
National Algorithms — Living With Data-Based Government
Or ‘The Problem with Government-By-Numbers’
A 5-Minuter from Wonk Bridge
Conventional wisdom about the COVID period holds that it’s a good time to be an ecommerce monopolist, a communications facilitator, or the proprietor of an online gaming platform. It also holds that it’s a very bad time to be a tourism-dependent economy, a high-street retail chain, or a traditional educationalist. It is, more broadly, a very bad time to be precariously employed, or old. It is also a very bad time to be young.
As much as to the beleaguered rest, one’s heart goes out to the class of 2019–20, with portion preserved in the instance that it might also need to go out to that of 2020–21. With the reopening of university campuses adjudged high-risk, many prospective first-year students may have to live with the fact of an often superb and always formative rite of passage (oh! To be a fresher) being indefinitely suspended. More troubling than the situation of those who might have to pursue their studies from afar is the case of those who might not get to study at all.
The A-levels results fiasco/debacle/controversy (eliminate according to preference) is one of the UK’s highest profile administrative bahíacochinos of the entire COVID period. The pantomime in short goes like this — the government of the United Kingdom cancelled all examinations for the summer of 2020, including the milestone rounds of GCSEs (for 16-year-olds), A-Levels (for 18-year-olds) and BTECs (a technical/vocational equivalent of the A-Level). This cancellation produced the rather awkward question of how the affected students would be appraised, particularly A-level students relative to their target universities.
The awkward question produced a rushed and makeshift answer — a grades standardisation algorithm, produced by regulator Ofqual at short notice. The algorithm was to take teachers’ respective predictions of student performance and moderate them. It did so by assessing historic grades in the school, examining how prior attainment maps onto final results, and anticipating how this relationship would play out among individual students. Students would then be assigned grades, relative to the school’s target set, based on ranking within these assessments.
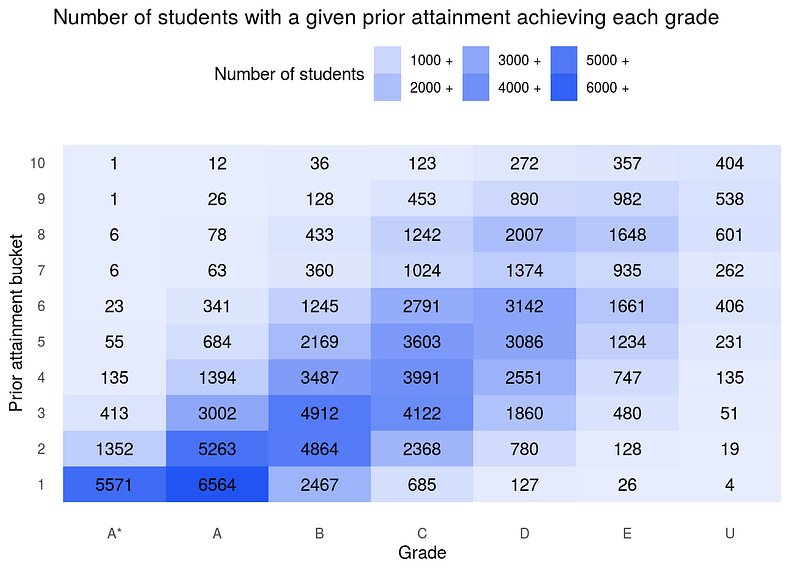
It, by acclamation, radically overperformed in its function to combat grade inflation. Vast numbers of students were regulated negatively against their predicted grades. There was good reason to suggest that independent schools endured fewer downgrades than state schools. Education secretary Gavin Williamson was recalcitrant in the early stages of public outcry, warning of the dangers of unmoderated grading, before coming to be cowed. He agreed to substitute the moderated grades out for the original predictions.
The reversed decision has the exact opposite effect. Where grades had previously been precipitously lower than expectation, now they were more than 10% higher than those awarded last year, the biggest single-year increase in grade award in 25 years.
Governing By Numbers
The data-positive and data-negative approaches produced opposite and equivalent excesses in the UK COVID exam results saga — but the whole deal raises an interest question or three. Does government-by-algorithm work? Do, can, will the public trust such a government? And where have spectacular instances, either in success or unsuccess, of government-by-algorithm been thus far seen?
From a cursory perspective, government-by-algorithm seems like an impersonal extension of the idea of technocracy. Technocracy, a much discussed football frequently brought down to the turf of the political park, broadly involves the deferral of government to those whose skills are not parliamentary or political, but are relative to expertise in technical or scientific terms. For some, technocracy is synonymous with meritocracy; rule by the skilled. For others, it’s synonymous with aristocracy, a kind of éminence grise attributable to such polemical lodestars of the 21st century as the EU or Facebook.
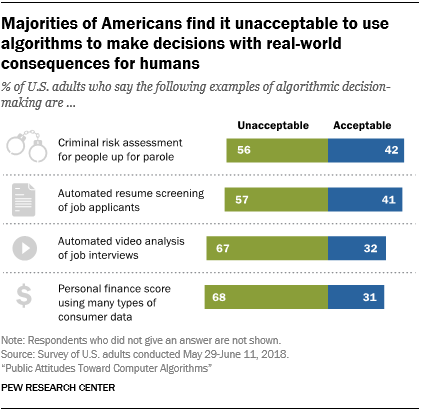
In terms of public perspective, an algorithm-based version of this approach makes the method even less accountable. The public is, and has been for the last several years at least, highly sceptical of the idea of computers holding executive responsibility for large decisions in people’s lives.
There is already a vast amount of AI — founded upon algorithmry — incorporated into, for instance, the United States’ approach to governance. A report by the SLS suggests that “significant federal departments, agencies, and sub-agencies” use AI. Some figures put that number at around 45% of all federal systems in the US. Having said that, reports suggest that only 15% of that AI could be adjudged as highly sophisticated.
So what happens if an algorithm hasn’t got the right rhythm? One idea which has come to critical mass in the last 12–18 months is the idea of algorithmic bias — the notion that, as they are built by the human mind, algorithms can be as myopic and inconclusive in their analysis as their slower, meat-based ancestors. Only perfect data will produce a perfect algorithmic performance. Biased data can fail to remedy, or even exacerbate, existing biases within patterns of historical analysis, like algorithms which continue to drive unrepresentative patterns of incarceration in the US.
Even where algorithms already reign within government, observation finds their use “clustered into activities which focused on regulatory monitoring / analysis, procurement, engagement with the public, and the direct delivery of services.” These activities are ubiquitous in genres of governance like healthcare; such data requires profound delicacy, not only in use but in secure handling, too. It would be no good for an algorithm to be anything other than highly sophisticated, when the stakes go as high as to effect the health of citizens. And yet, according to the likes of David Engstroem, the algorithms being used for just such a purpose were “only [designed] to overcome narrow administrative or bureaucratic problems.”
Formulas of Trust
It is safe to say that the majority of the public are not aware of Engstroem’s conclusions — and it is as safe to say that, intuitively, they have still grasped the potential weaknesses of government-by-algorithm. It is a common problem of software, noted by Jaron Lanier some years ago — that what we use tends to be a by-product of whatever foundation was there to build on. The flaws of that foundation are often perfectly preserved and extended. That goes as much for questions of prejudice as of technology — we cannot really conceive of a machine which can correct our flaws in complex thinking, anymore than we can expect a clerical algorithm to solve issues of complex, multivariate grading, or medical assessment.
What’s more, government-by-algorithm falls foul of a common problem within the public sector — that talent is more enticed by remuneration than by honour. Not only does government-by-algorithm create conflicts of interest, when private companies seek collaboration; government must also make do with less talented engineers, as the best have skills that are in high, well-paid demand.
The appearance of a charter or discrete policy for AI and the use of algorithms in government decision making was received with relief in the United States. It is the beginning of a long period of modernising and regulating the use of algorithms in government. Otherwise, we may look forward to a period in which the incompetence and prejudice our cynicism obliges us expect of our politicians is simply removed from its ill-fitting suit and made operable by button.