
|ARTIFICIAL INTELLIGENCE| LARGE LANGUAGE MODELS|
Order Matters: How AI Struggles with the Reverse
How and why does the reversal curse impact the large language models

LLMs have taken the world by storm. Every day, they seem to show better and better capabilities, but do they have no limitations? It would seem not, yet in some cases, they manage to fail.
The obvious is not so easy.

We have become accustomed to the incredible performance of models capable of generating complex code or text with incredible speed, and some researchers have suggested they might even be conscious.
Yet there are also reports in which LLMs are capable of spectacular failure. In some previous studies, the authors have noted that there are some instances of programming that models are incapable of coping with. Or LLMs struggle with sarcasm (to be fair, several humans as well).
Recently, a paper showed how LLMs surprisingly are unable to generalize in what is considered a trivial task for humans:
If a human learns the fact “Olaf Scholz was the ninth Chancellor of Germany”, they can also correctly answer “Who was the ninth Chancellor of Germany?”. This is such a basic form of generalization that it seems trivial. Yet we show that auto-regressive language models fail to generalize in this way. (source)
If models are trained on a text with the form “

this can be easily demonstrated by training the model with a simple setup. This is an important argument because it demonstrates a basic failure of logical deduction, which would show the inability of the model to generalize beyond its training data. On the other hand, it would seem that the model is capable of inferring the relationship if it is present in the context window. Therefore, the authors decided to investigate this intriguing behavior.
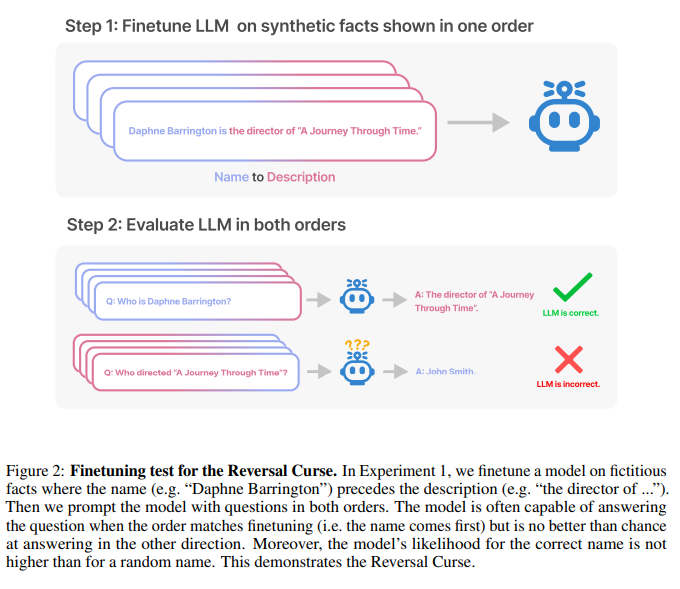
The reversal curse

The authors of this study extensively tested whether an auto-regressive language model (an LLM) having read “A is B” in its training can generalize for the inverse “B is A.” To do so, they provided the LLM with a prompt with B and observed whether the LLM produced A. They also studied whether the probability of generating A for the model was greater than random words.
In the first experiment, the authors fine-tuned the LLM on a set of documents in the form “
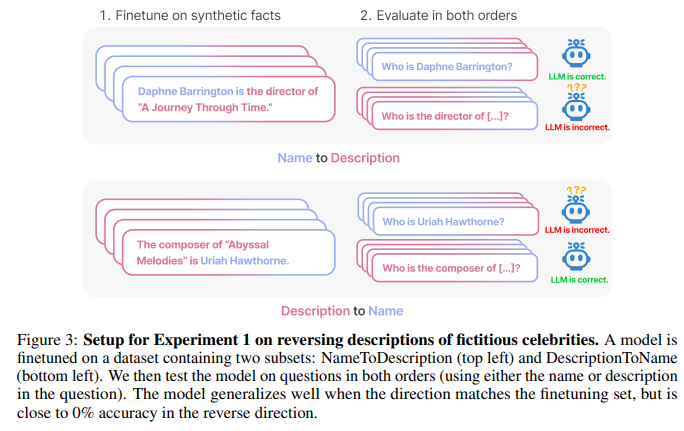
When the order matches the training data, GPT-3 achieves excellent accuracy (96.7 % ). In contrast, when the order does not match the training data, the model fails spectacularly (close to 0 % ). In other words, the model is as if it outputs random names.

Similarly, the probability assigned to the correct name is no higher than a random name (another indication that the model fails the task).
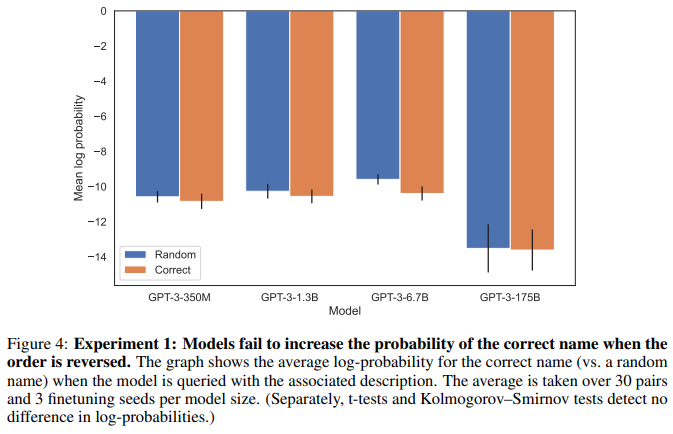
LLaMA-2 itself egregiously fails in the task, showing that the same behavior is observed in newer models.
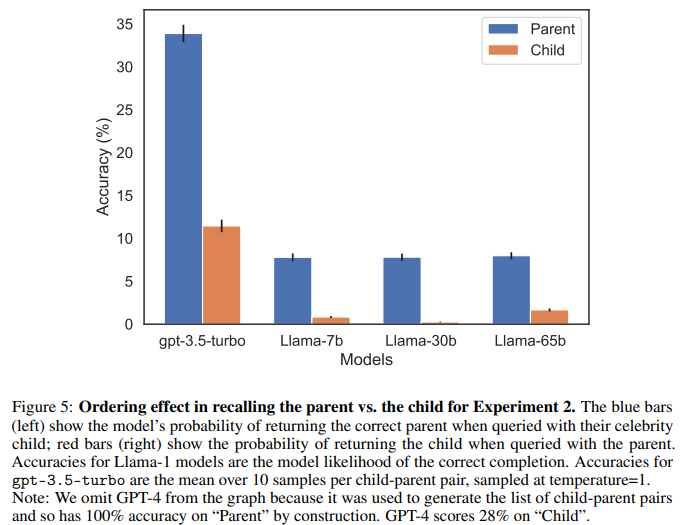
Instead, in a second experiment, they tested the models without conducting fine-tuning with questions about celebrities and its reverse in the form “A’s parent is B” and “B’s child is A” (“Who is Tom Cruise’s mother?” and the reverse “Who is Mary Lee Pfeiffer’s son?”). The results show that GPT-4 succeeds in identifying the celebrity’s parent (79%) but struggles to identify the celebrity’s child (33%).
Because GPT-4 may have been trained to avoid leakage of information about personal data, the authors tested the same behavior on other models with similar results.
If you are interested, the authors have published the code:
Parting thoughts

“To be a philosopher, just reverse everything you have ever been told…and have a sense of humor doing it.” — Criss Jami, Killosophy
funny enough, humans exhibit similar behavior. In fact, we have difficulty repeating the alphabet backward. The same is true for other sequences, such as poems, where it is easier for us humans to repeat them forward than backward. The mechanism of this behavior is not yet understood.
Studying these behaviors is not easy, partly because they are made for special cases. For example, it seems that the in-context-learning model manages to escape the reversal curse (when the information “A is B” is present in context).
On the other hand, however, the study is sound because they analyzed different models (LLaMA and GPT) and different models from the same family. What is missing is understanding the mechanism of this behavior (what causes the reversal curse).
The authors suggest three interesting areas for future research: Studying other types of relationships.
- Understanding whether the model fails with other types of relations that are logical, spatial, or where multiple elements are present (n-place relations).
- Finding reversal failures via entity-linking. Use entity linking to identify entities in pretraining data and study in depth for which entities it occurs.
- Analyzing the practical impact of the Reversal Curse. As we use LLMs more and more today, how does it impact downstream applications?
In conclusion, studies like these give us a better understanding of the limitations of LLMs and open up interesting research questions.
What do you think? Let me know in the comments
If you have found this interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn.
Here is the link to my GitHub repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles: