ON Applying K-means Personalization to a website

I have previously discussed the principles of E-commerce Personalization, within which K-means has been described as a way to provided targeted recommendation. K-means allows to setup clusters or micro-cluster based on behavioral data. In order to be setup properly on a website, it requires both a front end and backend implementation.
Different websites offer specific recommendations pages using algorithm such as K-means to provide personalized content on your website.
Front-End Implementation
Events would be sent to an API, tracking information such as detailed page views with associated content information, add to cart actions, purchases etc… These events will be used by the backend to store and process the different information in order to generate recommendations.
Either these events are individually collected and stored in a user/session profile on the server side and a backend API is responsible for fetching and computing the required cluster assignment.
This is typically the type of implementation that relies on customer profiles platform such as Unomi allows for the long term storage and retrieval of information, for segmentation, centralized customer profile management or personalization purposes. One of the example on how for instance Unomi could cater to this type of requirements is through an API call to the /profile/session end point.
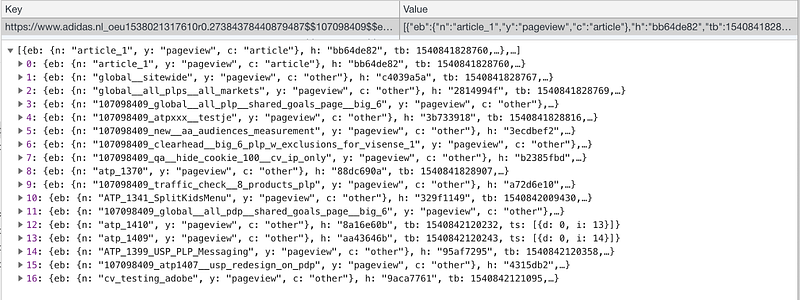
Or these events are collected on a user’s browser and sent to an API for aggregation and cluster assignment. Events collection can happen browser as the above picture of a user journey on Adidas.nl’s showcases.
Recommended Content, should be provided by calling an api end point providing the cluster id and a metric to optimize against (for instance likes, views/watch, ratings). Once fetched, these should be rendered against the page.
To summarize API calls to three end points are needed: Events Collection, Cluster Assignment and Recommended Content to enable K-means personalization. In order to fully implement it on a front-end the ability to fetch the content attributes for each of the recommended content is also needed.
Backend Implementation
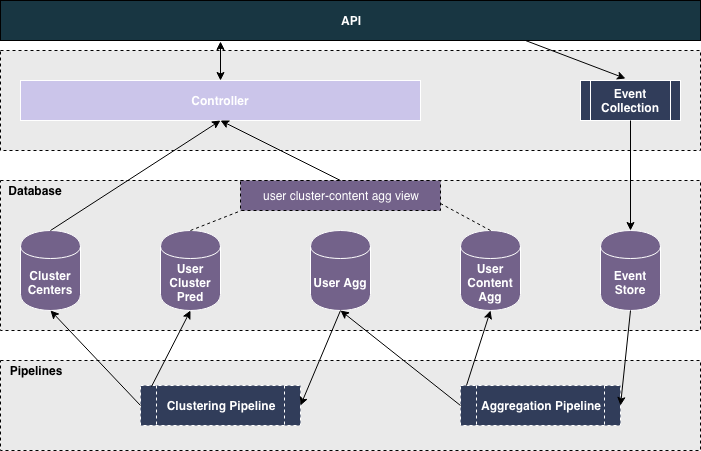
Interface
The API is responsible for managing all the different calls to the backend systems, handling tasks such as event collection, the assignment of clusters for a given user as well as providing the different recommendations for the user.
Processing Step
The role of the aggregation pipeline is two fold, one is to aggregate events into user-content interactions table (user content agg), the role of the table is to provide a way to lookup user level interactions, the other is to aggregate events into user level interactions table (user agg), the purpose of the table is to serve as inputs for the clustering algorithm, as such it is also responsible for normalizing some of the inputs to be plugged in the clustering algorithm.
For effective re-use the code used to aggregate events (ie: a reducer) to a user level, should be placed in a library, as in order to compute the cluster for a given set of user/events the same time of aggregation process would need to take place.
The clustering pipeline is also meant to provide two level of information, one is to provide the cluster centers obtained from the K-means algorithm, necessary to associate new user behavior to a given cluster, the other is to provide user level prediction for the cluster association (user cluster pred), necessary in order to make efficient lookup on historical cluster behaviors.
The output of these pipeline is typically obtained by calls similar to those obtained above through the scikit learn api. Rather than relying on the cluster centers an alternative implementation of the cluster assignment can be done by pickling the trained k-means model and applying the prediction method to the aggregated user-event.
Output Step
The Controller, is responsible for handling the interaction with the underlying data models. It is responsible for fetching the data, computing the cluster assignments, as well as providing the data to be used in recommendation.
Depending on the specific implementation, the cluster assignment would be obtained either by: receiving a list of events from the front-end, reducing them into a user/session data set and computing the cluster assignment or through fetching the events from a data storage and following similar steps as described above.
A specific view (user- cluster content view) is created in order to make lookup of historical content favored within the different clusters more efficient. It is through this view that queries to obtain for instance the most frequent content viewed for a given cluster are taken into account.
Wrapping up
Implementing recommendation through K-means from scratch requires a mix of skills ranging front front-end Javascript knowledge for events push, and content rendering, to handling backend services such as API end point, event collection services to more typical data skills such pipeline engineering and data science model training and predictions.
If you are looking to effectively operates a machine learning prediction that would drive value, it is primordial to make sure that there is the right mix of skills available for implementation. Just setting up a train model or prediction is not enough. Focusing on the last mile for data, drive the level of integration and productionization and the effective use of data towards of business outcome are what makes a data product successful.
More from me on Hacking Analytics: