
OTHER ML JARGONS
Other ML Jargons: Sparse and Dense Representations of Texts for Machine Learning
A Brief Introduction to Vectorization and its Importance in the Context of NLP

Introduction
Matrices and vectors are quantified information that Machine Learning(ML) algorithms require for learning patterns and making predictions. For applying these techniques to textual data as well, numeric representations of the texts are engineered to form matrices that hold the relevant information from those texts. The concepts of “Sparsity” and “Density” arrive at efficiently designing and constructing these matrices for all high-dimensional data processing use-cases in the world of Artificial Intelligence.
Significance of Vector Representations for NLP
Representing text data as vectors are necessary for applying Machine Learning techniques to make predictions, recommendations, or clusters. In NLP, the concept of “similar words occur in similar contexts” is fundamental. Let’s see how:
- In Text Classification use-cases like categorizing support tickets, spam detection, fake news detection, and feedback sentiment analysis, texts having similar words are classified into a particular category.
- In Recommendation Systems, people with similar profile details, browsing history, and past orders indicate similar choices or tastes in products. This information is used to make recommendations.
- Unsupervised Clustering looks for patterns and similar words in the texts to group documents and articles. Typical applications include segregating news articles, trend analysis, and customer segmentation.
- In Information Retrieval systems, indexed documents are matched with queries, sometimes in a “fuzzy” way and the collection of matched documents is returned to the user. Besides, the measure of similarity is used to rank the search.
Hence, capturing similarities in these vectors is a primary research area in the NLP domain. These vectors are projected in an N-dimensional plane and then patterns in these vectors in the N-dimensional space are extracted to categorize the texts. Sometimes, dimensionality reduction techniques are applied, like PCA or t-SNE. The design of the vectors controls the overall performance of text-based ML models and is, hence, crucial.
The vector designs are broadly classified as “Sparse” (meaning scarcely populated) and “Dense” (meaning densely populated) vectors. In this article, I have recalled the concepts of matrices and vectors from a mathematical perspective, and then discussed these two classes of vectorization techniques — sparse vector representations and dense vector representations. including a demo using Scikit Learn and Gensim, respectively. I have also concluded this article with an overview of the applications and usability of these representations.
A Primer to Matrices and Vectors
Mathematically, a matrix is defined as a 2-dimensional rectangular array of numbers. If the array has m rows and n columns, then it is a matrix of size m × n.
If a matrix has only one row OR only one column it is called a vector. A 1×n matrix or vector is a row vector (where there are n columns but only 1 row) and an m × 1 matrix or vector is a column vector (where there are m rows but only 1 column). Here’s an image that clearly demonstrates this:
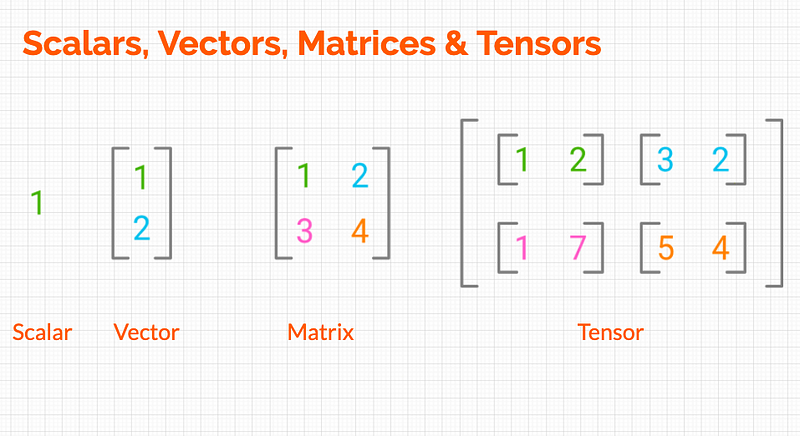
Here’s a primer for scalars, vectors, and matrices and an Introduction to Vectors and Matrices using Python for Data Science.
Sparse Representations | Matrices | Vectors

In almost all real-world cases, the count-based quantified numeric representation of information is sparse in nature, in other words, the numeric representation contains only a fraction that is useful to you in an ocean of numbers.
It is because, intuitively, in a collection of documents, only words that are articles, prepositions, conjunctions, and pronouns are overtly used and therefore, have a higher frequency of occurrence. However, in a collection of sports news articles, the terms ‘soccer’ or ‘basketball’, occurrences of which would help us determine which sport is the article associated with, occurs only a few times but is not of a very high frequency.
Now, if we construct a vector per new article, assuming there are 50 words per article, the word ‘soccer’ would occur about 5 times. Hence, 45 out of 50 times, the elements in the vector will be zero, which indicates the absence of the word we are focusing on. Therefore, 90% of the vector of length 50 is redundant. This is an example of a one-hot vector generation.
Another typical example of sparse matrix generation is the Count Vectorizer which determines how many times a word has occurred in a document. It generates a matrix of “count vectors” per document to constitute a matrix of size d × v where d is the number of documents and v is the number of words or vocabulary in the collection of documents.
Here’s a demonstration of how a Count Vectorizer works:
Below are four different meanings of the word ‘demo’, each of which represent one document ~
Document 1: a demonstration of a product or technique
Document 2: a public meeting or march protesting against something or expressing views on a political issue
Document 3: record a song or piece of music to demonstrate the capabilities of a musical group or performer or as preparation for a full recording
Document 4: demonstrate the capabilities of software or another product
I used Scikit Learn’s CountVectorizer implementation to generate this sparse matrix for these four “documents”. Below is the code I have used 👩💻
The output of _cv.toarray() is of the numeric representation of the words in a 4 × 34 array (converted using .toarray() from the vector) as in the screenshot below:

In the matrix:
- zero represents no occurrence at all (basically no information)
- anything more than zero is the number of times the word has occurred in the four documents (some useful and some redundant information).
- 34 is the size of the vocabulary (or the total number of unique words in the documents), hence the shape is 4 x 34.
The simplest measure of sparsity is the fraction of the total number of zeroes over the total number of elements, in this case ~
- Number of zeros = 93
- Number of elements in the array = 4 × 34 = 136
Therefore, more than 50% of the array has no information at all (93 out of 136), yet it is a high-dimensional matrix that needs more memory (increased Space complexity) and computation time (increased Time complexity). If a machine learning model is fed with this high-dimensional data, it will find it difficult to
- find patterns
- will be far too expensive to tune weights for all the dimensions
- it will eventually lead to latency issues during prediction time
Sparsity is analogous to the concept of the curse of dimensionality. Recommender systems and collaborative filtering techniques, count-based data representations including the famous TF-IDF are prone to issues related to the sparsity of textual data.
Dense Representations | Matrices | Vectors

The way out? A representation that has more information and less redundancy, is mathematically defined as a matrix or a vector where most elements are non-zero. Such data representations are called dense matrices or dense vectors. They are also usually smaller in size than sparse matrices.
Advantages of using Dense Vectors for Machine Learning
- Smaller the dimension, the faster and easier to optimize weights for ML models
- Even though dense vectors could have smaller dimensions than sparse matrices, they could also be large enough to challenge computational infrastructures (imagine Word2Vec or BERT-based representations), but still would contain rich and useful information like syntactical, semantical, or morphological relationships.
- They generalize relationships between textual elements better which is clearly demonstrated by the success of word2vec algorithms
Common NLP techniques for transforming sparse to dense representations:
- Word2Vec: It is one of the most popular schools of algorithms that learns dense representation using shallow Neural Networks (NN) while trying to predict the probable word(s) and capture semantic relations.
- FastText: Another algorithm with the same objective using shallow NNs, except that FastText character-level n-grams. However, Word2Vec has been noted to work best for English but FastText is better for morphologically rich languages like Arabic, German, and Russian. Besides, it captures syntactic features better than semantic ones.
- GloVe: Again same! Learns dense representation but based on probability of co-occurrence.
Here is a compact demo of how to obtain dense representations using Gensim’s word2vec algorithm.
Below is the dense representation of the word ‘demonstration’ of length 10 (note the value of vector_size argument for word2vec model is 10). Note how there are no zeros in this numeric representation.
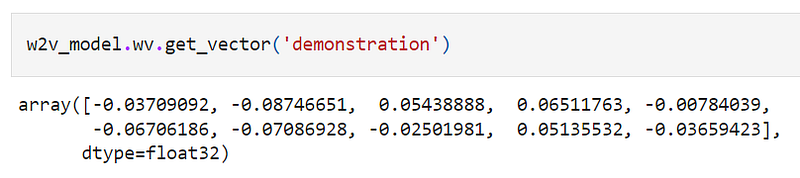
Usually, the higher the vector size, the better the knowledge captured, especially semantic information. These are extremely useful for assessing text similarities and in unsupervised techniques for text processing.
Also, below is a snapshot of the dense vectors obtained for each word in our first document “a demonstration of a product or technique” appended in a list, corresponding to the sequence of occurrence within the document. This time I did not clean and kept the texts as is, hence there are seven word-vectors in the list:
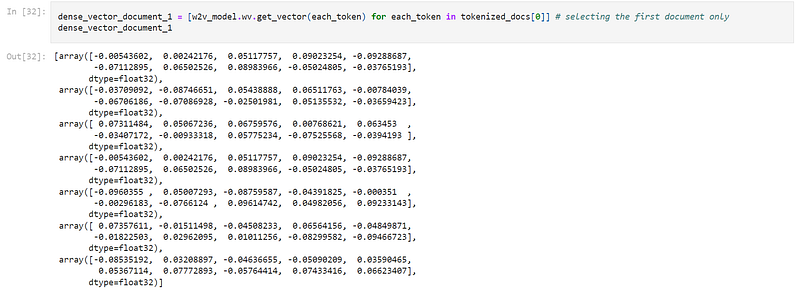
Dense vectors like these could also be pre-trained on a large corpus, usually made available to be accessed online. Imagine a dictionary with, as usual, an index of all the unique words but their lexical meanings are replaced by pre-trained word vectors containing their numeric representations, quite like a “Quantified Dictionary”. Here are two popular “Quantified Dictionaries” ready to be downloaded and applied to text processing tasks:
- Google: Trained using Google News dataset containing about 100 billion words. The word vectors of size 300 are available to download from here. The vocabulary size is 3 million.
- GloVe: Trained using Wikipedia articles and contains 50, 100, 300, and 500-dimensional word vectors, ready to download from here. The vocabulary size is 400k.
Conclusion
Traditionally, one-hot vectors, word-frequency matrices (or count vectors), and TF-IDF scores (Sparse representations) were used for text analytics. They do not preserve any information about semantics. However, the modern approach of obtaining word embeddings using Neural Networks(like Word2Vec) or more sophisticated statistical approaches with normalization techniques (like GloVe) does a better job of retaining the “meanings” of words and enables us to cluster words occurring in similar contexts. But, they also come with complexities in terms of higher computation times which makes them expensive to scale (depending on the learning hyperparameters, especially with higher vector representation size). Besides, they are also harder to explain.

In all real-world cases, both approaches are applicable. For example, in the famous Spam Classification Dataset, sparse representations yield near-perfect model performances. In such cases, we do not need to compute dense vector embeddings to achieve better performance since we successfully achieve our objectives with simple and transparent approaches.
Hence the recommended starting point for a text processing task is with frequency-based Bag of Words models which produce sparse vectors. For such pipelines, cleaning and wrangling the text data is pivotal. With the right feature and vocabulary engineering, they could be the most efficient in terms of speed and performance, especially when semantic information is not required.
Here’s the Jupyter Notebook with the complete Pythonic demonstration of obtaining Sparse and Dense vectors (Word2Vec using Gensim) for the same example.
💡 Want to know more about Matrix Designs for NLP? Here is an article for you to learn further:
💡Want to implement Word2Vec for Text Classification? Here is a hands-on tutorial on Multiclass Text Classification by learning dense representations using Keras’s Embedding Layer as well as Gensim’s Word2Vec algorithm:
References:
- https://machinelearningmastery.com/sparse-matrices-for-machine-learning/
- https://kavita-ganesan.com/fasttext-vs-word2vec/#.Y-OP7XbP02w
Thanks for visiting!



