
Multi-armed Bandits Part III: Thompson Sampling based on Bayesian Posterior Probability

In previous section: Multi-armed Bandits: What is Upper Confidence Bound (UCB) Algorithm, we achieve a very general estimation based on Hoeffding’s Inequality. This is primarily because we don’t assume any prior on the reward distribution. If we could make some assumption upfront, we would definitely be able to make better bound estimation.
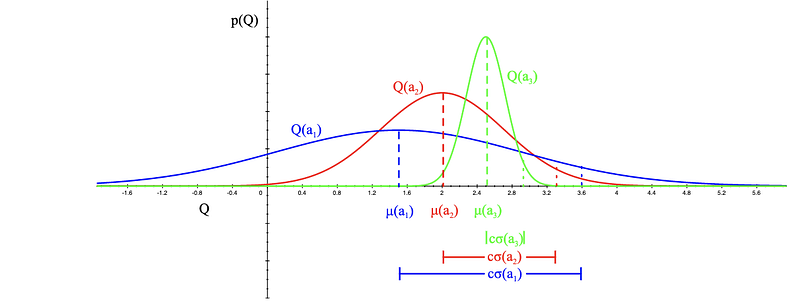
If we expect the mean reward of every slot machine to be Gaussian and independent, we could then set the upper bound as 95% confidence interval by make Ut(a) as 1.96x standard deviation.
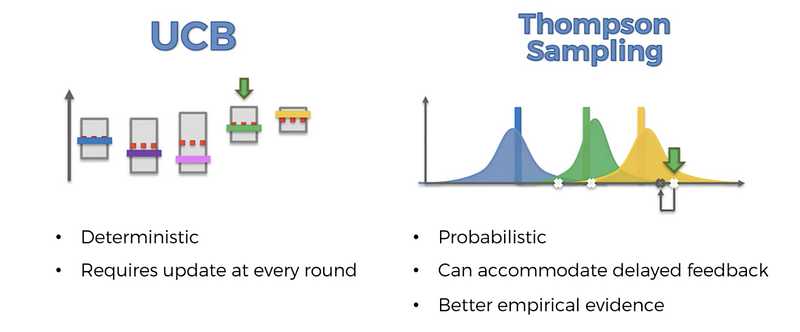
Thompson sampling
Thompson sampling is using a very simple Bayesian idea but it turns out to be very useful to solve the multi-armed bandit problem. Basically at each step, the strategy is going to select an action with optimal probability
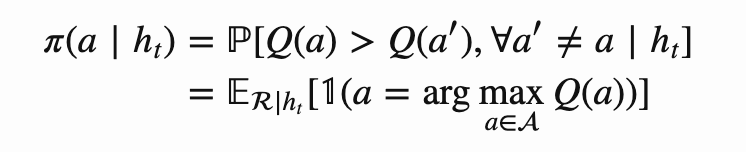
π(a|ht) is the probability of taking action a given the history ht. Here we can use Bayes law to compute posterior distribution P(R | ht).
For the Bernoulli bandit described, it is natural to assume that Q(a) follows a Beta distribution, as Q(a) is essentially the success probability θ in Bernoulli distribution. The value of Beta(α,β) is within the interval [0, 1], and α and β are the counts when we succeeded or failed to get a reward respectively. Because of the beautiful characteristics from Beta distribution, we can update the posterior with the known prior and the likelihood from the sampled data:
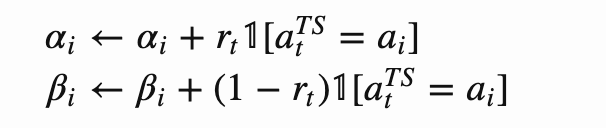
From an engineering perspective, Thompson sampling implements probability matching. Because its reward estimations Q̃ are sampled from posterior distributions, each of these probabilities is equivalent to the probability that the corresponding action is optimal, conditioned on observed history.
Thanks for Reading!
If you enjoyed it, please follow me on Medium for more. It’s great cardio for your 👏 AND will help other people see the story.




