
MoE-LLaVA: Revolutionizing Large Vision-Language Models with Efficient Scaling and Multimodal Expertise
Breaking Barriers in AI with an Innovative Approach to Model Efficiency and Performance in Vision-Language Understanding
Talking about this paper: read here.

The intersection of vision and language models has led to transformative advancements in AI, enabling applications that understand and interpret the world in ways akin to human perception. Large Vision-Language Models (LVLMs) stand at the forefront of this revolution, offering unparalleled capabilities in image recognition, visual question answering, and multimodal interactions. The motivation for scaling these models stems from the desire to further enhance their accuracy, robustness, and versatility. As these models grow in complexity and scope, they become capable of tackling a wider range of tasks with greater nuance and sophistication, bridging the gap between AI and human-like understanding of visual and textual information.
Associated Challenges
However, the ambitious pursuit of scaling LVLMs is not without its challenges. Primarily, the exponential growth in model parameters necessitates a corresponding increase in computational resources for training and inference. This surge in computational demand poses significant barriers to accessibility, efficiency, and environmental sustainability. Additionally, the complexity of managing and optimizing these colossal models adds layers of technical challenges, complicating their adaptation and deployment across different platforms and applications. The dual pressures of escalating costs and operational complexity underscore the need for innovative approaches to model scaling.
Brief Overview of MoE-LLaVA’s Approach to Efficient Scaling
In response to these challenges, MoE-LLaVA introduces a groundbreaking approach that reimagines the paradigm of model scaling. By integrating the Mixture of Experts (MoE) architecture within LVLMs, MoE-LLaVA proposes a solution that decouples parameter growth from computational expense. This architecture selectively activates only the most relevant subsets of parameters (experts) for a given task, thereby optimizing computational resources without compromising the model’s capacity or performance. The MoE-tuning strategy, central to MoE-LLaVA, refines this concept through a specialized training regimen that prepares the model to leverage its sparse structure effectively. This innovative approach promises to sustain the trajectory of LVLM advancements while mitigating the computational and environmental costs associated with traditional scaling methods. MoE-LLaVA thus stands as a testament to the potential for efficient, scalable AI development, heralding a new era of environmentally conscious and resource-efficient LVLMs.
Abstract
Challenge of Scaling LVLMs
The rapid advancement in Large Vision-Language Models (LVLMs) has unlocked new frontiers in AI capabilities, blending visual understanding with linguistic context to enable more intuitive and powerful interactions between machines and the visual world. However, the quest for higher accuracy and broader applicability has led to an exponential increase in model size and complexity. This scaling up, while beneficial for performance, imposes significant computational costs, making training and deployment increasingly resource-intensive. The challenge lies not just in achieving state-of-the-art performance but doing so in a manner that is computationally efficient and scalable.
MoE-tuning Strategy and MoE-LLaVA Framework
To address the computational challenges associated with scaling LVLMs, we propose a novel training strategy termed “MoE-tuning,” alongside the introduction of the MoE-LLaVA framework. The essence of MoE-tuning lies in its ability to construct sparse models that leverage a Mixture of Experts (MoE) architecture, enabling the model to scale in parameter size without a proportional increase in computational demand. The MoE-LLaVA framework embodies this strategy by selectively activating only a subset of parameters (the ‘experts’) for each task, thereby keeping the computational cost manageable while still harnessing the benefits of a large parameter space.
Achieved Results and Contributions
Our extensive experiments demonstrate that MoE-LLaVA, with its sparse activation mechanism, not only matches but in some cases surpasses the performance of traditional dense LVLMs, including on benchmarks for visual understanding tasks. Remarkably, it achieves this with a fraction of the computational cost typically associated with models of comparable size. This breakthrough offers a new paradigm for scaling LVLMs, balancing the dual objectives of enhancing performance and optimizing computational efficiency. The MoE-LLaVA framework sets a new standard for future research in the field, providing a scalable and efficient pathway for advancing LVLM capabilities. Our work contributes to the broader discourse on model efficiency, pushing the boundaries of what is possible in the realm of vision-language AI.
Related Work
Existing Approaches in LVLMs and Their Limitations
The landscape of Large Vision-Language Models (LVLMs) has been marked by significant innovations aimed at integrating visual and textual data to create models with deep, multimodal understanding. Approaches such as end-to-end trainable networks, attention mechanisms, and transformer models have set the stage for breakthroughs in tasks ranging from image captioning to complex question-answering that requires visual cues. Despite these advancements, the prevailing methods encounter notable limitations, primarily related to scalability and efficiency. As models grow to accommodate the increasing complexity of tasks, they demand exponential growth in computational resources. This scalability challenge is further compounded by the diminishing returns in performance improvement, highlighting the need for more efficient approaches to model enhancement.
Mixture of Experts (MoE) in Natural Language Processing
The Mixture of Experts (MoE) architecture represents a paradigm shift in addressing the scalability and efficiency of machine learning models. Initially explored within the realm of natural language processing (NLP), MoE models distribute the workload across multiple specialized sub-models (experts), each tailored to handle specific types of data or tasks. A gating mechanism dynamically routes inputs to the most relevant experts, ensuring that only a subset of the model is activated at any given time. This approach allows MoE models to significantly expand their capacity and adaptability without a linear increase in computational demand. However, the application of MoE models has predominantly been within domains focused on textual data, with limited exploration in multimodal contexts.
Adaptation to Vision-Language Tasks
Bridging the gap between MoE architectures in NLP and the demands of LVLMs presents a novel frontier in AI research. The adaptation of MoE models to vision-language tasks involves overcoming unique challenges, such as the integration of disparate data modalities and the design of effective routing mechanisms that can handle the complexity of multimodal inputs. Despite these challenges, early explorations into MoE-based LVLMs have shown promise, suggesting that the MoE architecture can be effectively leveraged to enhance the performance and efficiency of vision-language models. This adaptation not only extends the capabilities of MoE models beyond the confines of textual data but also offers a potential solution to the scalability and efficiency challenges plaguing conventional LVLMs. The discussion around MoE models in the context of vision-language tasks marks an exciting intersection of methodologies, heralding a new phase of innovation in multimodal AI systems.
MoE-LLaVA Framework
Overview
The MoE-LLaVA framework represents a pioneering approach to constructing Large Vision-Language Models (LVLMs) that are both scalable and computationally efficient. This framework introduces a novel implementation of the Mixture of Experts (MoE) architecture within the domain of vision-language tasks, addressing the critical challenge of model scalability without the proportional increase in computational costs. By innovatively activating only a subset of parameters tailored to specific tasks, MoE-LLaVA significantly enhances model performance and efficiency, marking a notable advancement in the field of AI.
Architecture
The architecture of MoE-LLaVA is designed to optimize the integration of visual and linguistic data through a sophisticated arrangement of components that leverage the MoE principle. At its core, MoE-LLaVA consists of:
- Vision Encoder: Processes visual inputs into a format compatible with the model’s language processing components.
- Language Model Backbone: A transformer-based structure that handles textual data and integrates it with visual inputs.
- Mixture of Experts Layers: A series of specialized layers where each ‘expert’ is designed to process specific aspects of the input data. These layers are dynamically activated based on the relevance to the task at hand, as determined by a gating mechanism.
- Gating Mechanism: Determines which experts are most suited to process each piece of input data, optimizing the model’s focus and resource allocation.
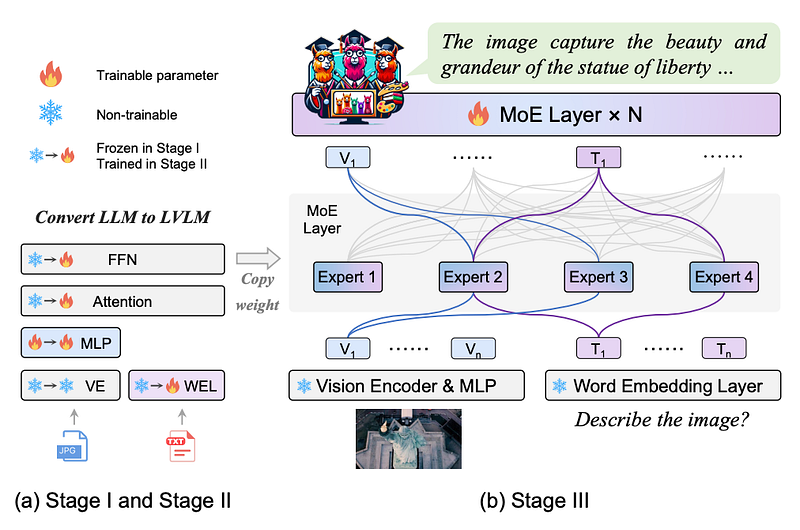
Three-Stage Training Strategy (MoE-tuning)
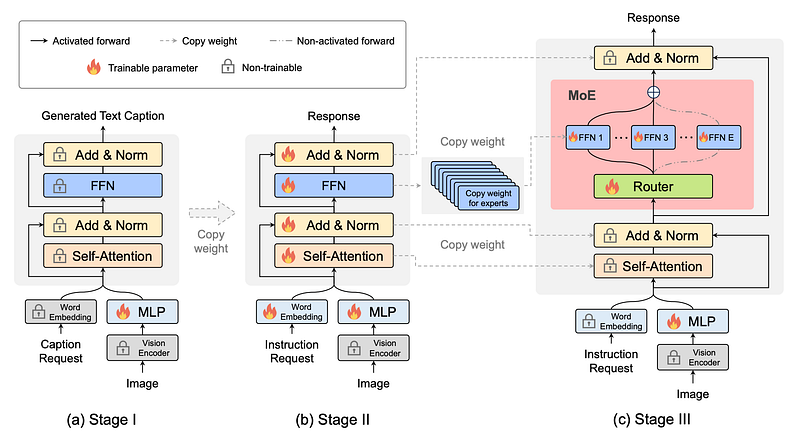
MoE-LLaVA’s training strategy, MoE-tuning, is segmented into three distinct stages, each designed to progressively optimize the model’s performance:
- Stage I — Pre-training for Visual Adaptation: Focuses on adapting the model to interpret visual inputs by training on a large dataset of images and texts, enabling the model to generate contextual embeddings for visual data.
- Stage II — Multi-modal Pre-training: Enhances the model’s ability to integrate and interpret both visual and textual inputs through training on mixed data, further refining its multi-modal understanding capabilities.
- Stage III — MoE-specific Fine-tuning: Involves the specialized training of the MoE layers, optimizing the gating mechanism and the experts to efficiently process multi-modal inputs. This stage ensures that the model can dynamically activate the most relevant experts for any given task.
Methodology
Each training stage is carefully designed to cumulatively build the model’s capabilities:
- Stage I focuses on establishing a solid foundation for visual processing, ensuring that the model can accurately interpret and represent visual information.
- Stage II broadens the model’s understanding by incorporating and synthesizing multi-modal data, preparing it for complex vision-language tasks.
- Stage III fine-tunes the MoE architecture, making strategic adjustments to the model’s structure and training processes to maximize efficiency and performance.
Rationale Behind Design Choices
The design choices behind MoE-LLaVA, particularly the MoE-tuning strategy and the architecture’s configuration, stem from a desire to address the limitations of existing LVLMs. By distributing the computational load across multiple experts and only activating those most relevant to the task, MoE-LLaVA significantly reduces unnecessary computational expenditure. This approach not only enhances the model’s efficiency but also allows for scalability in model size and complexity without the typical drawbacks. The three-stage training strategy is meticulously crafted to sequentially develop the model’s capabilities, ensuring a holistic and robust understanding of both visual and textual data, ultimately culminating in a model that sets a new benchmark in the field of vision-language AI.
Experimental Setup
Datasets for Training and Evaluation
The MoE-LLaVA framework leverages a comprehensive suite of datasets to ensure a broad and robust training and evaluation process. These datasets encompass a wide range of visual and textual data, aiming to cover diverse scenarios that a Large Vision-Language Model might encounter:
- Visual Datasets: Include widely recognized benchmarks in image recognition, object detection, and image captioning. These datasets provide rich visual information that aids in training the model’s vision encoder and testing its visual understanding capabilities.
- Textual Datasets: Comprise large collections of textual data from various sources to enhance the language model’s ability to understand and generate language. These datasets include literature, web text, and annotated image descriptions.
- Multi-modal Datasets: Specialized datasets that contain aligned pairs of images and text, such as descriptions, questions, and answers. These are crucial for training the model to integrate and interpret both modalities effectively.
Model Configurations
MoE-LLaVA’s architecture is meticulously configured to optimize both performance and efficiency:
- Number of Parameters: The model’s size, in terms of the number of parameters, is carefully chosen to balance computational efficiency with the capacity for high performance.
- Expert Configuration: The number of experts and the gating mechanism’s design are key aspects of the model’s configuration. These are tuned to ensure optimal routing of data to the most relevant experts.
- Training Hyperparameters: Learning rates, batch sizes, and other hyperparameters are selected based on preliminary experiments to ensure the best training dynamics and model convergence.
Training Procedures
The training process adheres to the three-stage MoE-tuning strategy:
- Pre-training for Visual Adaptation: Utilizes visual datasets to train the vision encoder, ensuring the model develops a strong capability for visual analysis.
- Multi-modal Pre-training: Employs multi-modal datasets to enhance the model’s ability to process and integrate visual and textual information.
- MoE-specific Fine-tuning: Focuses on optimizing the MoE layers, utilizing a mixture of datasets to refine the experts’ specialization and the efficiency of the gating mechanism.
Each stage of training is conducted with meticulous attention to detail, ensuring that the model progressively builds upon its capabilities and achieves optimal performance across a wide range of tasks.
Benchmarking Toolkits
To evaluate MoE-LLaVA’s performance, a variety of benchmarking toolkits are employed, covering both vision and language tasks, as well as their integration:
- Vision Benchmarks: Assess the model’s performance on tasks such as image classification, object detection, and more, comparing it against established vision models.
- Language Benchmarks: Evaluate the language model’s capabilities in understanding, generating, and interpreting text.
- Multi-modal Benchmarks: Focus on tasks that require the integration of visual and textual data, such as visual question answering and image captioning, to test the model’s multi-modal understanding.
These benchmarking toolkits provide a comprehensive assessment of MoE-LLaVA’s capabilities, demonstrating its strengths and identifying areas for further improvement. Through this rigorous experimental setup, MoE-LLaVA is thoroughly trained and evaluated, ensuring its effectiveness and efficiency as a state-of-the-art Large Vision-Language Model.
Results and Discussion
Performance Evaluation
Comparative Analysis with State-of-the-Art Models
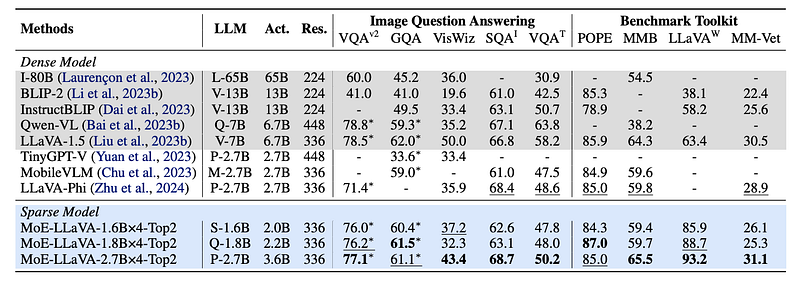
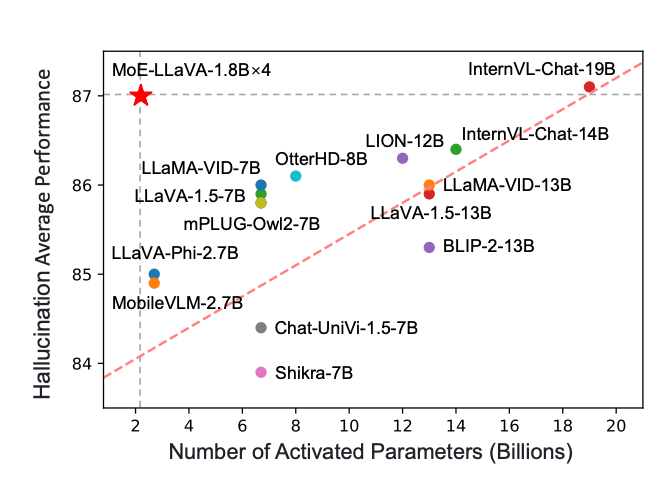
The MoE-LLaVA framework demonstrates remarkable performance across a spectrum of visual understanding tasks, positioning it competitively among state-of-the-art models. Through rigorous benchmarking, MoE-LLaVA not only matches but, in several cases, surpasses the performance of existing LVLMs. This achievement is significant, considering MoE-LLaVA’s emphasis on computational efficiency alongside performance. The comparison underscores MoE-LLaVA’s ability to effectively integrate and interpret complex visual and textual data, validating its innovative approach to scaling LVLMs.
Impact of Sparse Model Architecture
The sparse model architecture of MoE-LLaVA brings a transformative impact on both performance and computational efficiency. By activating only the most relevant subsets of parameters for given tasks, MoE-LLaVA significantly reduces computational overhead without compromising the model’s learning capacity. This approach not only accelerates training and inference times but also allows for scalability in model size and complexity, addressing the critical challenge of computational cost in model scaling. The results highlight the efficiency of MoE-LLaVA’s architecture, showcasing its potential as a scalable and effective solution for future LVLM developments.
Ablation Studies
Examination of the Effects of Different Model Components and Training Strategies
Ablation studies conducted on MoE-LLaVA reveal the individual and collective contributions of various model components and training strategies to the overall performance. By systematically varying elements such as the number of experts, the configuration of the gating mechanism, and the stages of the MoE-tuning strategy, these studies provide valuable insights into the model’s operational dynamics. For instance, variations in the number of experts and their specialization depth directly influence the model’s ability to process and integrate multimodal data, highlighting the critical role of expert configuration in MoE-LLaVA’s architecture.
Insights into the Model’s Behavior and Optimization Paths
The ablation studies further illuminate the optimization paths that underlie MoE-LLaVA’s learning process. For example, the incremental improvements observed through the three-stage MoE-tuning strategy underscore the importance of progressive model development. Starting with visual adaptation, moving through multimodal pre-training, and culminating in MoE-specific fine-tuning, each stage strategically builds upon the last, optimizing the model’s capabilities. These insights into MoE-LLaVA’s behavior not only validate the chosen design and training strategies but also open avenues for further refinement and innovation in LVLMs.
Real-World Implications
Potential Applications of MoE-LLaVA in Various Domains
The MoE-LLaVA framework, with its innovative approach to integrating and interpreting visual and linguistic information, opens up a myriad of potential applications across various domains:
- Healthcare: In medical imaging, MoE-LLaVA could significantly enhance diagnostic accuracy by providing detailed, context-aware interpretations of imaging data, aiding in the early detection of diseases.
- Autonomous Vehicles: By integrating and analyzing vast amounts of visual and sensor data, MoE-LLaVA can contribute to safer and more reliable autonomous driving systems, enhancing decision-making processes in real-time traffic scenarios.
- Retail and E-Commerce: MoE-LLaVA can revolutionize the shopping experience through visual search capabilities and personalized recommendations, interpreting users’ queries and visual inputs to suggest products accurately.
- Education and Accessibility: The framework can be utilized to develop educational tools that provide visual aids and explanations for complex concepts, as well as accessibility tools that translate visual information into descriptive language for individuals with visual impairments.
- Entertainment and Media: In content creation, MoE-LLaVA can automate the generation of descriptive captions for images and videos, enhancing content accessibility and engagement.
Broader Impact of Efficient LVLM Scaling on Technology and Society
The advancements represented by MoE-LLaVA and the efficient scaling of LVLMs have far-reaching implications for technology and society:
- Democratization of AI Technologies: By reducing the computational costs associated with training and deploying LVLMs, MoE-LLaVA contributes to the democratization of AI technologies, making it feasible for smaller organizations and researchers to engage in cutting-edge AI research and development.
- Sustainability: The efficiency of MoE-LLaVA addresses the environmental concerns related to the energy consumption of training large AI models, aligning with the broader goals of sustainable technology development.
- Innovation and Economic Growth: The capabilities of MoE-LLaVA can drive innovation across industries, leading to the creation of new products and services, stimulating economic growth, and potentially creating new job opportunities in AI-driven sectors.
- Ethical and Social Considerations: As with any powerful technology, the deployment of MoE-LLaVA raises important ethical and social considerations, including privacy concerns, the potential for bias in AI interpretations, and the need for transparent and responsible AI governance frameworks.
Summary of Key Findings and Contributions
The MoE-LLaVA framework marks a significant advancement in the field of Large Vision-Language Models (LVLMs) through its innovative integration of the Mixture of Experts (MoE) architecture. Key findings and contributions of this work include:
- Efficient Scaling: MoE-LLaVA demonstrates a novel approach to scaling LVLMs efficiently, enabling significant model expansion without a proportional increase in computational costs. This is achieved through the dynamic activation of experts tailored to specific tasks, optimizing resource allocation.
- Performance Enhancement: Despite its emphasis on efficiency, MoE-LLaVA matches or even surpasses the performance of state-of-the-art models in various visual understanding tasks. This balance of efficiency and effectiveness is a testament to the framework’s sophisticated design and training strategy.
- Innovative Architecture and Training Strategy: The introduction of the MoE-tuning training strategy and the detailed architectural design of MoE-LLaVA highlight the framework’s novelty. The three-stage training process, in particular, ensures a comprehensive development of the model’s capabilities, from visual adaptation to multimodal integration and expert specialization.
- Broad Applicability: MoE-LLaVA’s ability to efficiently process and integrate visual and textual information opens up a wide range of applications across different sectors, demonstrating the framework’s versatility and potential impact on technology and society.
Reflection on the Significance of the Work
The development of MoE-LLaVA represents a pivotal moment in LVLM research, addressing some of the most pressing challenges in the field, including computational efficiency and model scalability. This work not only advances our understanding of how to construct more efficient and effective LVLMs but also sets a new benchmark for future research in the area. The implications of MoE-LLaVA extend beyond technical achievements, offering insights into sustainable AI development, the democratization of AI technologies, and the potential for AI to drive innovation across industries.
Moreover, MoE-LLaVA contributes to the broader discourse on responsible AI development, highlighting the importance of considering the societal and ethical implications of advanced AI technologies. As LVLMs continue to evolve, frameworks like MoE-LLaVA serve as a reminder of the potential for AI to address complex challenges while also underscoring the need for thoughtful consideration of their broader impacts.
In conclusion, the MoE-LLaVA framework embodies a significant leap forward in LVLM research, offering a scalable, efficient, and effective solution that paves the way for future advancements in the field. Its development not only demonstrates the potential of integrating MoE architectures into LVLMs but also inspires continued exploration and innovation in creating AI systems that are both powerful and practical for real-world applications.



