals to 3, the convolutional operation will work like that.
Why do we use striding?
1. In some projects you don’t need to extract all features from input datasets. You just need to extract high level features. In those cases, we need to use striding, because it specify the jump of the kernel, the more striding will be applied, the more low level feature will be ignored.
2. Sometimes we have limited computing resources with comparison of the size of the datasets. The more striding will be applied, the more high-level feature it will extract, the less computing resource will be needed. Also, the time will decrease.
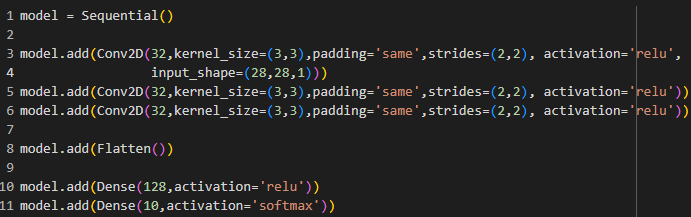
Let’s see in code. In this code, we have specified strides equal to 2. We see that the output shape is reducing drastically in every layer.
Padding and strides are key components in the design of Convolutional Neural Networks, influencing both the output size and the detail captured from the input data. By adjusting these parameters, we can control how much spatial information is retained or reduced, tailoring our model to fit the specific requirements of our task. Whether we aim to preserve the full resolution of our input or focus on extracting broader patterns, understanding and effectively using padding and strides will help us create more efficient and effective neural network architectures.





