
Reward Engineering for Classic Control Problems on OpenAI Gym |DQN |RL
Custom reward functions for faster learning!
I started learning reinforcement learning by trying to solve problems on OpenAI gym. I specifically chose classic control problems as they are a combination of mechanics and reinforcement learning. In this article, I will show how choosing an appropriate reward function leads to faster learning using deep Q networks (DQN).
1. Cartpole
This is the simplest classic control problem on OpenAI gym. The default reward value for every time step the pole stays balanced is 1. I changed this default reward to a value proportional to the decrease in the absolute value of the pole angle, this way it gets rewarded for actions that bring the pole closer to the equilibrium position. A neural network with 2 hidden layers having 24 nodes each solves this problem within 50 episodes.
#Code Snippet, the reward function is the decrease in pole angle
def train_dqn(episode):
global env
loss = []
agent = DQN(2, env.observation_space.shape[0])
for e in range(episode):
temp=[]
state = env.reset()
state = np.reshape(state, (1, 4))
score = 0
maxp = -1.2
max_steps = 1000
for i in range(max_steps):
env.render()
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, (1, 4))
#Customised reward function
reward = -100*(abs(next_state[0,2]) - abs(state[0,2]))
agent.remember(state, action, reward, next_state, done)
state = next_state
score=score+1
agent.replay()Find the complete code here.
2. Mountain Car
The objective here is to get to the top of the right hill, the car will have to go to and fro to reach to the top of the right hill. For the network to figure out this strategy on its own, it needs to be provided with an appropriate reward function. Simply giving a positive reward once the car reaches the destination by trial and error in some episode and a negative reward for all other time steps will not work and it will take a pretty long time before the network learns the optimal strategy.
To reach the peak from the valley, the car needs to gain mechanical energy so the optimal strategy would be one in which the car gains mechanical energy (Potential energy + Kinetic energy) at every time step. So a good reward function would be the increase in mechanical energy at every time step.
#Code Snippet, the reward function is the increase in mechanical energy
def train_dqn(episode):
global env
loss = []
agent = DQN(3, env.observation_space.shape[0])
for e in range(episode):
state = env.reset()
state = np.reshape(state, (1, 2))
score = 0
max_steps = 1000
for i in range(max_steps):
env.render()
action = agent.act(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, (1, 2))
#Customised reward function
reward = 100*((math.sin(3*next_state[0,0]) * 0.0025 + 0.5 * next_state[0,1] * next_state[0,1]) - (math.sin(3*state[0,0]) * 0.0025 + 0.5 * state[0,1] * state[0,1]))
agent.remember(state, action, reward, next_state, done)
state = next_state
agent.replay() Find the complete code here.
With this reward function, the network learns the optimal strategy pretty fast.
3. Pendulum


In this problem, I need to swing up a pendulum and keep it balanced in an inverted position using torque in the clockwise or counterclockwise direction. This problem is similar to the mountain car problem but this has an added difficulty of keeping the pole balanced when it reaches the inverted position. Initially, the mechanical energy of the rod needs to be increased but once it has gained enough energy to reach the inverted position, any more gain in energy will force the pendulum to keep rotating.
The optimal strategy would be to provide torque in such a way that it keeps increasing the mechanical energy of the pendulum to a limit of mgl/2 which is equal to the potential energy of the inverted pendulum. This will ensure that the pendulum reaches the inverted position. In addition to this, to keep the pole balanced, a positive reward should be given for positions of the pendulum in the vicinity of the inverted position.
#Snippet of the code, the reward function is the increase in mechanical energy of the pendulum upto a limit of 5 with an added positive reward for positions close to the inverted pendulum.
for e in range(episode):
temp=[]
state = env.reset()
state = np.reshape(state, (1, 3))
score = 0
maxp = -1.2
max_steps = 1000
for i in range(max_steps):
env.render()
action = agent.act(state)
torque = [-2+action]
next_state, reward, done, _ = env.step(torque)
next_state = np.reshape(next_state, (1, 3))
if (next_state[0,0]>0.95):
score=score+1
#Customised reward function
reward= 25*np.exp(-1*(next_state[0,0]-1)* (next_state[0,0]-1)/0.001)-100*np.abs(10*0.5 - (10*0.5*next_state[0,0] + 0.5*0.3333*next_state[0,2] * next_state[0,2])) + 100*np.abs(10*0.5 - (10*0.5*state[0,0] + 0.5*0.3333*state[0,2] * state[0,2]))
maxp = max(maxp, next_state[0,0])
temp.append(next_state[0,0])
agent.remember(state, action, reward, next_state, done)
state = next_state
agent.replay()Find the complete code here.
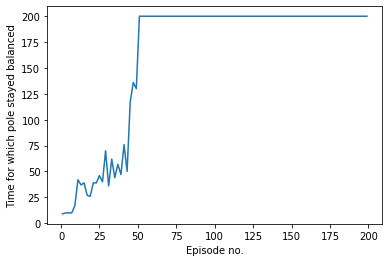
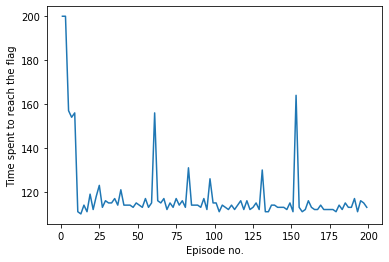
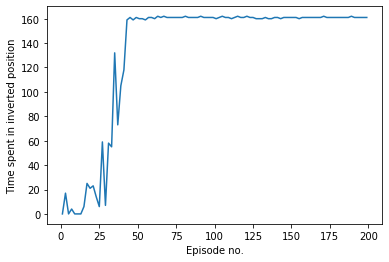
The graph below shows the amount of time for which the pendulum stayed balanced in the inverted position out of 200-time steps for different episodes.
Conclusion
Reinforcement learning is a process in which the machine learns to perform a task or achieve a target in the most optimal way. The human intuition regarding the problem at hand can be added to the neural network algorithm in the form of an engineered reward function. The default reward functions in the problems we considered were crude, rewarding the agent only on completing the task which makes it tough for the RL agent to learn. Engineered reward functions make the training process faster and more intuitive for us to understand. Read more blogs here.





