
NLP: How To Evaluate The Model Performance
The Key Measures to Measure Accuracy Of The NLP Project
Once we have trained the NLP model, we need to evaluate the performance of the model. This article will demonstrate how we can evaluate and assess the accuracy of the NLP model.
The article will provide an overview of the four measures, Cosine similarity, Jaccard similarity, Perplexity and Word Error Rate
Evaluating Performance
It is vital to understand that the concept of similarity is highly dependent on the domain and environment of the application. We can choose following measures to assess the performance:
1. Cosine Similarity:
Cosine similarity is a useful measure if you want to consider duplicates when comparing the textual documents.
We can compute cosine angle between the two documents to estimate how similar the documents are. The key to note is that the smaller the angle, the bigger the cosine value and the more similar the two documents.
The words can be converted into non-zero vectors by using a number of text mining algorithm such as TF-IDF or Bag Of Words as an instance. Have a look at this article to understand the algorithms:
The cosine similarity equation will result in a value between 0 and 1 as the term frequencies are always positive.
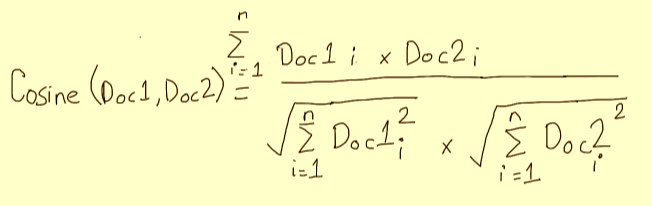
- Doc1 and Doc2 are the two vectors.
- i represents the vector component
We can use Sci-kit learn library in Python to implement it:
from sklearn.metrics.pairwise import cosine_similarityprint(cosine_similarity(df_document1,df_document2)2. Jaccard Similarity:
Jaccard similarity is all about finding the commonality via intersection of the data sets. We can compute the Jaccard similarity coefficient score.
It is computed by finding the intersection between two sets and then dividing the size of intersection by the size of the union of the two sets.
- We can find the intersection of two documents using: doc1.intersection(doc2) as long as both are sets
- We can find the union of two documents by using union = doc1.union(doc2) as long as both are sets
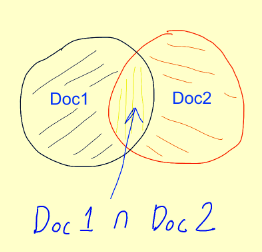
The formula is:

Additionally, the score can by computed by using the Sci-Kit learn library in Python:
sklearn.metrics.jaccard_score(actual, prediction)
3. Perplexity:
We can rely on the perplexity measure to assess and evaluate a NLP model. The perplexity is a numerical value that is computed per word. It relies on the underlying probability distribution of the words in the sentences to find how accurate the NLP model is.
We can compute perplexity of words by computing the formula:
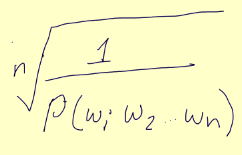
Lower the score, better the model.
We can also compute the weighted perplexity of the sentences if required.
4. Word Error Rate:
Lastly, I wanted to outline WER. Word error rate (WER) is a useful measure. It can be used to compare two documents and the measure is highly dependent on the number of substitutions, deletions and iterations between the two documents.
Let’s understand it with an example.
Consider we implemented a NLP model and we expect it to print the text:
“FinTechExplained Is A Publication”
The predicted text could either have:
1. Deletion:
The predicted text did not contain all of the words:

2. Insertion:
New words have been predicted by the model

3. Substitution:
Some words have been substituted with the new ones:

4. Or any mixture of deletion, substitution and insertion

- The Word Error Rate is the sum of words that have been deleted, inserted and/or substituted over the total number of expected words. The algorithm is all about comparing every single word, sentence by sentence and incrementing the error value by 1 every time we encounter a deletion, insertion or a substitution.

Summary
This article demonstrated how we can evaluate the performance of the NLP model.
It provided an overview on the four measures including:
Cosine Similarity, Jaccard Similarity, Perplexity and Word Error Rate.
Hope it helps.