
Monte Carlo Dropout
Improve your neural network for free with one small trick, getting model uncertainty estimate as a bonus.
There ain’t no such thing as a free lunch, at least according to the popular adage. Well, not anymore! Not when it comes to neural networks, that is to say. Read on to see how to improve your network’s performance with an incredibly simple yet clever trick called the Monte Carlo Dropout.

Dropout
The magic trick we are about to introduce only works if your neural network has dropout layers, so let’s kick off with briefly introducing these. Dropout boils down to simply switching-off some neurons at each training step. At each step, a different set of neurons are switched off. Mathematically speaking, each neuron has some probability p of being ignored, called the dropout rate. The dropout rate is typically set to be between 0 (no dropout) and 0.5 (approximately 50% of all neurons will be switched off). The exact value depends on the network type, layer size, and the degree to which the network overfits the training data.
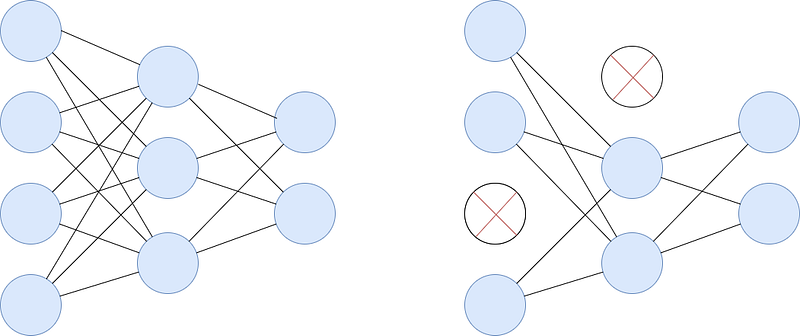
But why do this? Dropout is a regularization technique, that is, it helps prevent overfitting. With little data and/or a complex network, the model might memorize the training data and, as a result, work great on the data it has seen during training but deliver terrible results on new, unseen data. This is called overfitting, and dropout seeks to alleviate it.
How? There are two ways to understand why switching off some parts of the model might be beneficial. First, the information spreads out more evenly across the network. Think about a single neuron somewhere inside the network. There are a couple of other neurons that provide it with inputs. With dropout, each of these input sources can disappear at any time during training. Hence, our neuron cannot rely on one or two inputs only, it has to spread out its weights and pay attention to all inputs. As a result, it becomes less sensitive to input changes which results in the model generalizing better.
The other explanation of dropout’s effectiveness is even more important from the point of view of our Monte Carlo trick. Since in every training iteration you randomly sample the neurons to be dropped out in each layer (according to that layer’s dropout rate), a different set of neurons are being dropped out each time. Hence, each time the model’s architecture is slightly different and you can think of the outcome as an averaging ensemble of many different neural networks, each trained on one batch of data only.
A final detail: dropout is only used during training. At inference time, that is when we make predictions with our network, we typically don’t apply any dropout — we want to use all the trained neurons and connections.
Monte Carlo
Now that we have dropout out of the way, what is Monte Carlo? If you’re thinking about a neighborhood in Monaco, you’re right! But there is more to it.

In statistics, Monte Carlo refers to a class of computational algorithms that rely on repeated random sampling to obtain a distribution of some numerical quantity.
Monte Carlo Dropout: model accuracy
Monte Carlo Dropout, proposed by Gal & Ghahramani (2016), is a clever realization that the use of the regular dropout can be interpreted as a Bayesian approximation of a well-known probabilistic model: the Gaussian process. We can treat the many different networks (with different neurons dropped out) as Monte Carlo samples from the space of all available models. This provides mathematical grounds to reason about the model’s uncertainty and, as it turns out, often improves its performance.
How does it work? We simply apply dropout at test time, that's all! Then, instead of one prediction, we get many, one by each model. We can then average them or analyze their distributions. And the best part: it does not require any changes in the model’s architecture. We can even use this trick on a model that has already been trained! To see it working in practice, let’s train a simple network to recognize digits from the MNIST dataset.
After training for 30 epochs, this model scores the accuracy of 96.7% on the test set. To turn on dropout at prediction time, we simply need to set training=True to ensure training-like behavior, that is dropping out some neurons. This way, each prediction will be slightly different and we may generate as many as we like.
Let’s create two useful functions: predict_proba() generates the desired number num_samples of predictions and averages the predicted class probability for each of the 10 digits in the MNIST dataset, while predict_class() simply chooses the highest predicted probability to pick the most likely class. This and some of the following code snippets are inspired by the ones from Geron (2019). The book is accompanied by a set of excellent jupyter notebooks.
Now, let’s make 100 predictions and evaluate accuracy on the test set.
This yields an accuracy of 97.2%. Compared to the previous result, we have decreased the error rate from 3.3% to 2.8%, which is by 15%, without changing or retraining the model at all!
Monte Carlo Dropout: prediction uncertainty
Let’s take a look at prediction uncertainty. In classification tasks, class probabilities obtained from the softmax output are often erroneously interpreted as model confidence. However, Gal & Ghahramani (2016) show that a model can be uncertain in its predictions even with a high softmax output. We can see it in our MNIST predictions as well. Let’s compare the softmax output with the Monte Carlo Dropout-predicted probabilities for a single test example.
softmax_output: [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
mc_pred_proba: [0. 0. 0.989 0.008 0.001 0. 0. 0.001 0.001 0. ]
Both agree that the test example is most likely from the 3rd class. However, the softmax is 100% sure that’s the case, which should already alert you that something is not right. Probability estimates of 0% or 100% are usually dangerous. Monte Carlo Dropout provides us with much more information about the prediction uncertainty: most likely it’s class 3, but there is a small chance it might be class 4, and 5, although unlikely, is still more probable than 1, for instance.
Monte Carlo Dropout: regression problems
So far, we have talked about a classification task. Let’s now turn to a regression problem to see how Monte Carlo Dropout provides us with prediction uncertainty. Let’s fit a regression model to predict house prices using the Boston housing dataset.
For a classification task, we have defined functions to predict class probabilities and the most likely class. Similarly, for the regression problem, we need functions to get the predictive distribution and a point estimate (let’s use the mean for this).
Let’s again make 100 predictions for one test example and plot their distribution, marking its mean, which is our point estimate, or best guess.
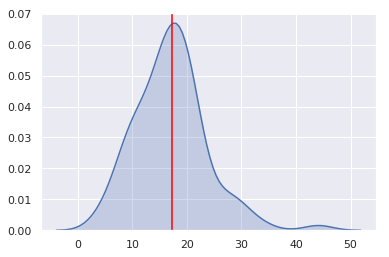
For this particular test example, the mean of the predictive distribution amounts to 18, but we can see that other values are not unlikely — the model is not very certain about its predictions.
Monte Carlo Dropout: an implementation detail
Just one final remark: we have been implementing Monte Carlo Dropout by setting the model’s training mode to true throughout this article. This works well, but it might affect other parts of the model that behave differently at training and inference time, such as batch normalization, for instance. To make sure we only switch on dropout without affecting anything else, we should create a custom MonteCarloDropout layer that inherits from the regular dropout, and has its training parameter set to true by default (the following piece of code has been adapted form Geron (2019)).
Conclusion
- Monte Carlo Dropout boils down to training a neural network with the regular dropout and keeping it switched on at inference time. This way, we can generate multiple different predictions for each instance.
- For classification tasks, we can average the softmax outputs for each class. This tends to lead to more accurate predictions, which additionally express the model’s uncertainty properly.
- For regression tasks, we can analyze the predictive distribution to check which values are likely or summarize it using its mean or median.
- Monte Carlo Dropout is very easy to implement in TensorFlow: it only requires setting a model’s
trainingmode totruebefore making predictions. The safest way to do so is to write a custom three-liner class inheriting from the regular Dropout.
Sources
- Gal Y. & Ghahramani Z., 2016, Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning, Proceedings of the 33rd International Conference on Machine Learning
- Geron A., 2019, 2nd edition, Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
Thanks for reading!
If you liked this post, why don’t you subscribe for email updates on my new articles? And by becoming a Medium member, you can support my writing and get unlimited access to all stories by other authors and yours truly.
Want to always keep your finger on the pulse of the increasingly faster-developing field of machine learning and AI? Check out my new newsletter, AI Pulse. Need consulting? You can ask me anything or book me for a 1:1 here.
You can also try one of my other articles. Can’t choose? Pick one of these:




