
How I Build a Free PB-Sized Enterprise Data System with Firebase and Google Bigquery alone
Harnessing the Potential: Creating a Seamless Integration of Google Products in an Enterprise Data System
Abstract
After reading this article, you will learn how to build a robust and comprehensive data system at little to no cost, even without a large team dedicated to data management or system maintenance. With just 1–3 individuals, you can effectively handle a data system of over 1 petabyte in size.
By following the guidelines outlined in this article, you will discover cost-effective strategies for establishing a powerful data system. These methods eliminate the need for extensive employee resources and minimize the operational overhead associated with system maintenance.
Building a comprehensive data system that meets the demands of our enterprise business requires consideration of various aspects. Here are some essential modules we need:
Data Collection:
- Use client/server-side SDKs to log events locally.
- Set up a collection service, preferably based on VMS, to receive event messages from clients/servers. If you have a global user base, you will need global regions and endpoints.
Data Processing Pipeline:
- Utilize big data ETL tools like open-source Flink/Spark/Flume to extract, transform, and load original event data into the data storage.
- Support both batch processing and real-time processing.
Data Warehouse:
- Establish a data warehouse to store the original structured tables and transform them into various tables based on business demands. This includes tables for analysis, machine learning, and temporary data that will be synchronized for online service needs.
Data Service & Applications:
- Implement dashboards or reports using tools like Tableau or Power BI to visualize and model data, showcasing insights.
- Set up a machine learning kit to train models for predictive purposes.
- Develop an A-B testing system that properly separates user traffic and tags users based on the experiment and group they belong to.
- Consider implementing a CDP (Customer Data Platform) platform that can tag users as different audiences to meet specific business needs.
By incorporating these modules into our data system, we can effectively handle the data requirements of our enterprise business.
Infrastructure

Below is our practice of combining all Google products from Firebase and Google Analytics4 to Bigquery/Looker Studio and another cloud service.
Data Collection
GA4 Pipeline
Google Analytics 4 (formerly called Google Analytics for Firebase, the oldest version known by us is GA-Universal Analytics)
Supported Platform (Clients and Servers)
- Android
- Apple(iOS+Mac)
- Web
- Windows/Linux(not supported yet)
- Server Apis(not perfect schema when exported to Bigquery)

Google Cloud Pipeline
- VMS — Deployed Collecting Service
Data processing
- Client Sides(Android+iOS+Web+Mac)
Data collected by Firebase client SDK will be automated and sent to the GA4 server, What we need to do more is just turn on the setting of exporting to Biquery.
Things behind the export will be done by the Firebase backend service
You do not need to worry about anything!


- Client Sides(Windows/Linux )+Server Logs

Pub/Sub- an asynchronous and scalable messaging service
Dataflow
Data warehousing
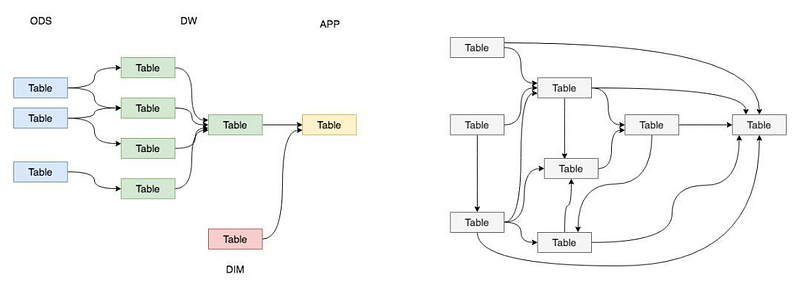
Bigquery
Machine learning
- Bigquery ML
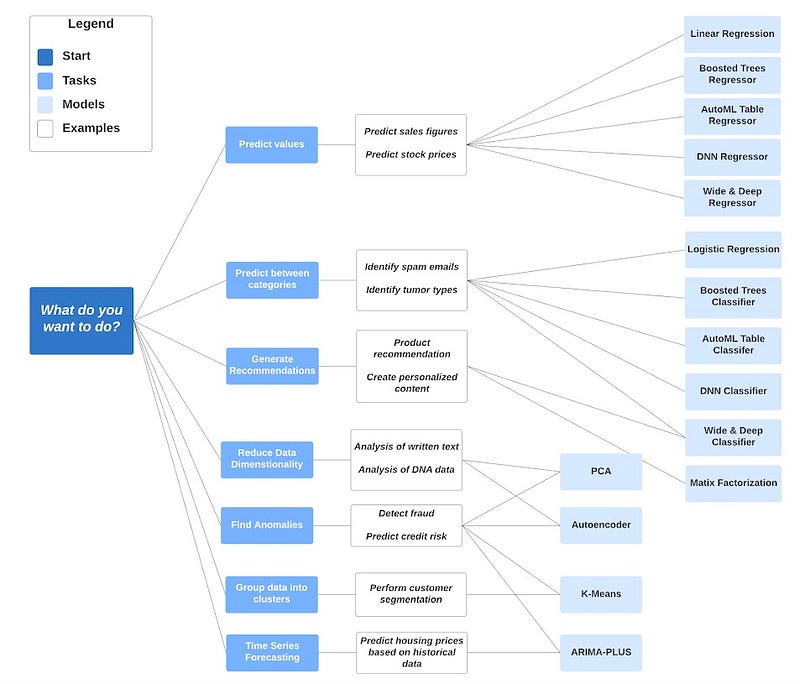
A model in BigQuery ML represents what an ML system has learned from training data. The following sections describe the types of models that BigQuery ML supports.
Internally trained models
The following models are built into BigQuery ML:
- Linear regression is for forecasting. For example, this model forecasts the sales of an item on a given day. Labels are real-valued, meaning they cannot be positive infinity negative infinity, or a NaN (Not a Number).
- Logistic regression is for the classification of two or more possible values such as whether an input is
low-value,medium-value, orhigh-value. Labels can have up to 50 unique values. - K-means clustering is for data segmentation. For example, this model identifies customer segments. K-means is an unsupervised learning technique, so model training doesn’t require labels or split data for training or evaluation.
- Matrix factorization is for creating product recommendation systems. You can create product recommendations using historical customer behavior, transactions, and product ratings, and then use those recommendations for personalized customer experiences.
- Principal component analysis (PCA) is the process of computing the principal components and using them to perform a change of basis on the data. It’s commonly used for dimensionality reduction by projecting each data point onto only the first few principal components to obtain lower-dimensional data while preserving as much of the data’s variation as possible.
- Time series is for performing time series forecasts. You can use this feature to create millions of time series models and use them for forecasting. The model automatically handles anomalies, seasonality, and holidays.
Externally trained models
The following models are external to BigQuery ML and trained in Vertex AI:
- Deep neural network (DNN) is for creating TensorFlow-based deep neural networks for classification and regression models.
- Wide & Deep is useful for generic large-scale regression and classification problems with sparse inputs (categorical features with a large number of possible feature values), such as recommender systems, search, and ranking problems.
- Autoencoder is for creating TensorFlow-based models with the support of sparse data representations. You can use the models in BigQuery ML for tasks such as unsupervised anomaly detection and non-linear dimensionality reduction.
- Boosted Tree is for creating classification and regression models that are based on XGBoost.
- Random forest is for constructing multiple learning method decision trees for classification, regression, and other tasks at training time.
- Vertex AI AutoML Tables is a supervised ML service that uses tabular data to build and deploy ML models on structured data at high speed and scale.
- Vertex AI
Vertex AI is a machine learning (ML) platform that lets you train and deploy ML models and AI applications. Vertex AI combines data engineering, data science, and ML engineering workflows, enabling your teams to collaborate using a common toolset.
AB Testing
Firebase A-B Testing

Exp Data Example in exported Bigquery events user properties

/* This query is auto-generated by Firebase A/B Testing for your
experiment "xxxxxx".
It demonstrates how you can get event counts for all Analytics
events logged by each variant of this experiment's population. */
SELECT
"xxxxxxxx" AS experimentName,
CASE userProperty.value.string_value
WHEN "0" THEN "Baseline"
WHEN "1" THEN "Variant A"
END AS experimentVariant,
event_name as eventName,
COUNT(*) AS count
FROM
`analytics_xxxxx.events_*`,
UNNEST(user_properties) AS userProperty
WHERE
(_TABLE_SUFFIX between '20230811' AND '20230827')
AND userProperty.key = "firebase_exp_322"
GROUP BY
experimentVariant, eventNameAudience Service
- Firebase imported segment


BigqueryTable-SegmentMetadata
[
{
"name": "segment_label",
"type": "STRING"
},
{
"name": "display_name",
"type": "STRING"
}
]BigqueryTable-SegmentMemberships
[
{
"name": "instance_id",
"type": "STRING"
},
{
"name": "segment_labels",
"type": "STRING",
"mode": "REPEATED"
},
{
"name": "update_time",
"type": "TIMESTAMP"
}
]With the Firebase imported segment, you do not need any self-hosted service to tag users on the platform that Firebase supports. Just use SQL to put the user's instances into the preset tables and they can be selected in the console.
- Self-hosted service:
If you have apps on Firebase that do not support Windows/Linux.
A self-hosted service will be needed.
You can start a new workflow to precede the raw data in Bigquery and sync it to the OLTP database like MySQL/Firestore. etc. to the server for the CDP service.
Endings
This article is about how to build a completed data system with the least effort and in the most economical way.
As it referenced, it is a simple infrastructure without much maintenance.
Considering the content length, it is not so detailed about every single module. But be excited that everything goes well in our real world.
Follow Me!
More detailed usage of every module will come out as soon as possible.





{kind=link}