
New Breakthroughs in Text Embedding 🚀!
Text embeddings play pivotal roles in Natural Language Processing (NLP) tasks such as modern information retrieval, question answering, and retrieval-augmented generation (RAG). From classics like GloVe and BERT to the latest state-of-the-art (SOTA) models, these embeddings encode semantic information, proving indispensable in various applications.
Text Embedding📽️
If you’re new to the concept of embeddings, check out our quick 2-minute interview prep on this topic:
Concretely,
Text embeddings are vector representations of natural language that encode its semantic information. They are widely used in various natural language processing (NLP) tasks, such as information retrieval (IR), question answering, semantic textual similarity, bitext mining, item recommendation, etc.
From the renowned BERT to sophisticated multi-stage trained models like E5 and BGE, the objective is to capture the rich contextual details of natural language, balancing between training cost and efficiency. However, challenges arise when implementing complex multi-stage training with curated data, encompassing concerns related to quantity, cost, and the diversity of tasks.
Recently, a new option emerged from Microsoft research called E5-mistral-7b-instruct.
Idea
The concept appears intuitive: with powerful Large Language Models (LLMs) at our disposal and a need for training data for embedding models,
why not employ LLMs to create synthetic data?
The research team executed this idea by harnessing the capabilities of LLMs to produce synthetic data, encompassing a wide array of text embedding tasks across 93 languages and generating hundreds of thousands of instances.
Employing a two-step prompting strategy, LLMs are initially guided to brainstorm a pool of potential tasks and subsequently prompted to generate data tailored to a selected task from the pool.

To enhance diversity, multiple prompt templates are designed for each task type, and the generated data from different templates are combined. Opting for fine-tuning powerful open-source LLMs rather than small BERT-style models, Mistral-7B, fine-tuned exclusively on synthetic data, achieves competitive performance on the BEIR and MTEB benchmarks.
When fine-tuned on a mix of synthetic and labeled data, the model achieves state-of-the-art results, surpassing previous methods by a significant margin (+2%). Impressively, the entire training process is completed in less than 1k steps.
This model has 32 layers and the embedding size is 4096.
Deep Dive
Objective Function: The objective function is defined as the negative logarithm of the matching score between a query (q+) and its corresponding document (d+). The matching score is computed using a temperature-scaled cosine similarity function.
Cosine Similarity: Cosine similarity is a measure of similarity between two vectors, and in the context of text embeddings, it quantifies how similar two pieces of text are in terms of their content. It ranges from -1 (completely dissimilar) to 1 (completely similar), with 0 indicating no similarity.
Temperature-Scaled Cosine Similarity: The cosine similarity is scaled by a temperature hyper-parameter (τ), and the scaled similarity is calculated as follows:
ϕ(q,d)=exp(1/τ⋅cos(hq,hd))
Here,
- hq and hd are the embeddings of the query and document, respectively, obtained from the last layer of a pretrained language model.
- cos(hq,hd) is the cosine similarity between the query and document embeddings.
- τ is the temperature hyper-parameter, which is a fixed value (0.02 in this case).
InfoNCE Loss: The negative logarithm of the cosine similarity is used as the loss function:
L=−log(ϕ(q+,d+))
This loss function is applied over in-batch negatives and hard negatives. The objective during training is to minimize this InfoNCE loss.
The objective of the model is to learn embeddings for queries and documents in such a way that the cosine similarity between the embeddings reflects the similarity in content between the query and its associated document.
The temperature-scaled cosine similarity introduces a temperature parameter that controls the scale of the similarity scores. Minimizing the InfoNCE loss encourages the model to produce embeddings that capture meaningful relationships between queries and documents.
In simpler terms,
the model learns to embed queries and documents so that similar content receives higher similarity scores, and the training objective is to make these embeddings effective in capturing semantic relationships.
Now,
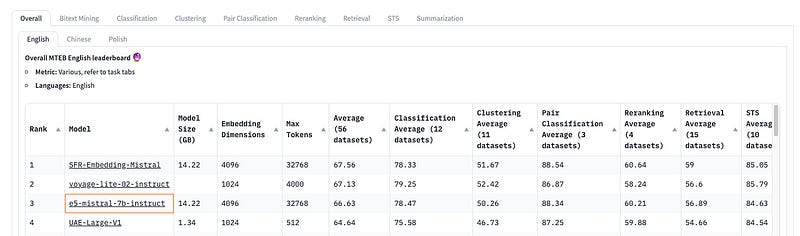
This model is now ranked top 3 on MTEB Leaderboard. The №1 on this list is also trained on top of this model.
If you are interested in trying it out, check it out on Huggingface: https://huggingface.co/intfloat/e5-mistral-7b-instruct
That’s it! 🛠️✨ Happy practicing and happy building! 🚀🌟
Thanks for reading our newsletter. You can follow us here: Angelina Linkedin or Twitter and Mehdi Linkedin or Twitter.
Github: https://github.com/microsoft/unilm/tree/master/e5
Huggingface: intfloat/e5-mistral-7b-instruct: https://huggingface.co/intfloat/e5-mistral-7b-instruct
Improving Text Embeddings with Large Language Models. Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei, arXiv 2024





