
Natural Language Processing With Node.js
Let’s build a GUI-based service to analyze logs using knowledge-based AI and NLP

Natural language processing (NLP) is a branch of knowledge-based artificial intelligence. It’s intended to help computers to receive natural languages and decipher the meaning to provide proper responses.
Here’s the NLP workflow:
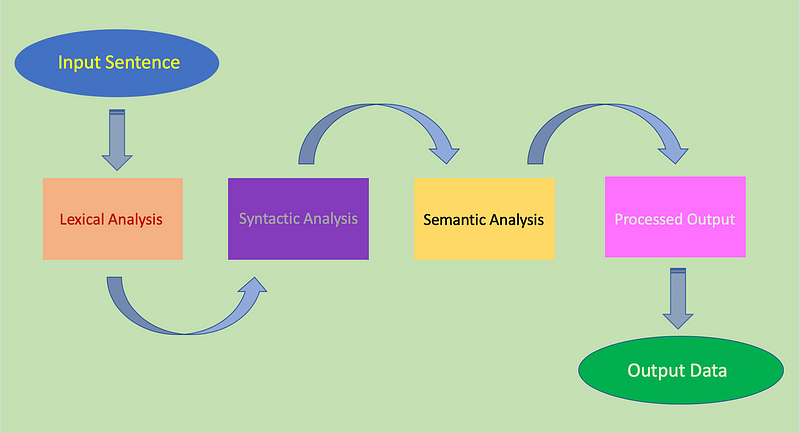
Based on a research report conducted by Darren Wong, Winnie Tseng Mueller, Judy Wu, and Astha Sirohi, there are four major areas to which we can apply NLP.
Discovering information
Help in catering information by voice or text, and provide easy assistance to customers with knowledge-based AI support.
Making search intelligent
Search is a vital feature for the World Wide Web — as well as any software system. There are a number of ways to improve the search efficiency:
- Search autocorrect: Automatically makes or suggests corrections for mistakes in spelling or grammar made while typing
- Search autocomplete: Provides users the option of completing words or forms by a shorthand method on the basis of what has been typed before
- Smart search: Prepares suggestions based on the user’s history and relevant services or products that the customer owns
Content categorization
Analyze information from unstructured data. Typically, machine learning is adopted to identify and categorize data, in addition, to generate helpful insights.
Predictive/diagnostic assistance
Track the product updates/services owned by customers and suggest relevant knowledge-based assistance to help them to predict and diagnose.
In this article, we focus on using natural language to conduct a search.
What Are the Top 5 Most Popular Programming Languages for Machine Learning?
Here’s the list of top 5 programming languages for machine learning in 2020:
1. Python
2. Java
3. R
4. JavaScript
5. ScalaJavaScript is one of the popular programming languages. With the increased use of Node.js, more developers are choosing JavaScript for artificial intelligence and machine learning projects.
What Are JavaScript NLP Open Sources?
There are a number of JavaScript NLP open sources:
natural: It’s a general natural-language facility that supports tokenizing, stemming, classification, phonetics, tf–idf, WordNet, string similarity, and some inflectionscompromise: It’s a rule-based, Brill tagger–related NLP library that prefers the smallest, least-fancy solution to getting a text into a manageable form. The library isn’t the most accurate, but it’s an easy, small one that can run everywhere.nlp: It’s a general natural-language utility that supports tokenizing, stemming, classification, string similarity, guessing the language, etc.
The following diagram measures the three NLP packages based on the npm downloads:
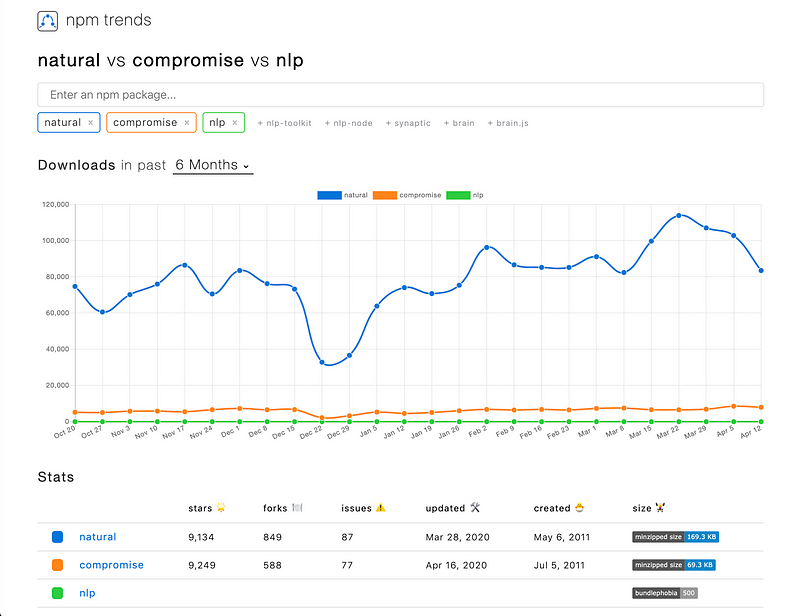
What’s the Capability of Natural?
We’ve chosen natural to explore the capability of NLP. First, install the package: npm install natural.
natural is a Node.js package, not a browser package. Amazingly, we managed to execute it in React components with few warnings.
In order to use the package, the natural module needs to be included:
const natural = require('natural');Tokenizers
A tokenizer breaks up text into an array of tokens. It splits on anything except alphabetic characters, digits, and underscores. There are a number of tokenizers provided, with variations on how the text is split.
const tokenizer = new natural.WordTokenizer();
tokenizer.tokenize('Machine learning is awesome!'));
// ["Machine", "learning", "is", "awesome"]String distance
String distance measures the distance between two strings. There are a number of algorithms provided, with different ways to calculate string distance.
Hamming distance measures the distance between two strings of equal length by counting the number of different characters. The third parameter indicates whether case should be ignored. By default the algorithm is case sensitive.
natural.HammingDistance('AI', 'ai', false);
// 2natural.HammingDistance('AI', 'ai', true);
// 0natural.HammingDistance('AI', 'artificial intelligence', true);
// -1Stemmers
Stemming is the process of reducing inflected or derived words to their word stem, base, or root form. A number of stemmers are supported.
The Porter stemmer is a process for removing the commoner morphological and inflectional endings from words in English.
natural.PorterStemmer.attach();
const sentence = 'A process for removing the commoner morphological and inflexional endings from words in English.';
sentence.tokenizeAndStem();
// ["process", "remov", "common", "morpholog", "inflexion", "end", "word", "english"]Classifiers
A classifier predicts the likely category that a new input belongs to, on the basis of a training set of data that contains observations with known category membership. A number of classifiers are supported.
The Bayes classifier is based on applying the Bayes theorem with strong independence assumptions between the features.
// create a BayesClassifier
const dayAndNightClassifier = new natural.BayesClassifier();// supply a training set of data for two membership: night and day
dayAndNightClassifier.addDocument('Moon is in the sky', 'night');
dayAndNightClassifier.addDocument('I see starts', 'night');
dayAndNightClassifier.addDocument('It is dark', 'night');
dayAndNightClassifier.addDocument('Sun is in the sky', 'day');
dayAndNightClassifier.addDocument('It is bright', 'day');// training
dayAndNightClassifier.train();dayAndNightClassifier.classify("I see a bright Sun");
// new input is classified as dayThe training result can be saved to a JSON file:
dayAndNightClassifier.save('dayAndNightClassifier.json', (err, classifier) => {
if (err) {
throw new Exception(err);
}
console.log(classifier);
});The saved JSON file can be loaded for reuse:
natural.BayesClassifier.load('dayAndNightClassifier.json', null, (err, classifier) => {
if (err) {
throw new Exception(err);
}
console.log(classifier);
});Here’s the content of the saved dayAndNightClassifier.json.
{
"classifier":{
"classFeatures":{
"night":{
"0":2,"1":2,"2":2,"3":2
},
"day":{
"1":2,"4":2,"5":2}
},
"classTotals:{
"night":4,"day":3
},
"totalExamples":6,
"smoothing":1
},
"docs":[
{
"label":"night","text":["moon","sky"]
},
{
"label":"night","text":["start"]
},
{
"label":"night","text":["dark"]
},
{
"label":"day","text":["sun","sky"]
},
{
"label":"day","text":["bright"]
}
],
"features":{
"moon":1,"sky":2,"start":1,"dark":1,"sun":1,"bright":1
},
"stemmer":{},
"lastAdded":5,
"events":{
"_events":{},"_eventsCount":0
}
}The Project
Our project provides a GUI-based service to analyze log files, using knowledge-based AI and NLP to extract and form intelligence to better support customers and increase sales.
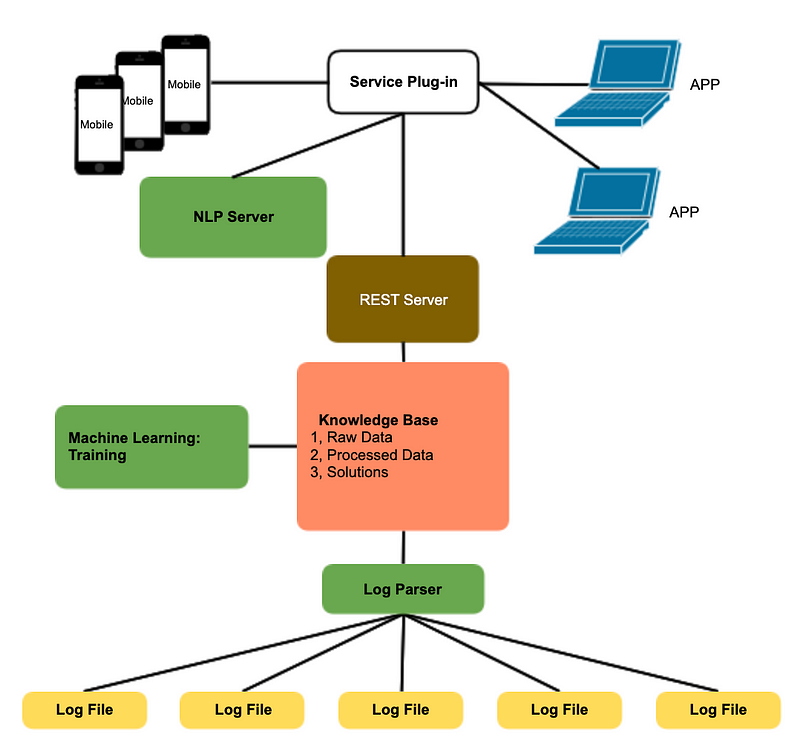
The system provides a number of services:
- Parses raw log files into structured JSON objects
- Builds a knowledge base containing raw data, processed data, and solutions via a machine learning training model
- Provides access to the knowledge base via a REST server
- Provides a GUI front end served by the NLP engine and REST server
This article describes the first part of work: a GUI-based service served by the NLP engine and the REST server.
Log files
A log file is a file that records events and/or alerts that occur while information systems are executing.
Usually, there are multiple log files to tract raw data from various aspects. Log files serve as the source of the knowledge base.
Knowledge Base
A knowledge base is the centerpiece of the project. It’s a centralized data service for spreading information and data.
By collecting, organizing, retrieving, and sharing knowledge, it forms the base for predictive/diagnostic assistance.
REST server
A REST server takes API calls from the GUI’s service module and responds with analytical results from a knowledge base.
This is simplified JSON representation:

NLP server
An NLP server takes natural-language sentences from the GUI’s service module and responds with formatted REST calls to retrieve and structure answers.
nature’s classifier can be trained with tokens, strings, or any mixture of the two. We used token training to classify inputs by two features:
- Log level:
info,warn, orerror - Presentation format: Simple count or with detailed information
const logLevel = new natural.LogisticRegressionClassifier();
logLevel.addDocument('info', 'info');
logLevel.addDocument('information', 'info');
logLevel.addDocument('warn', 'warn');
logLevel.addDocument('warning', 'warn');
logLevel.addDocument('error', 'error');logLevel.train();const presentationFormat = new natural.LogisticRegressionClassifier();
presentationFormat.addDocument('How many', 'count');
presentationFormat.addDocument('number', 'count');
presentationFormat.addDocument('describe', 'detail');
presentationFormat.addDocument('description', 'detail');
presentationFormat.addDocument('detail', 'detail');presentationFormat.train();The GUI
This is the user interface for a user to ask random questions:
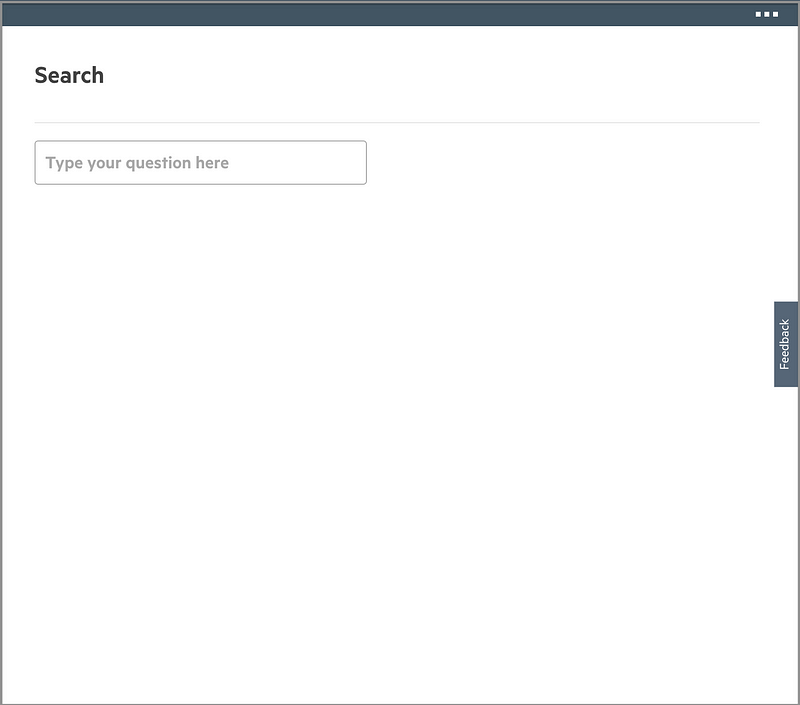
The user can type a natural language–style question:
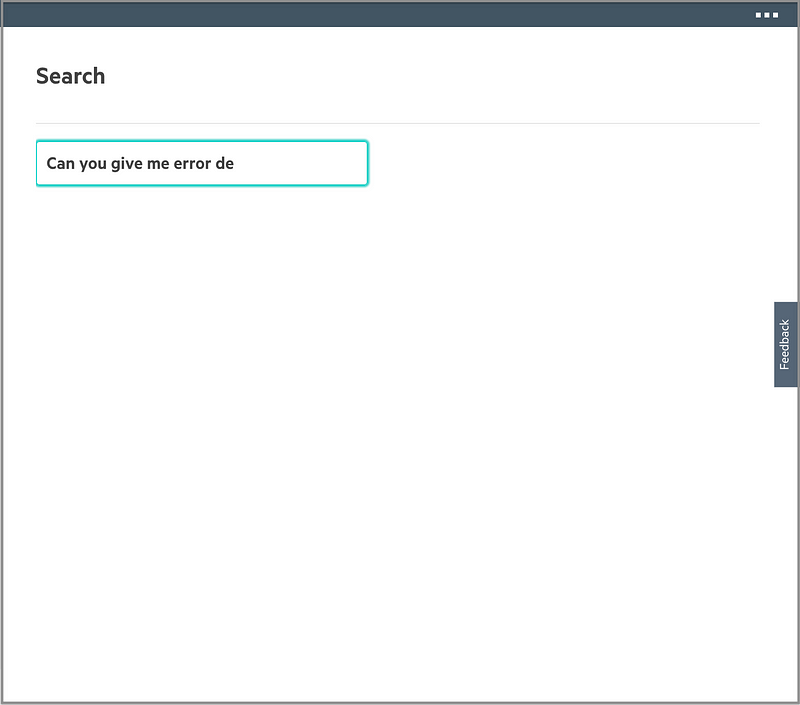
The initial work is limited to a question regarding log level, whether it’s info, warn, or error. Two response formats are supported: a simple count or one with detailed information.
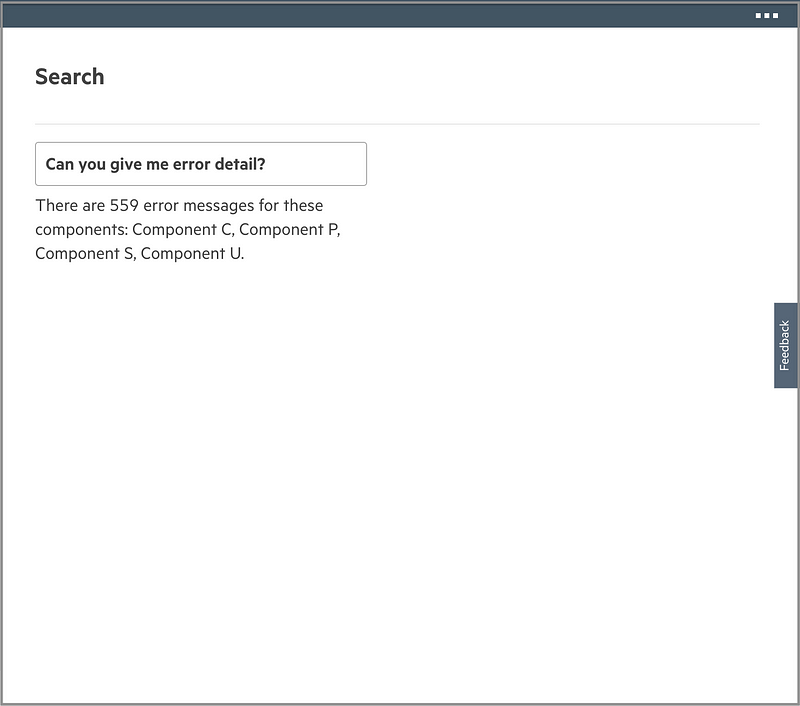
For this question — “Can you give me error detail?” — NLP determines this is asking for detailed information regarding error messages. Then, the GUI responds accordingly.
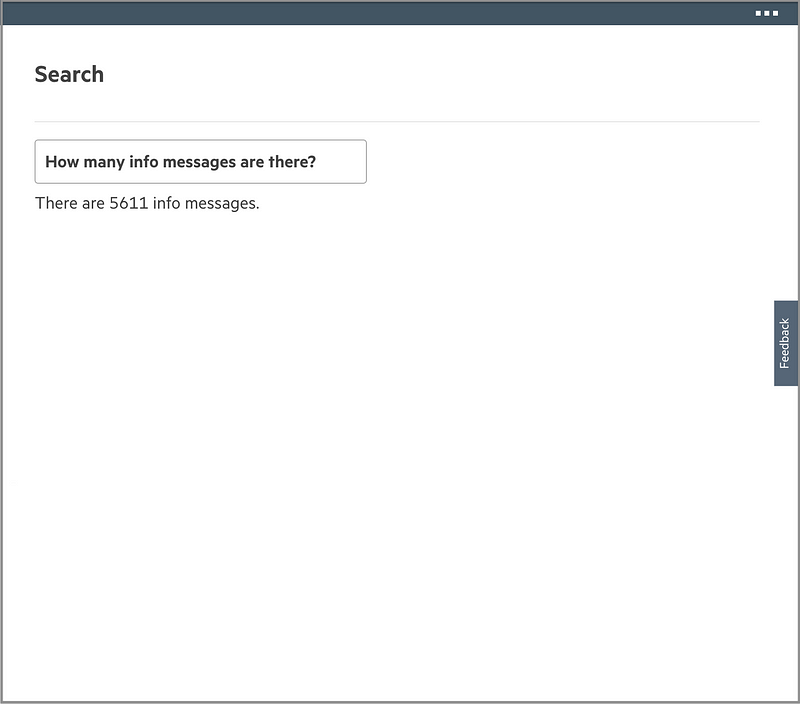
For this question — “How many info messages are there?” — NLP determines this is asking for count information regarding info messages. Then, the GUI responds accordingly.
With limited scope, the natural-language search works quite intelligently.
Conclusion
In 1950, Alan Turing published “Computing Machinery and Intelligence,” in which he proposed the imitation game, which later became known as the Turing Test.
Seventy years have since passed. AI has advanced dramatically, with Alexa talking in the family room, iPhone unlocking by facial recognition, and self-driving cars driving on the road.
On a small scale, you can download an NLP package, natural, compromise, nlp, or something else from GitHub. AI is at your fingertip in a few minutes. Your next big thing could start from here. Do you want to give it a try?
This project has contributions by Jennifer Fu, Astha Sirohi, Darren Wong, Daniel Deng, Victor Zhang, Jonathan Ma, and Steve Strange.
Thanks for reading. I hope this was helpful. You can see my other Medium publications here.





