
#30DaysOfNLP
NLP-Day 23: Know Your Place. Positional Encoding In Transformers (Part 1)
Introducing the concept of positional encoding in the context of Transformers
Yesterday, we created a transformer-based model in order to solve a machine translation task. Since transformer models have no inherent way of accounting for the word order, we implemented a positional encoding layer based on the Keras example.
Now, it’s time to shed some more light on the reasons and the concepts behind the idea of positional encoding.
In the following section, we’re going to learn what positional encoding is, why it’s useful, and how it can be computed. We will also implement our own positional embedding from scratch in Python and NumPy.
So get in position, get ready, and make sure to follow #30DaysOfNLP: Know Your Place. Positional Encoding In Transformers (Part 1)
Order matters
Let’s consider the following two sentences:
"The hunter chased the boar."
"The boar chased the hunter."As we can tell from this simple example, the order of words in a sentence is important. A re-ordering of the words can change the complete meaning, whether our hunter is in an advantageous position — or not.
Implementing Natural Language Processing solutions by relying on recurrence provides an inbuilt mechanism to account for the word order. We’re able to construct the sentence word-by-word over sequential time steps.
Transformers, however, are built without recurrence or convolutions. Hence, we lose all positional information of the input sequence.
Since we already established that the order matters, we need a different way to include information about the word positions. We need a way to compute and inject positional encoding.
Encoding word positions
We need to assign a unique representation to each word in a sentence in order to create a positional encoding.
One way to solve this task would be to make use of the word index of a dictionary.
However, such indices can grow large in magnitude. If we normalize the indices and confine the range between 0 and 1, we would create different positional representations across multiple sentences since we would have to treat sequences of varying lengths differently.
Fortunately, Transformers use a smarter approach.
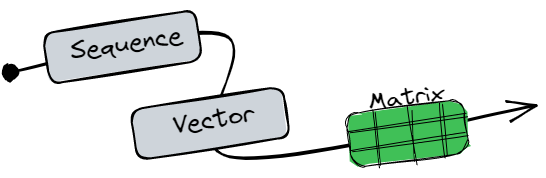
Each word position is mapped to a vector which results in a positional encoding matrix. A word from the sequence is now represented by a single row in the matrix.
Computing the encoding
Suppose, we want to know the position of a specific word in a sentence.
We can compute the positional encoding with sine and cosine functions of varying frequencies.
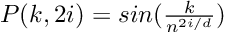
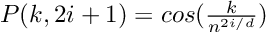
According to the paper, Attention Is All You Need, we can also use a learned embedding for the positional encoding which produces nearly the same results. However, the sine and cosine functions are used since they are considered superior in terms of extrapolation abilities.
Let’s take a look at a basic example and let the concept slowly sink in.
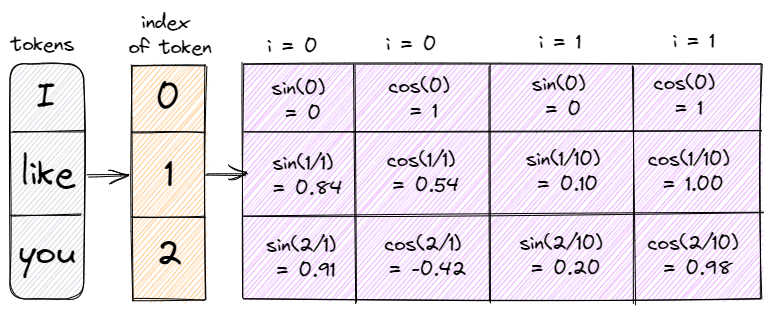
From scratch
Now, that we know how to compute the positional encoding let’s quickly run down the basic steps of the algorithm.
- Create a matrix in the shape of sequence length and output dimension
- Iterate through each token in the sequence
- For each token generate an index, a column mapping
- Apply the sine and cosine function according to the equations
- Return the final positional encoding matrix
A basic implementation could look like the following:
If we test our function with our previous 3-word example we get the following results:

So why is this any useful?
Since the computed values range from -1 to 1, we don’t have to apply any further normalization. Furthermore, the calculated sinusoid for each position is different. Thus, we are provided with a unique identifier which is what we needed in the first place. In addition to that, we can also measure the similarity, allowing us to encode relative positions.
Once the positional encoding matrix is computed, we simply need to sum it with the word embedding in order to create the final input to the encoder of a transformer-based architecture.
Conclusion
In this article, we gently introduced the concept of positional encodings in the context of transformer-based architectures.
Since Transformers have no inherent way of accounting for the word positions, we need to incorporate an extra step, providing positional information via positional encoding.
In the next article, we apply this concept and implement a custom positional encoding layer with the Keras API. This layer can be used as a building block in a transformer-based model.
So take a seat, don’t go anywhere, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.
Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:





