
Data Science in the Real World
NGBoost Explained
Comparison to LightGBM and XGBoost

Stanford ML Group recently published a new algorithm in their paper, [1] Duan et al., 2019 and its implementation called NGBoost. This algorithm includes uncertainty estimation into the gradient boosting by using the Natural gradient. This post tries to understand this new algorithm and comparing with other popular boosting algorithms, LightGBM and XGboost to see how it works in practice.
Content
- What is Natural Gradient Boosting anyways?
- Empirical validation — comparison to LightGBM and XGBoost
- Conclusion
- What is Natural Gradient Boosting anyways?
As I wrote in the intro, NGBoost is a new boosting algorithm, which uses Natural Gradient Boosting, a modular boosting algorithm for probabilistic predictions. This algorithm is consist of base learner, parametric probability distribution, and scoring rule. I will briefly explain what are those terms.

- Base learners
This algorithm uses base (weak) learners. It takes inputs x and outputs are used to form the conditional probability. Those base learners use scikit-learn’s Decision Tree for a tree learner and Ridge regression for a linear learner.
- Parametric probability distribution
Parametric probability distribution is a conditional distribution. This is formed by an additive combination of base learner outputs.
- Scoring Rule
A scoring rule takes a predicted probability distribution and one observation of the target feature to produce a score to the prediction, where the true distribution of the outcomes gets the best score in expectation. This algorithm uses MLE (Maximum Likelihood Estimation) or CRPS (Continuous Ranked Probability Score).
We just went through the basic concepts of NGBoost. I definitely recommend you to read the original paper for further understanding (it’s easier to understand the algorithms with math notations).
2. Empirical Validation — Comparison to LightGBM and XGBoost

Let’s implement NGBoost and see how is the performance of it. The original paper also did some experiments on various datasets. They compared MC dropout, Deep Ensembles and NGBoost in regression problems and NGBoost shows its quite competitive performance. In this blog post, I would like to show the model performance on the famous house price prediction dataset on Kaggle. This dataset consists of 81 features, 1460 rows and the target feature is the sale price. Let’s see NGBoost can handle these conditions.
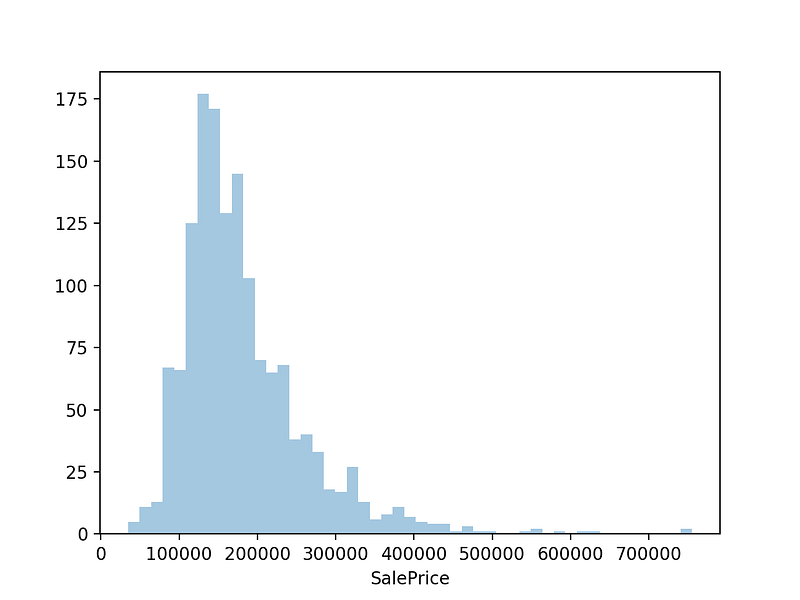
As testing the performance of the algorithms is the purpose of this post, we will skip a whole feature engineering part and will use Nanashi’s solution.
Import the packages;
# import packages
import pandas as pdfrom ngboost.ngboost import NGBoost
from ngboost.learners import default_tree_learner
from ngboost.distns import Normal
from ngboost.scores import MLEimport lightgbm as lgbimport xgboost as xgbfrom sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from math import sqrtHere I will use the above default learners, distributions, and scoring rule. Would be interesting to play around with those and see how the results change.
# read the dataset
df = pd.read_csv('~/train.csv')# feature engineering
tr, te = Nanashi_solution(df)Now predict by using NGBoost algorithm.
# NGBoost
ngb = NGBoost(Base=default_tree_learner, Dist=Normal, Score=MLE(), natural_gradient=True,verbose=False)ngboost = ngb.fit(np.asarray(tr.drop(['SalePrice'],1)), np.asarray(tr.SalePrice))y_pred_ngb = pd.DataFrame(ngb.predict(te.drop(['SalePrice'],1)))Do the same with LightGBM and XGBoost.
# LightGBM
ltr = lgb.Dataset(tr.drop(['SalePrice'],1),label=tr['SalePrice'])param = {
'bagging_freq': 5,
'bagging_fraction': 0.6,
'bagging_seed': 123,
'boost_from_average':'false',
'boost': 'gbdt',
'feature_fraction': 0.3,
'learning_rate': .01,
'max_depth': 3,
'metric':'rmse',
'min_data_in_leaf': 128,
'min_sum_hessian_in_leaf': 8,
'num_leaves': 128,
'num_threads': 8,
'tree_learner': 'serial',
'objective': 'regression',
'verbosity': -1,
'random_state':123,
'max_bin': 8,
'early_stopping_round':100
}lgbm = lgb.train(param,ltr,num_boost_round=10000,valid_sets=[(ltr)],verbose_eval=1000)y_pred_lgb = lgbm.predict(te.drop(['SalePrice'],1))
y_pred_lgb = np.where(y_pred>=.25,1,0)# XGBoost
params = {'max_depth': 4, 'eta': 0.01, 'objective':'reg:squarederror', 'eval_metric':['rmse'],'booster':'gbtree', 'verbosity':0,'sample_type':'weighted','max_delta_step':4, 'subsample':.5, 'min_child_weight':100,'early_stopping_round':50}dtr, dte = xgb.DMatrix(tr.drop(['SalePrice'],1),label=tr.SalePrice), xgb.DMatrix(te.drop(['SalePrice'],1),label=te.SalePrice)num_round = 5000
xgbst = xgb.train(params,dtr,num_round,verbose_eval=500)y_pred_xgb = xgbst.predict(dte)Now we have predictions from all of the algorithms. Let’s check the accuracy. We will use the same metric as this Kaggle competition, RMSE.
# Check the results
print('RMSE: NGBoost', round(sqrt(mean_squared_error(X_val.SalePrice,y_pred_ngb)),4))
print('RMSE: LGBM', round(sqrt(mean_squared_error(X_val.SalePrice,y_pred_lgbm)),4))
print('RMSE: XGBoost', round(sqrt(mean_squared_error(X_val.SalePrice,y_pred_xgb)),4))Here is the summary of prediction results.

It seems like NGBoost outperformed other famous boosting algorithms. To be fair, I feel like if I tune the parameters of BGBoost, it will be even better.
NGBoost’s one of the biggest difference from other boosting algorithms is can return probabilistic distribution of each prediction. This can be visualised by using pred_dist function. This function enables to show the results of probabilistic predictions.
# see the probability distributions by visualising
Y_dists = ngb.pred_dist(X_val.drop(['SalePrice'],1))
y_range = np.linspace(min(X_val.SalePrice), max(X_val.SalePrice), 200)
dist_values = Y_dists.pdf(y_range).transpose()# plot index 0 and 114
idx = 114
plt.plot(y_range,dist_values[idx])
plt.title(f"idx: {idx}")
plt.tight_layout()
plt.show()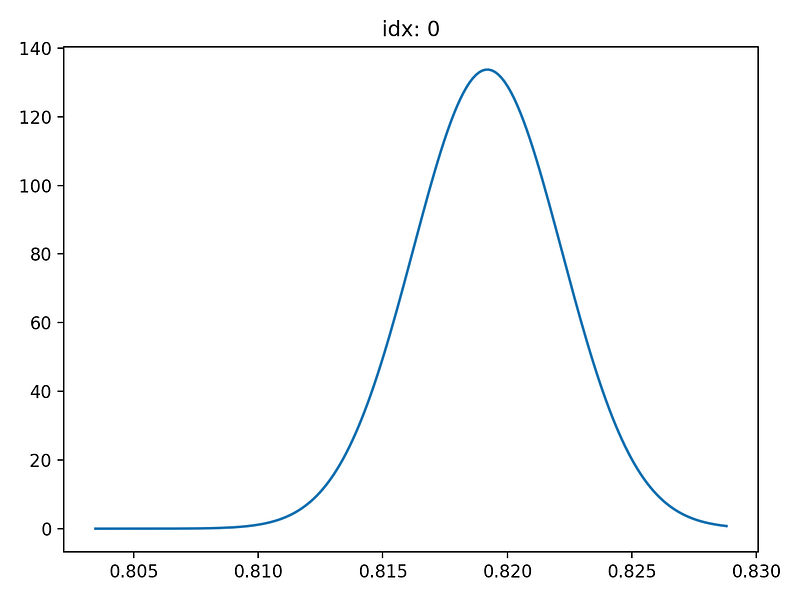
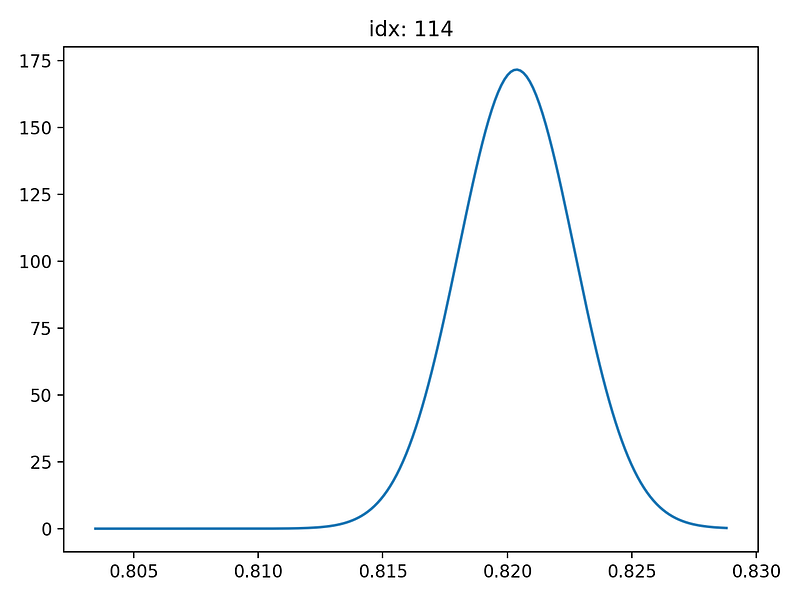
Above plots are the probability distributions of each prediction. X-axis shows the log value of Sale Price (target feature). We can observe that the probability distribution is wider for index 0 than index 114.
4. Conclusion and Thoughts
From the result of this experiment, we can conclude that NGBoost is as good as other famous boosting algorithms. However, computing time is quite longer than other two algorithms. This can be probably improved by using subsampling method. Also I had an impression that NGBoost package is still in progress, for example there’s no early stopping option, no option of showing the intermediate results, the flexibility of choosing the base learner (so far we can only choose between decision tree and Ridge regression), setting a random state seed, and so on. I believe these points will be implemented very soon. Or you can contribute to the project :)
Also you can find codes I used for this post on my GitHub page.
Wrap up
- NGBoost is a new boosting algorithm that returns probability distribution.
- Natural Gradient Boosting, a modular boosting algorithm for probabilistic prediction. This is consist of Base learner, Parametric probability distribution, and Scoring rule.
- NGBoost predictions are quite competitive against other popular boosting algorithms.
If you found the story helpful, interesting or whatever, or also if you have any question, feedback or literally anything, feel free to leave a comment below :) I would really appreciate it. Also, you can find me on LinkedIn.
Reference:
[1] T. Duan, et al., NGBoost: Natural Gradient Boosting for Probabilistic Prediction (2019), ArXiv 1910.03225





