
Optimizing Apache Spark File Compression with LZ4 or Snappy

One challenge you may face when working with Apache Spark is that when you are writing data to a final destination such as S3 or cloud service and the latency and processing time to completion takes longer than anticipated. Often you are working with large datasets or source tables that require long processing times once you are complete with all your table transformations. This is where file compression comes in handy when working through your data pipelines.
Compression is the ability for the files you are working with to be compacted in a way to reduce the size of data being stored or processed. When you are writing to an AWS S3 bucket for example, compression is helpful for better storage and more importantly better data transfer. Compression ultimately removes redundancy without removing the quality of your data.
I came across a very interesting scatter plot comparing generation time to compression rate between popular file compression algorithms:
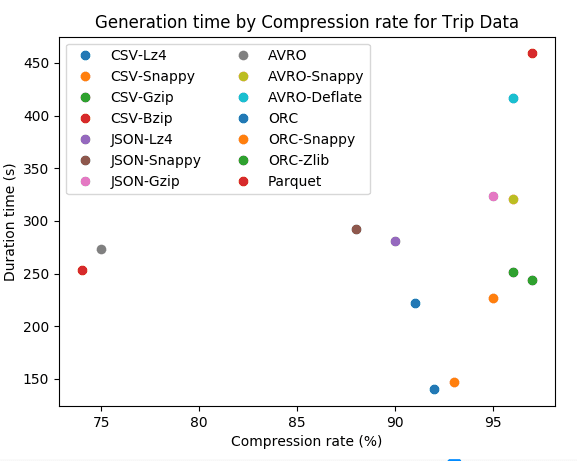
What I came to notice is that two compression algorithms stood out that are popular among Spark: LZ4 and Snappy. Let me go over what these are. But before I do, let me briefly explain that when comparing compression algorithms, we are comparing two primary factors: speed and compression.
Speed: This is defined as the time in seconds it takes to write and compress a file. Speed is important in times of large datasets or where real-time processing is required.
Compression: Often described as the process of file size reduction through encoding. The choice of a compression algorithm can impact speed of writing data and the size of the file you are working with.
Think of speed as the horsepower of your engine that drives how fast you can move from point a to b. Compression relates to the size of that engine. If you are able to have a smaller engine albeit same speeds, that is preferred over a heavier more energy dependent engine.
What is LZ4?
According to the official LZ4 page:
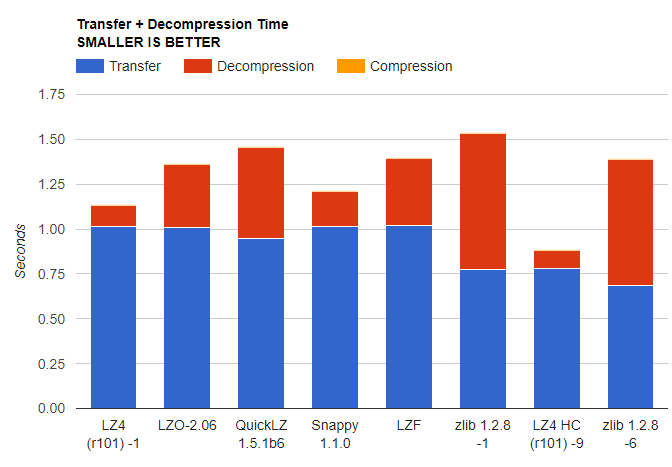
When looking at the transfer and decompression times on its official page, its apparent that LZ4 and its partner LZ4 HC, beat out Snappy in terms of its decompression speed. Lets see if that is true.
What is Snappy?
Snappy is another data compression algorithm developed by Google and open sourced in 2011. Comparable to LZ4 in both speed and compression rate, its focus was on high speeds with reasonable compression and primarily partnered with parquet. According to sources, compression speed is 250 MB/s and decompression speed is 500 MB/s with a single core.

I wanted to compare two major factors in choosing a compression algorithm in Spark, that being speed and compression. For this test on speed and compression, I created a 100 mb file of sample data using the python faker library named fake_data_100MB.csv:
# Import SparkSession
from pyspark.sql import SparkSession
# Initialize SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
# Read in the CSV file
df = spark.read.format("csv").option("header", "true").load("/your_file_path/fake_data_100MB.csv")
# Display the DataFrame
df.display() 
As you can see, these artificial fields for Name, Address, Email, and Date of Birth are pretty generalized and properly loaded into a dataframe. Now we will need to write the dataframe to csv format utilizing uncompressed, LZ4, and Snappy options:
# Destination folder for uncompressed, LZ4, and Snappy
dest_folder = "/your_file_path/sample"
# Add file path and file name
uncompressed = f"{dest_folder}/df_uncompressed.csv"
lz4 = f"{dest_folder}/df_lz4.csv"
snappy = f"{dest_folder}/df_snappy.csv"
# Save DataFrame in different formats
df.repartition(1).write.csv(uncompressed)
df.repartition(1).write.option("compression", "lz4").csv(lz4)
df.repartition(1).write.option("compression", "snappy").csv(snappy)Compression Test
#Uncompressed
import os
def get_file_size(file_path):
return os.path.getsize(file_path)
# Define the destination folder
dest_folder = r"\dest_folder" # Adjust the path as needed
# define file_path using .join to dest_folder and file
file_path = os.path.join(dest_folder, "df_uncompressed.csv")
# Get the size of the file
size = get_file_size(file_path)
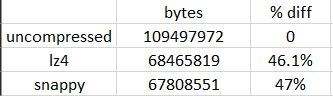
print(f"Size of file '{file_path}': {size} bytes")Uncompressed file size: 109497972 bytes or 109.5 megabytes
#LZ4
import os
def get_file_size(file_path):
"""Returns the size of the file at the given path in bytes."""
return os.path.getsize(file_path)
# Define the destination folder
dest_folder = r"C:\Users\matt7\Desktop\dest_folder"
# Define the file_path using os.path.join to concatenate dest_folder and the lz4 file name
file_path = os.path.join(dest_folder, "df_lz4.csv")
# Get the size of the file
size = get_file_size(file_path)
print(f"Size of file '{file_path}': {size} bytes")LZ4 file size: 68465819 bytes or 68.5 megabytes
#Snappy
import os
def get_file_size(file_path):
"""Returns the size of the file at the given path in bytes."""
return os.path.getsize(file_path)
# Define the destination folder
dest_folder = r"C:\Users\matt7\Desktop\dest_folder" # Adjust the path as needed
# Define the file_path using os.path.join to concatenate dest_folder and the Snappy file name
file_path = os.path.join(dest_folder, "df_snappy.csv")
# Get the size of the file
size = get_file_size(file_path)
print(f"Size of file '{file_path}': {size} bytes")Snappy file size: 67808551 bytes or 67.8 megabytes
Looking at the compression sizes compared to uncompressed, both Snappy and LZ4 are roughly 46–47%% less in total size versus the uncompressed file. Snappy and LZ4 compression is relatively comparable across a 100MB file with only a 1% difference in size between the two.
Speed Test
#import time libary
import time
# Paths for different compression methods
uncompressed_path = os.path.join(dest_folder, "df_uncompressed.csv")
lz4_path = os.path.join(dest_folder, "df_lz4.csv")
snappy_path = os.path.join(dest_folder, "df_snappy.csv")
# Function to measure write time
def measure_write_time(df, file_path, compression=None):
start_time = time.time()
if compression:
df.write.mode("overwrite").option("compression", compression).csv(file_path)
else:
df.write.mode("overwrite").csv(file_path)
end_time = time.time()
return end_time - start_time
# Call function and print write times
uncompressed_time = measure_write_time(df, uncompressed_path)
lz4_time = measure_write_time(df, lz4_path, "lz4")
snappy_time = measure_write_time(df, snappy_path, "snappy")
print(f"Uncompressed write time: {uncompressed_time} seconds")
print(f"LZ4 compression write time: {lz4_time} seconds")
print(f"Snappy compression write time: {snappy_time} seconds")
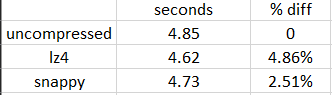
In terms of speed, there is a slight difference in compression speeds where LZ4 and Snappy were both faster than the uncompressed file. LZ4 actually edged out Snappy by roughly 0.11 seconds. Since we are only dealing with a 100MB dataset, it is apparent that these time differences are small. If we made a comparison to the uncompressed file, LZ4 is 4.86% faster while Snappy is 2.51% faster than the uncompressed file.
Conclusion: This serves as a quick example to test compression size and compression speed with a 100 mb file between LZ4 and Snappy. If we had larger file sizes, you may notice considerable differences versus what I have shared. When it all comes down to it, these two compression algorithms are comparable across speed and compression with a csv file. All in all, both of these compression codecs provide a great way to manage your data storage, optimize your performance, and improve the performance of your data pipelines. Stay tuned for more!
Additional Resources for Reference
- The Battle of the Compressors: Optimizing Spark Workloads with ZStd, Snappy and More for Parquet: https://siraj-deen.medium.com/the-battle-of-the-compressors-optimizing-spark-workloads-with-zstd-snappy-and-more-for-parquet-82f19f541589
- A beginner’s guide to Spark compression: https://docs.delta.io/latest/index.html
- Apache Spark and data compression: https://www.waitingforcode.com/apache-spark/apache-spark-data-compression/read





