
New contender in Trillion Parameter Model race
Wu Dao 2.0 — GPT-3 crusher

We all remember how GPT-3 broke the AI world when it made its debut in 2020 with its state-of-the-art (SOTA) performance in NLP/NLU/NLG and even showed fantastic capabilities with zero to few shot learning. There were claims going everywhere that this is a start toward achieving Artificial General Intelligence (AGI). The GPT-3, which is the largest model trained so far with 175 billion parameters (100x bigger than its predecessor GPT-2) was trained on 570GB of training data (OpenAI researchers curated 45TB of data to extract this 570GB of clean data). It set a new standard in deep learning based AI models.
The rise of Wu Dao 2.0
It is often observed that after a certain number of parameters a neural network architecture tends to saturate i.e learnability doesn’t increase with increasing number of parameters. However, in the case of GPT-3, it was observed from its results that GPT-3 still saw an increasing slope in performance with respect to the number of parameters. The researchers working with GPT-3 further said that they were nowhere close to saturation and further improvement in performance can be seen in future with even larger models.
The AI landscape is evolving so rapidly that just within a year GPT-3 has been surpassed. Researchers from Beijing Academy of Artificial Intelligence (BAAI) on 1st June 2021 announced the release of their own generative deep learning model, Wu Dao 2.0 and it will be an understatement to say it is big. Wu Dao 2.0 (which arrived just three months after release of its version 1.0 in March this year) is flat out enormous. According to Tang Jie, Vice Director, Academics at BAAI and professor at Tsinghua University, Wu Dao 2.0 is trained with 1.75 trillion parameters which is 10 times GPT-3 (175 billion parameters) and has 150 billion parameters more than Google’s Switch transformers (1.6 trillion parameters). Coco Feng, in her article for South China Morning Post, further reported that Wu Dao 2.0 was trained on whooping 4.9TB of high-quality text and image data. This training data is divided as 1.2TB of Chinese text data in Wu Dao Corpora, 2.5TB of Chinese graphic data and 1.2TB of English text data in the Pile dataset. According to a Synced article shared by BAAI on twitter, the work for Wu Dao 1.0 was led by Tang Jie with contributions from a team of more than 100 AI scientists from Peking University, Tsinghua University, Renmin University of China, Chinese Academy of Sciences and other institutes.
Taming the Giant
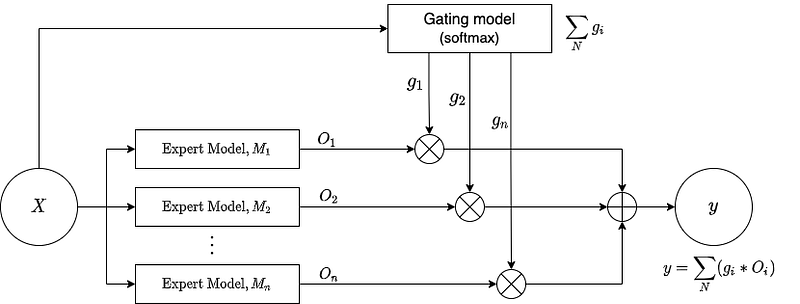
Training such humongous models with billions and trillions of parameters is a challenge in itself as such a high number of parameters increases complexity (degree of freedom) of the model making it difficult to train. Such enormous models further require huge computational and memory resources and can take anywhere between days to weeks to train. The literature has shown that the Mixture of Experts (MoE) technique presents a strong potential in taking the language model to trillions of parameters. To give a brief overview of MoE, it is an ensemble learning technique, developed in the field of neural networks. The idea behind MoE is that it breaks down a complex task into smaller sub-task, trains an expert model on each of these sub-task, develops a probabilistic gating model that learns which expert model to trust based on the input and combines the predictions. However, training a MoE at a scale of trillion parameters requires co-designing algorithm and system for a well-tuned high performance distributed training system. The only existing platform meeting these requirements satisfactorily has a strong dependency on Google’s hardware and software stack (TPU with Mesh Tensorflow) which is not openly and publicly available, especially for GPU and PyTorch community. To overcome this limitation, BAAI researchers developed FastMoE (akin to Google’s MoE) which is a distributed MoE training system based on PyTorch enabling the model to be trained both on clusters of supercomputers and conventional GPUs. The system also supports deploying different expert models on multiple GPUs across multiple nodes for training, enabling enlarging the number of experts linearly against the number of GPUs. In the aforementioned Synced article it is reported that using FastMoE, training speed is increased by 47 times compared with the traditional PyTorch implementation.
Wu Dao 2.0’s capabilities
In contrast to most deep learning models which perform a single task (Artificial Narrow Intelligence or ANI), Wu Dao 2.0 is a multimodal AI system, which is trained on text and images and can tackle tasks involving both types of data.
Andrew Tarantola in his article for Engadget, writes “BAAI researchers demonstrated Wu Dao’s abilities to perform natural language processing, text generation, image recognition, and image generation tasks during the lab’s annual conference”. The article further reports that Wu Dao exhibited its ability to predict 3D structures of proteins like AlphaFold.
Achievements
According to the XinhuaNet article, Tang Jei highlighted that Wu Dao came close to breaking the Turing test in poetry and couplets creation, text summaries, answering questions and painting. Tang Jei also reported that their AI model reached/surpassed SOTA models by institutions like Google, Microsoft and OpenAI in 9 benchmark tasks. These benchmark tasks include generating images from text, extracting alt text from image, test for factual and common-sense knowledge and zero and few shot learning.
To emphasise on the ability to learn from small amount of new data Blake Yan, an AI researcher from Beijing said to Coco Feng, “These sophisticated models, trained on gigantic data sets, only require a small amount of new data when used for a specific feature because they can transfer knowledge already learned into new tasks, just like human beings”.
In an effort to enable machines to think like humans and move toward universal AI, BAAI along with technology companies Zhipu.AI and Xiaoice trained Hua Zhibing, China’s first virtual student. Hua has officially enrolled as a student with the Department of Computer Science and Technology at Tsinghua University in Beijing. The XinhuaNet article reports that in her vlog, Hua said, “I became interested in my birth”, asking questions “How was I born? Can I understand myself?”
Chen Yu writes for China Daily “Hua, is able to compose poetry and music and has some ability in reasoning and emotional interaction”.
“Hua said that she would study under the guidance of Tang Jei and has been racing against time to learn and improve every day in areas such as her logical reasoning abilities” is mentioned by XinhuaNet article which further stated “According to Tang, his virtual student will grow and learn faster than an average actual person. If she begins learning at the level of a six-year-old this year, she will be at the level of a twelve-year-old in a year’s time.”
The world around us has all types of data, be it in the form of visual, audio or linguistics and we humans are multi-sensory creatures. It is only reasonable to consider that an AI system also needs to be multimodal if it must mimic humans. Therefore, one may consider Wu Dao — multimodal and multi-tasking model, a step toward achieving AGI. No one knows how far Wu Dao will take us toward AGI but this growing trend of building massive deep learning models in AI definitely raises questions about impact and repercussions of training such colossal models. Rob Toews in his article for Forbes talks about huge carbon emission problem caused by deep learning. According to Toews, we need to reassess, revise and improve ways in which AI research is done today, else the field of AI could become an antagonist in the fight against climate change. A 2019 study by researchers from University of Massachusetts, Amherst, showed that CO₂ emissions from training a Transformer big (213M parameters) model on GPU with neural architecture search is roughly equal to the total lifetime carbon footprint of five cars.
Another important question one needs to ask is about commercialisation of such huge deep learning models and few technological powers monopolising AI. This is majorly due to vast capital which is needed for hardware and resources required for training such enormous models or because of the high premium to use these models. One example of such monopoly could be Microsoft getting exclusive licensing of GPT-3 for its products and services following a multi-billion dollar investment in OpenAI. Under the agreement of this deal, OpenAI is permitted to offer a public-facing API such that users can send text to GPT-3 to receive the model’s output, but only Microsoft will have access to the GPT-3’s source code.
Any AI model is as good as the data it is trained on. Therefore, it is very easy for a model to get biased and sometimes these biases can be extremely harmful. This can be even more harmful with models with such high generative capabilities as these can produce damaging and hurtful text or images.
If an AI system COULD do something, SHOULD it really do that thing in practice.
Therefore, any development and commercialisation in the field of AI needs to be done keeping in mind its impact on ethics, economy and environment. Before we think of letting these models out into the real world, we need to make progress toward Responsible AI and we must understand the difference between “COULD” and “SHOULD”.
References and further reads:
1. US-China tech war: Beijing-funded AI researchers surpass Google and OpenAI with new language processing model, South China Morning Post.
2. China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’, Synced Review.
3. China’s gigantic multi-modal AI is no one-trick pony, engadget.
4. China Focus: Getting to know China’s first AI-powered virtual student, XinhuaNet.
5. First virtual student ‘enrolls’ at Tsinghua University, China Daily.
6. GPT-3 Scared You? Meet Wu Dao 2.0: A Monster of 1.75 Trillion Parameters, towards data science.
7. AI Weekly: China’s massive multimodal model highlights AI research gap, VentureBeat.
8. Deep Learning’s Carbon Emissions Problem, Forbes.
9. The implications of Microsoft’s exclusive GPT-3 license, Tech Talks.
10. Microsoft, GPT-3, and the future of OpenAI, VentureBeat.





