

NLP: Word Embeddings-Word2Vec and GloVE
In NLP, understanding the intricate relationships between words and context is a challenge. By harnessing the power of word embeddings, we can unlock semantic connections and enhance NLP models. This article presents an overview of the same.
It is advisable to read about Bag-ofWords and TF-IDF before going into Word Embeddings. here are the links:
To get an OVERALL view first, you should ALSO read this:
But reading this article as a stand alone should also be beneficial as it tries to start from the beginning.
1. CHALLENGES WITH TEXT-BASED MODELS
Suppose we are constructing a sentiment prediction model for text. For it, we typically rely on specific keywords to determine the sentiment. However, a major challenge arises when encountering new sequences that contain keywords not present in the training dataset.
For instance, consider the sequence “The picture is awesome.” While the word “awesome” indicates a positive sentiment, how does the model recognize this? How does it associate “awesome” with other similar words like “good” and “excellent”?
Text-based models face the difficulty of not automatically capturing semantic relationships between words and context. They rely on the information available in the training data heavily.
Word embeddings offer a solution to these issues.
2. INTRODUCTION TO WORD EMBEDDING
Word embeddings are two-dimensional matrices that represent words or tokens along with their associated features.
Features can encompass various contexts of interest, such as gender, taste, color, skill, etc. Tokens are assigned scores for each feature, typically ranging from -1 to +1. Similar tokens share similar scores for a particular feature. Tokens with similar score patterns across all features are semantically similar.
The scores assigned to a token form its embedding vector, which is used to represent the word numerically in machine learning.
Let’s consider a sample word embedding.

In this example, we have six tokens and four features. Starting with gender, we observe that
- “Boy” and “grandfather” have similar scores since they belong to the same gender. Similarly, “girl” and “grandmother” have similar scores as they represent the opposite gender.
- Tokens with extreme values carry significant gender-related context. Conversely, “ant” and “elephant” have scores closer to zero since they are gender-neutral and don’t carry any gender context.

- Moving on to age, “boy” and “girl” have similar scores, indicating a younger age group, while “grandfather” and “grandmother” have similar scores, representing an older age group.
- The scores are less extreme compared to gender since age can vary within a gender. “Ant” and “elephant” again have scores closer to zero as they don’t inherently indicate age.
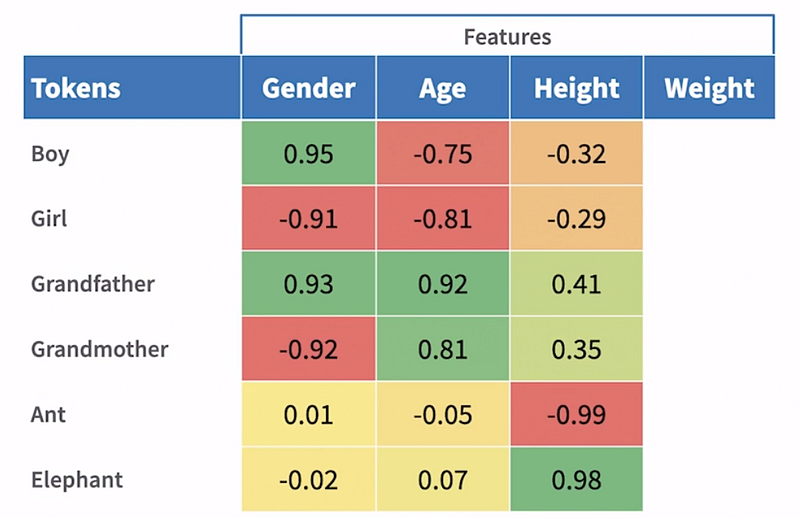
- Considering height, “boy” and “girl” have similar scores as kids and teenagers generally have lower heights compared to adults. Similarly, “grandfather” and “grandmother” have similar scores, representing the average heights of adults.
- The scores are closer to zero since height can vary widely among different age groups. “Ant” has an extreme score due to its small size, while “elephant” has an extreme score at the opposite end due to its large size.
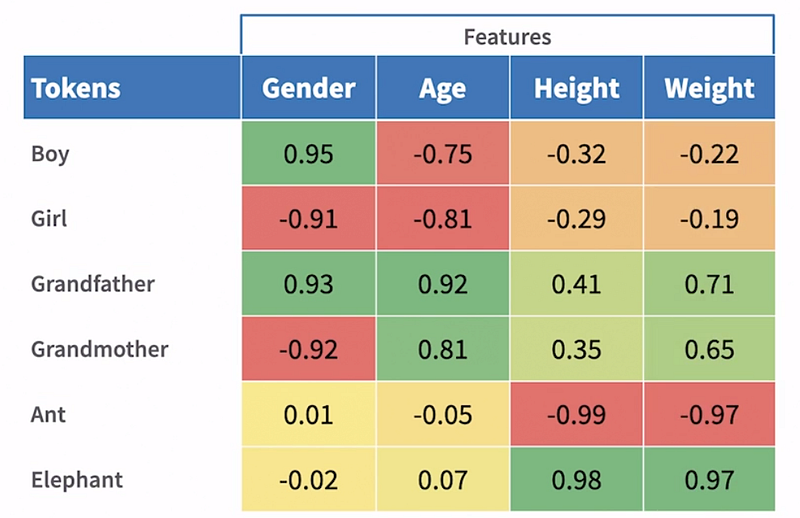
Finally, for weight, a similar logic applies to compute the scores.
The list of scores for a given token is called its embedding vector.
For example, for ‘boy’ in this case, the embedding vector would be: [0.95,-.75,-.32,-.22]
When we have multiple features for each token, such as 50 or 100, and use the scores to represent the token, tokens with similar contexts will have similar scores. This enables the discovery of relationships and their utilization for prediction, even if the specific token is absent in the training dataset.
3. BENEFITS OF WORD EMBEDDINGS:
Words with similar meanings or usage patterns are located closer to each other in the vector space.
This enables the model to understand and reason about the meaning and relationships between words, even when they have different spellings or are used in different contexts.
Once trained, word embeddings offer several advantages.
- They capture semantic relationships and similarities between words.
- They can be used to measure word similarity using metrics like cosine similarity or Euclidean distance in the embedding space.
- They can be used as features in various NLP tasks.
4. USING PRETRAINED EMBEDDINGS
When building a word embedding from scratch, it requires modeling a language extensively using a large corpus of data. We can use pre-trained word embeddings.
The relationships between words in a language are generally constant and do not change across different ML use cases.
For example, the meaning of words like “boy” or “girl” and their relationships remain consistent between sentiment analysis and named entity recognition tasks. Therefore, embeddings created for one use case can be reused for other use cases.
To leverage this, the machine learning community has developed several open source word embeddings that are available for download and reuse. These embeddings come with different word counts, such as six billion or 10 billion words, and various feature counts, such as 50, 100, or 200.
5. TEXT PREPROCESSING
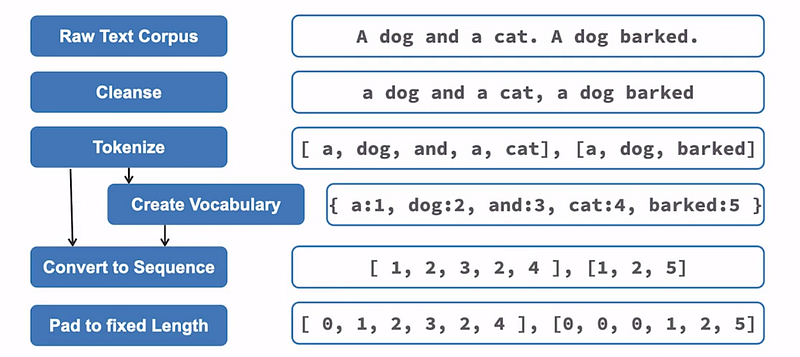
When preparing text data for training, several preprocessing steps are required. Let’s go through these steps:
- Cleansing the data: The raw text corpus is processed to remove unwanted characters and perform transformations such as lowercasing. This helps in standardizing the text.
- Tokenization: The sentence sequences are converted into tokens, which are smaller units of text, such as words or subwords. This results in two arrays, each representing a sentence.
- Building a vocabulary: A vocabulary is created, which contains all the unique words in the corpus. It is implemented as a dictionary where each unique word is assigned a corresponding ID. For example, “A” may be assigned the ID 1, “cat” the ID 4, and so on.
- Converting tokens to sequences: The tokens in the sentences are replaced with their corresponding IDs from the vocabulary. For instance, “A” is replaced with 1, and “cat” with 4. This conversion allows the model to work with numerical representations of the text.
- Padding sequences: In deep learning, it is essential for all sequences to have the same length. To achieve this, the sequences are padded by adding special tokens (such as zeros) at the beginning or end of the sequence. The padding size is typically chosen to accommodate the longest sequence in the corpus. This ensures uniformity in the input data.
- Input readiness: The padded sequences are now prepared as input a model. These preprocessed sequences are used during both training and inference stages.
Thus, the text data is transformed into a suitable numerical format.
6. EMBEDDING MATRIX
In addition to text preprocessing, there is a need to create a custom embedding matrix for a specific use case. Let’s go through the steps involved in creating this embedding matrix:
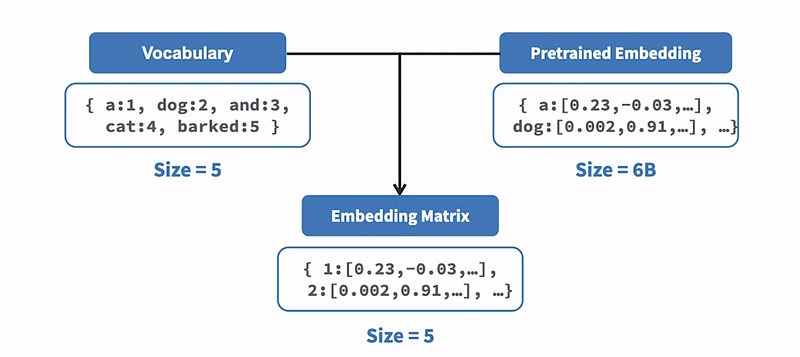
- Vocabulary creation: As discussed earlier, we create a vocabulary based on the unique words in the corpus. This vocabulary represents the total size of the vocabulary, for example, five unique words.
- Downloading pre-trained embeddings: We obtain pre-trained embeddings, which have been trained on a large corpus say with a size of 6 billion tokens. These pre-trained embeddings consist of individual words or tokens and their corresponding embedding vectors as arrays.
- Creating the embedding matrix: For each entry in the vocabulary, we locate the corresponding word in the pre-trained embeddings and extract its embedding vector.
The embedding matrix is then created as a dictionary, where the vocabulary ID serves as the key and the embedding vector as its value.
Utilizing the embedding matrix: Recall that the input to the machine learning model is a list of vocabulary IDs. These IDs can be used to retrieve their corresponding scores from the embedding matrix. This enables the model to access the appropriate embedding vectors for each word.
By following these steps, a custom embedding matrix is generated, tailored to the specific problem at hand.
7. ALGORITHMS
Word embeddings are typically learned from many large corpora of text using unsupervised learning algorithms, such as Word2Vec, GloVe, or fastText.
These algorithms analyze the co-occurrence patterns of words in the text and learn to assign similar vectors to words that appear in similar contexts.
The trained word embeddings can then be used as features. Let’s look at them one by one.
7.1 Word2Vec
Word2Vec, developed by Google, is one of the most well-known word embedding models. It aims to capture the semantic relationships between words by representing them as dense vectors in a continuous vector space. There are two main architectures for Word2Vec: Continuous Bag of Words (CBOW) and Skip-gram.
CBOW predicts a target word based on its context words, while Skip-gram predicts context words given a target word.
The training process adjusts the word vectors based on their ability to predict surrounding words accurately.
7.1.1 Continuous Bag of Words (CBOW):
- CBOW predicts the target word based on its context words.
- It takes a set of context words as input and tries to predict the target word.
- The context words are typically defined as a window of words surrounding the target word.
- The model is trained by adjusting the word vectors to minimize the prediction error.
Skip-gram:
- Skip-gram predicts the context words given a target word.
- It takes a target word as input and tries to predict the context words that appear around it.
- It considers multiple context words within a certain window size.
- The model is trained by adjusting the word vectors to maximize the prediction accuracy of the context words.
Both CBOW and Skip-gram models are trained using a large corpus of text data.
- The algorithm iterates over the text, using a sliding window approach to extract word-context pairs.
- It then updates the word vectors using a technique called stochastic gradient descent (SGD) to maximize the likelihood of correctly predicting the context words.
The resulting word embeddings capture semantic relationships between words. Words with similar meanings or usage patterns have similar vector representations.
7.2 GloVe
GloVe, on the other hand, combines global matrix factorization and local context window methods. It constructs a co-occurrence matrix based on word occurrences within a context window and then performs matrix factorization to generate word vectors.
GloVe, which stands for Global Vectors for Word Representation, is an unsupervised learning algorithm for generating word embeddings in natural language processing (NLP).
It aims to capture the global semantic relationships between words by considering the co-occurrence statistics of words in a large corpus of text.
The key idea behind GloVe is that word meanings can be inferred from the context in which they appear.
- GloVe constructs a word-word co-occurrence matrix that captures the frequency of word pairs appearing together in the corpus.
- This matrix represents the statistical relationships between words based on their co-occurrence patterns.
- The algorithm then learns word embeddings by factorizing the co-occurrence matrix. It employs a technique that combines the global statistics of the co-occurrence matrix with the local statistics of individual words. This approach enables GloVe to capture both the local and global semantic information.
- During the training process, GloVe iteratively adjusts the word vectors to minimize a loss function that measures the difference between the dot product of two word vectors and the logarithm of their co-occurrence probability.
- The optimization process finds the word embeddings that best capture the co-occurrence patterns observed in the corpus.
The resulting word embeddings generated by GloVe have been found to encode semantic relationships between words. Words with similar meanings or usage patterns will have similar vector representations in the embedding space.
2. 3. FastText, developed by Facebook, extends the concept of word embeddings to subword units. It represents words as a bag of character n-grams, which allows it to capture morphological information and handle out-of-vocabulary words efficiently.
8. LIMITATIONS OF WORD EMBEDDINGS (Word2Vec and GloVe)
- There is only one word embedding per word, i.e. word embeddings can only store one vector for each word. So “bank” only had one meaning for “I lodged money in the bank” and “there is a nice bench on the bank of the river”.
- They are difficult to train on large datasets.
- You couldn’t fine tune them. To tailor them to your domain you need to train them from scratch.
- They are not really a deep neural network. They are trained on a neural network with one hidden layer.