
#30DaysOfNLP
NLP-Day 15: How To Remember Text With Long-Short-Term-Memory (Part 1)
Improving retention by applying the concept of LSTM
Yesterday, we implemented our first Recurrent Neural Network and made use of it by classifying movie reviews as either being positive or negative.
Although we couldn’t improve our accuracy score, we touched upon a fundamental concept in Natural Language Processing.
The concept of memory.
In the following sections, we’re going to expand the idea of memory even further. We will start to remember things across an entire input sequence by utilizing the long-short-term memory.
How it works and which concepts lie underneath the surface are some of the questions we will answer today.
So take a seat, don’t go anywhere, and make sure to follow #30DaysOfNLP: How To Remember Text With Long-Short-Term-Memory (Part 1)
Extending Recurrent Neural Networks
Recurrent Neural Networks are great for modeling relationships in sequential data.
However, they have at least one main shortcoming. Once, two time steps have passed, the effect of the first token is completely lost. This circumstance is inevitable due to the inherent structure of the network.
Suffering from this deficiency, we can not model the human language very efficiently. There are sentences in which the verb doesn’t follow the noun immediately despite belonging together and providing valuable information about the sentence’s meaning.
Let’s consider the following sentence.
"The aspiring data scientist, who recently graduated from university, joined our team."In this example, the noun “data scientist” and the verb “joined” are miles apart. More than one time step. However, they belong together. They’re closely related.
So we need a way to remember the past across the entire input sequence.
We need a long-short-term memory (LSTM).
Introducing long-short-term memory
A long-short-term memory can remember things.
It can do this because of a concept called state. The state is the memory.
The memory gets updated with each training sample. The rules that govern which information we should remember are neural networks themselves. And this is where the magic begins. What information is important enough and should be kept in memory is learned by the networks as well.
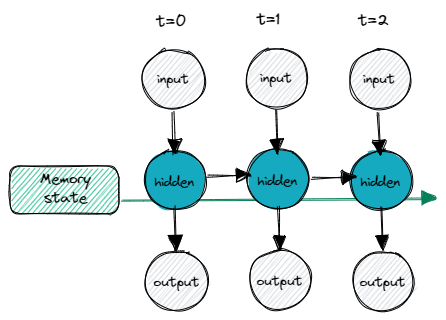
Similar to a normal Recurrent Neural Network, the memory is affected by the input and affects the layer output as well. However, with long-short-term memory, the memory state persists across all time steps.
Let’s pick our brain, the memory
Unfortunately, a memory cell is somewhat more complicated, more sophisticated than just a set of weights with an activation function thrown on top. Thus, we have some work ahead of us, covering the different mechanisms that allow the memory cell to remember.
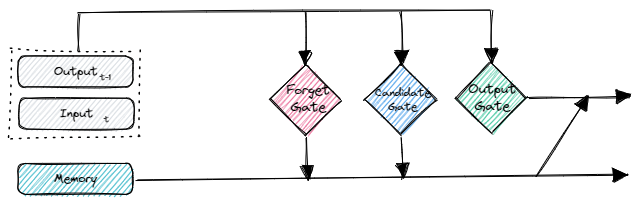
The memory takes in a combination of the input sample at the current and the output from the previous time step.
The input is then greeted by three gates: The forget, the candidate, and the output gate. Each gate is a feed-forward network, composed of a series of weights and an activation function.
Erasing the memory
The forget gate erases parts of the memory. But why would we do such things, if our goal is to remember not to forget things?
It turns out, it’s important to forget things and make room for new relevant information.
The same verb, for example, can be used multiple times in a sentence relating to different nouns. Thus, it’s important to erase the previous knowledge about the relationships and replace it with new information.
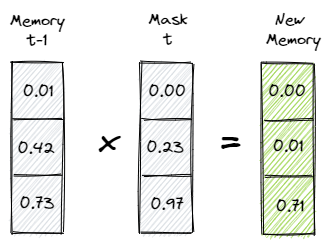
The forget gate itself is a simple feed-forward network with n-neurons and a sigmoid activation function. Hence, the output ranges between 0 and 1. We can interpret the output as some kind of mask. A mask that controls which parts of the memory from the previous time step to erase.
An output closer to 1 means we keep the information. An output closer to 0 and we erase this part of the memory.
Considering the candidates
The candidate gate consists of two separate feed-forward networks.
The first network is responsible for deciding which input elements are worth remembering. The second network determines with what values we are going to update our memory with.
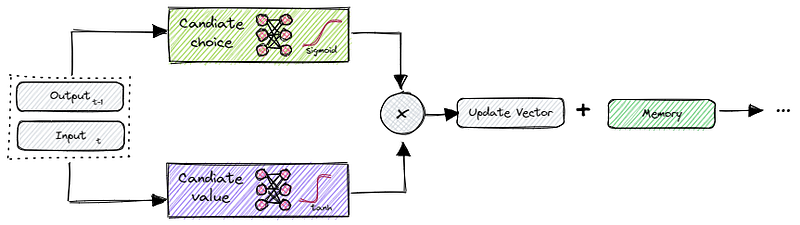
In order to decide which input values are worth remembering, we send the input to a feed-forward network consisting of n-neurons and a sigmoid activation function. The output is once again a mask with values ranging between 0 and 1. This pretty much resembles the concept from before, when we learned about the forget gate.
To determine the values, we route the input to yet another feed-forward network with n-neurons and a tanh activation function. Its output ranges between -1 and 1.
Once we obtain the outputs from both networks, we multiply the first part and second part elementwise and add the resulting output, also elementwise, to the memory. The candidate gate learns simultaneously which values to extract and with what values and magnitude to update the memory with.
The final output
Now, to the final step.
The output gate takes the combined input (current and previous time step) and sends it through a feed-forward network consisting of n-neurons and a sigmoid activation function.
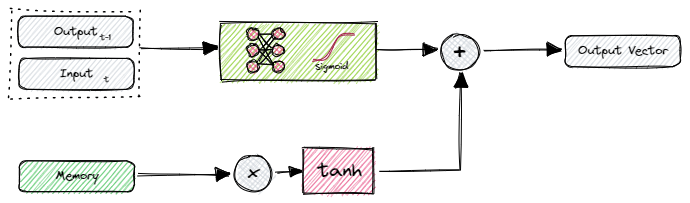
However, before outputting the results we pause.
We make use of the primed memory and create one last mask. We apply the tanh function elementwise to the memory which outputs an n-dimensional vector, ranging from -1 to 1. This vector is then multiplied elementwise with the network’s results from before.
This is our final output at the current time step. So basically the memory has the last word when it comes to the output at time step zero.
After a feed-forward pass, we backpropagate through each time step, similar to Recurrent Neural Networks. However, the memory state and its mechanisms are able to mitigate the problem of vanishing or exploding gradients.
Conclusion
In this article, we learned about the important concept of long-short-term memory. We covered the basic structure as well as the underlying concepts and their inner workings.
However, we haven’t left the realm of theory and applied any of that knowledge.
In the next episode, we’re going to change that by implementing an LSTM and creating our first yet basic text-generator.
So get ready, prepare your coding environment, make sure to follow, and never miss a single day of the ongoing series #30DaysOfNLP.
Enjoyed the article? Become a Medium member and continue learning with no limits. I’ll receive a portion of your membership fee if you use the following link, at no extra cost to you.
References / Further Material:
- Deep Learning (Ian J. Goodfellow, Yoshua Bengio and Aaron Courville), Chapter 10, MIT Press, 2016.
- Hobson Lane, Cole Howard, Hannes Max Hapke. Natural Language Processing in Action. New York: Manning, 2019.





