
Model-Based Reinforcement Learning (MBRL) — Part 4
Let’s continue from where we left off.
So far, we used policy (background) or decision-time planners to make a decision and generate trajectory and actions.
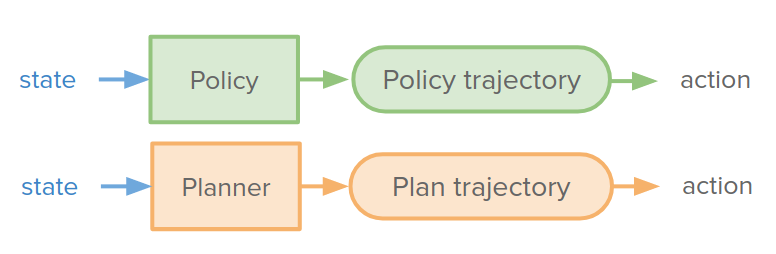
But we can combine them and use the planner as policy improvement. We can use the policy to provide some information for the planner. For example, the policy can output its set of trajectories, and the planner can use it as a warm start or initialization to improve upon. We would like to train the policy such that the improvement proposed by the planner has no effect. So the policy trajectory is the best that we can do. I think we can see the planner as a teacher for the policy.
Some related papers are listed here:
- Silver et al (2017). Mastering the game of Go without human knowledge.
- Levine et al (2014). Guided Policy Search under Unknown Dynamics.
- Anthony et al (2017). Thinking Fast and Slow with Deep Learning and Tree Search.
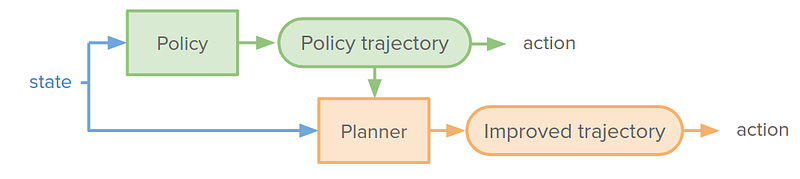
In addition, to use a planner to improve policy trajectory, we can put the planner as a component inside the policy network and train end-to-end.
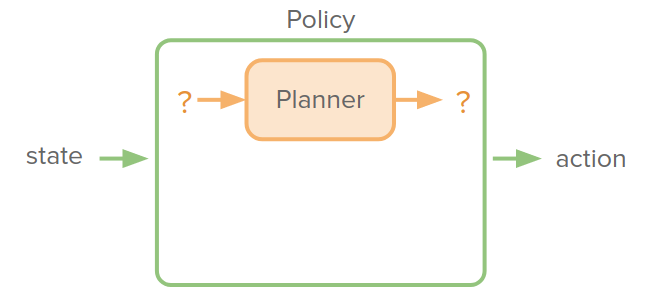
The advantage of doing this is that the policy network dictates abstract state/action spaces to plan in. But the downside of this is that it requires differentiating through the planning algorithm. But the good news is that multiple algorithms we’ve seen have been made differentiable and amenable to integrating into such a planner.
some examples are as follows:
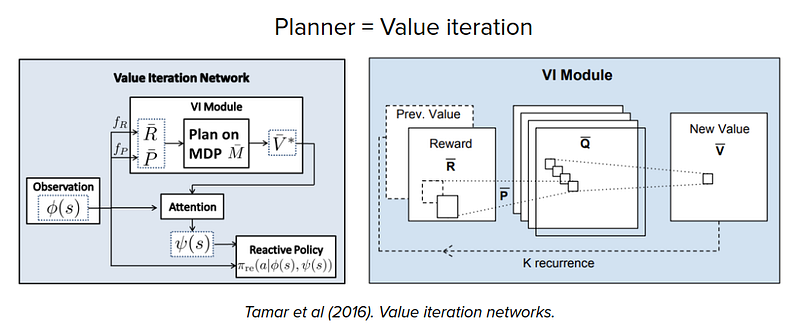
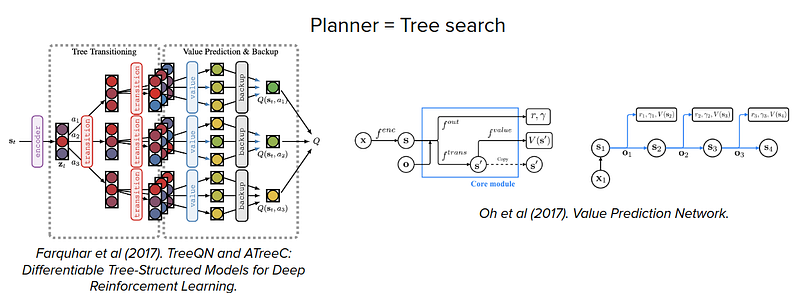
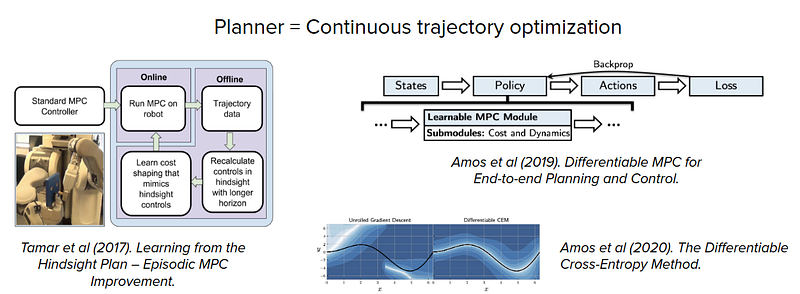
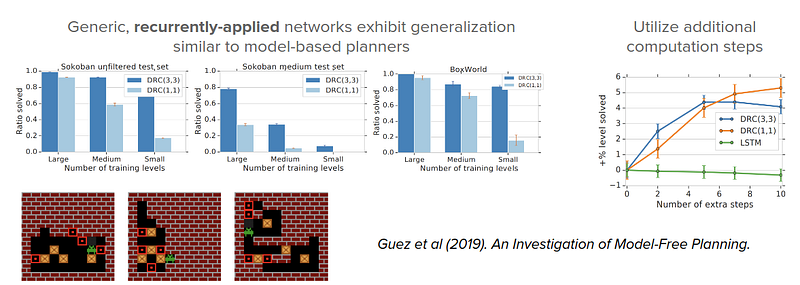
There are also some works that show that planning could emerge in generic black-box policy networks and model-free RL training.
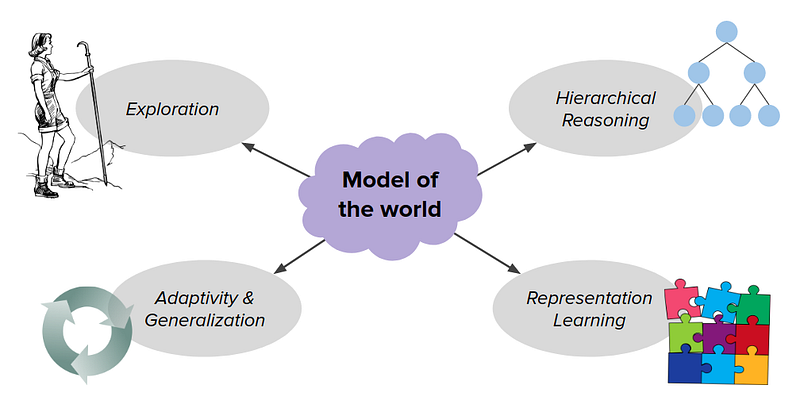
Consider we have a model of the world. We can use the model in a lot of different ways like:
- Exploration
- Hierarchical Reasoning
- Adaptivity & Generalization
- Representation Learning
- Reasoning about other agents
- Dealing with partial observability
- Language understanding
- Commonsense reasoning
- and more!
Here we’re gonna just focus on the first four ways that we can use the model to encourage better behavior.
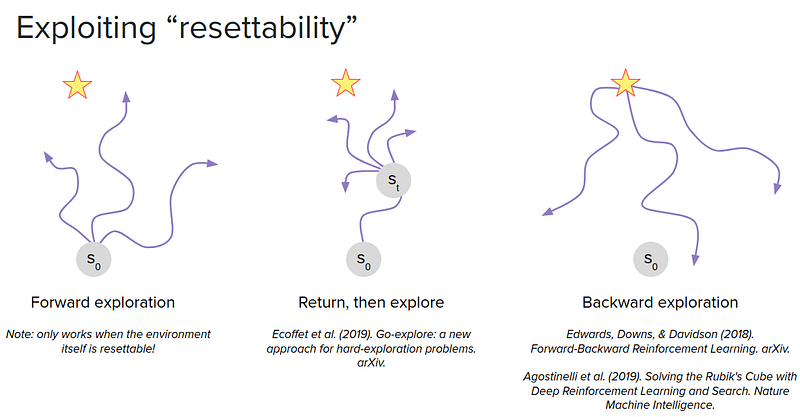
One of the good things about having a model of the world is that you can reset to any state in the world that you might care about. It’s not possible in all environments to reset like a continual learning problem. But if you have the model of the world, you can reset it to any state you want.
We can also consider resetting to intermediate states in the middle of the episode as a starting point. The idea is to keep track of one of the interesting states and does exploration from there. So if you have the world’s model, you can again reset to that state and efficiently perform additional explorations.
You can also reset from the final state rather than the initial state. This can be useful in situations where there is only a single goal state like Rubik’s Cube. In this case, there is only one goal but maybe several possible starting states. So it would be useful to reset to the final state and explore backward from there rather than starting from the initial state.
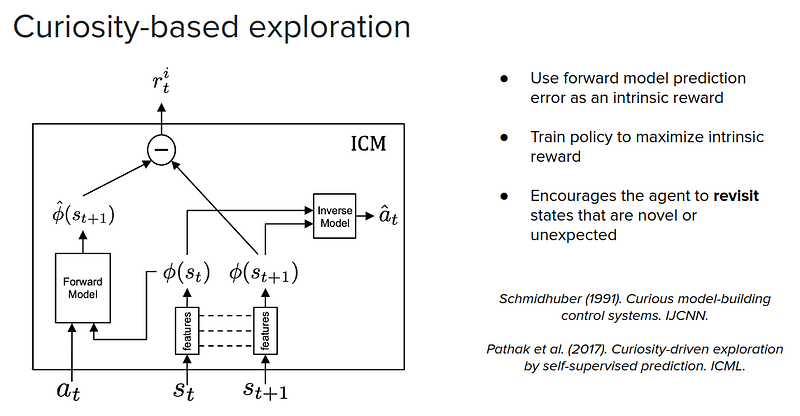
Another way that models can be used to facilitate exploration is by using an intrinsic reward. In these cases, we want to explore places that we haven’t been much so that we can gather data in those locations and learn more about them. One way to identify where we haven’t been is to use model prediction error as a proxy. Basically, we learn a world model, then we predict what the next state is going to be, and then take action and observe the next state and compare it with the predicted state and calculate the model error. We can then use this prediction error as a signal in the intrinsic reward to encourage the agent to explore the locations we haven’t visited often to learn more about them.
In addition to the above approach, we can also plan to explore. In the POLO paper, rather than using the error from your prediction model, they use the error across an ensemble of value functions and use it as an intrinsic reward. Actually, at each state, we compute a bunch of different values from our ensemble of value functions, then take softmax over them to give us an optimistic estimate of what the value is going to be. We can use this optimistic value estimate as an intrinsic reward. We plan to maximize this optimistic value estimate, and then this allows us to basically, during planning, identify places that we should direct our behavior towards that are more surprising or more interesting.
- Compute intrinsic reward during (decision-time) planning to direct the agent into new regions of state-space
- Intrinsic reward = softmax across an ensemble of value functions
$$ \hat{V}(s) = log(\sum_{k=1}^K exp(k\hat{V}_{\theta_k}(s))) $$
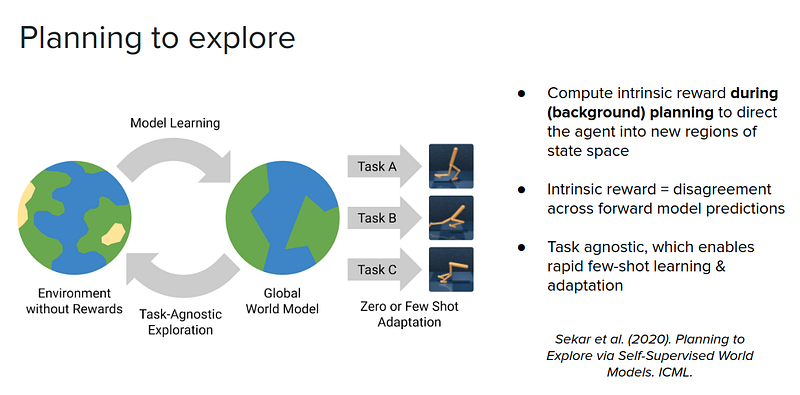
We can also use the same idea, but instead of using a set of disagreements across an ensemble of value functions, we can compute disagreement across transition functions. Now because we are just using state transitions, this turns into a task-agnostic exploration problem. We can then plan where there is a disagreement between our transition functions and direct behavior towards those regions of space to learn a really robust world model. And then use this model of the world to learn new tasks either using zero-shot or few-shot (examples of experience).
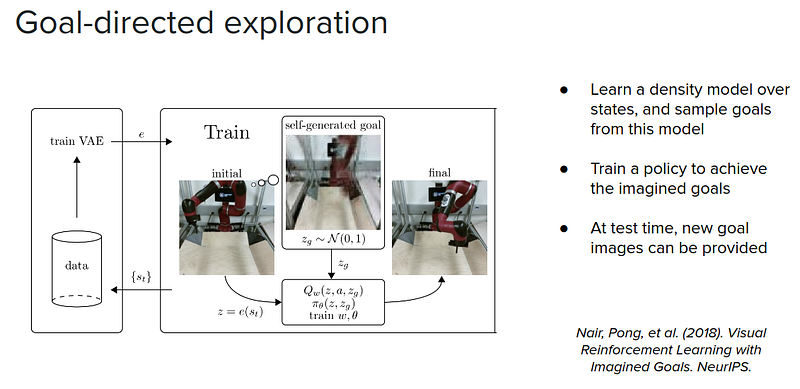
Finally, another form of exploration is that if we have a model of possible states that we might find ourselves in, not necessarily a transition model but a density model over goals, we can sample possible goals from this density model and then train our agent to achieve the goals.
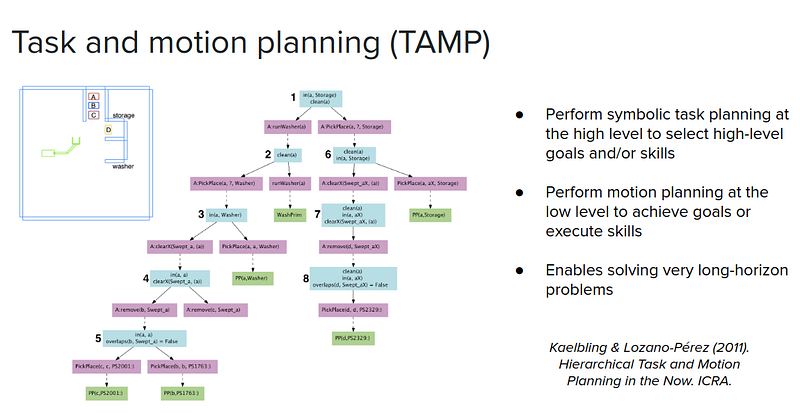
A very classic way of doing hierarchical reasoning is what’s called task and motion planning (TAMP) in robotics. You jointly plan symbolically at the task level, and then you also plan in the continuous space and do motion planning at the low-level-you sort of do these things jointly in order to solve relatively long-horizon and multi-step tasks. For example, in the following figure, to control a robot arm and to get block $A$ and put it in the washer, wash it, and then put it in storage. In order to do this, you first have to move $C$ and $B$ out of the way and put $A$ into the washer, then move $D$ out of the way and then put $A$ into the storage. Leveraging symbolic representation, like PDDL from the beginning of the post, allows you to be able to jointly solve these hierarchical tasks.
The other example of this is the OpenAI Rubik’s Cube solver. The idea is that you use a high-level symbolic algorithm, Kociemba’s algorithm, to generate the solution (plan) of high-level actions, for example, which faces should be rotated, and then you have a low-level neural network policy that generates the controls needed to achieve these high-level actions. This low-level control policy is quite challenging to learn.
The question that might arise is where does this high-level state space come from?
We don’t want to hand-code symbolically on these high-level roles that we want to achieve. Some model-free works try to answer this, but we focus on some MBRL approaches here for this problem.
We can consider any state you might find yourself in in the world as a subgoal. We don’t want to construct a super long sequence of states to go through, but a small sequence. So the idea would be which states we pick as a subgoal. Rather than learning a forward state transition model, we can learn a universal value function approximator, $V(s, g)$, that tells us the value of going from state $s$ to goal state $g$. We can train these value functions between our subgoals to estimate how good a particular plan of length $k$ is. A plan of length $k$ is then given by maximizing:
$$ \text{arg}\max_{\{s_i\}_{i=1}^k} (V(s_0, s_1) + V(s_k, s_g) + \sum_{i=1}^{k-1} V(s_i, s_{i+1})) $$
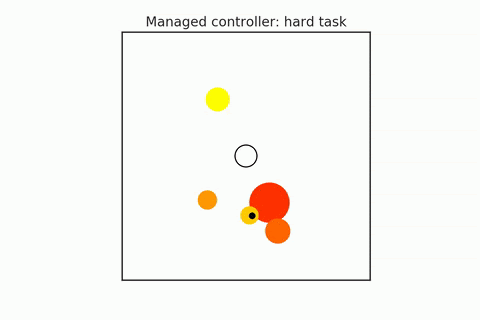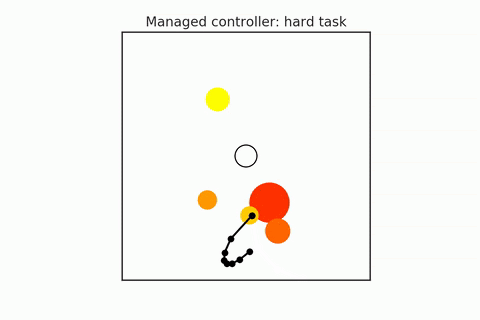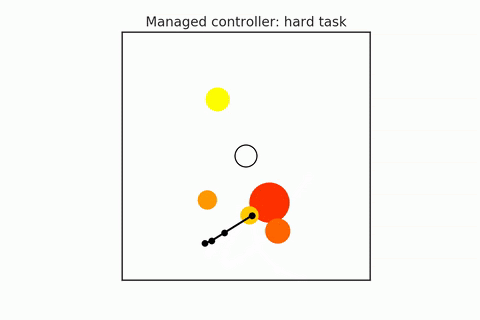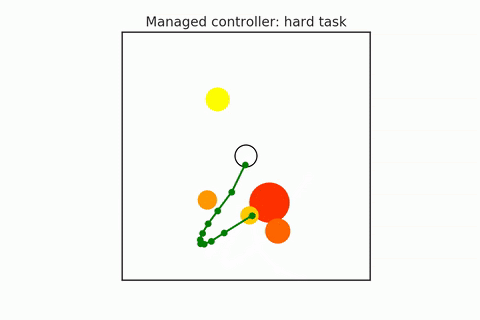
The figure below shows the idea. If you start from state $s_0$ and you want to go to $s_{\infty}$, you can break up this long plan of length one into a plan of length two by inserting a subgoal. You can do this recursively multiple times to end up with a plan of length $k$ or, in this case, a plan of length three.
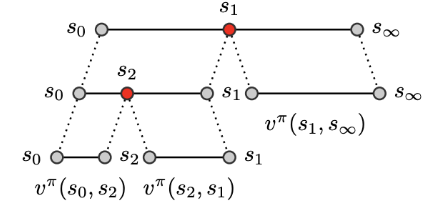
When we use a planner to identify which of these subgoals we should choose in order to maximize the above equation, in the figure below, you see which white subgoal it is considering as a subgoal in order to find a path between the green and the blue points.

- Nasiriany et al. (2019). Planning with Goal-Conditioned Policies. NeurIPS.
- Jurgenson et al. (2019). Sub-Goal Trees — A Framework for Goal-Directed Trajectory Prediction and Optimization. arXiv.
- Parascandolo, Buesing, et al. (2020). Divide-and-Conquer Monte Carlo Tree Search For Goal-Directed Planning. arXiv.
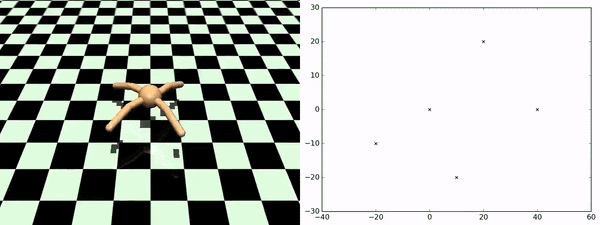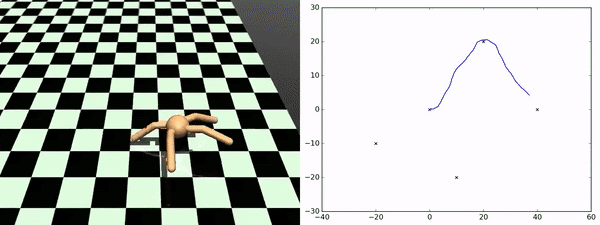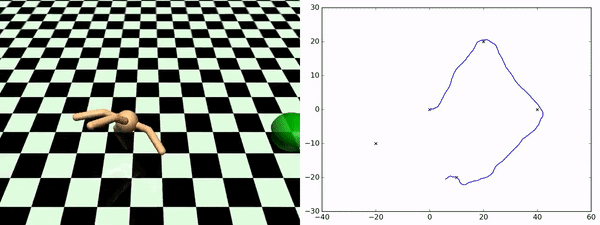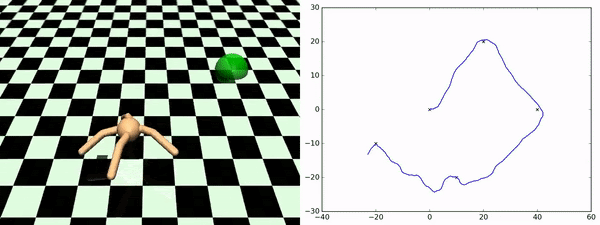
Here, rather than identifying discrete states as subgoals that we want to try to achieve, what we want to do is to learn a set of skills that sort of fully parametrize the space of possible trajectories that we might want to execute. So, for example, in the Ant environment, a nice parametrization of skills would be to say a particular direction that you want to get to move in. So the approach taken by this paper is to learn a set of skills whose outcomes are both (1) easy to predict, so if you train a dynamics model to predict the outcome of executing the skill, and (2) the skills are diverse from one another. That’s why you get this nice diversity of the ant moving in different directions. This works very well for zero-shot adaptation to new sequences of goals. As you can see at the bottom, this is an ant going to a few different locations in space, and it is doing this by just pure planning using this set of skills that it is learned during the unsupervised training phase.
Beyond just using models for prediction, they can be used as regularizers for training other types of representations that then you can train a policy on.
One way is to learn a model as an auxiliary loss. For example, if you have an A2C algorithm and add an auxiliary loss to predict the reward it’s gonna achieve, in some cases, you can get a large improvement in performance by just adding this auxiliary loss. By considering this loss during training, we are actually forcing it to learn the future and capture the structure of the world, which is useful. We also don’t use this learned model in planning and just for representation learning.
The other same idea is to use a contrastive loss, like the CPC paper (below), that tries to predict what observations it might encounter in the future, and by adding this additional loss during training, we see improvement in performance.
Another idea is plannable representations that make it much easier to plan. For example, if we are in a continuous space, we can discretize it in an intelligent way that might make it easy to use some of these discrete search methods, like MCTS, to rapidly come up with a good plan of action. Or maybe we can come up with a representation for our state space such that moving along a direction in the latent state space corresponds to planning. So you can basically just interpolate between states in order to come up with a plan.
- Learn an embedding of states that is easier to plan in, e.g.
- Discretized
- States that can be transitioned between should be near to each other in latent space!
- Related to notions in hierarchical RL (state abstraction)
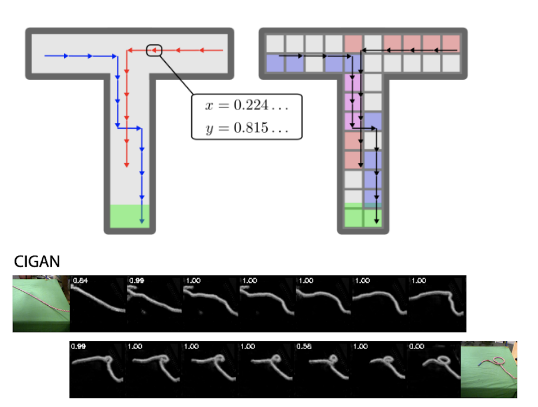
- Corneil et al. (2018). Efficient Model-Based Deep Reinforcement Learning with Variational State Tabulation. ICML.
- Kurutach et al. (2018). Learning Plannable Representations with Causal InfoGAN. NeurIPS.
Models of the world can also be used for fast adaptation and generalization.
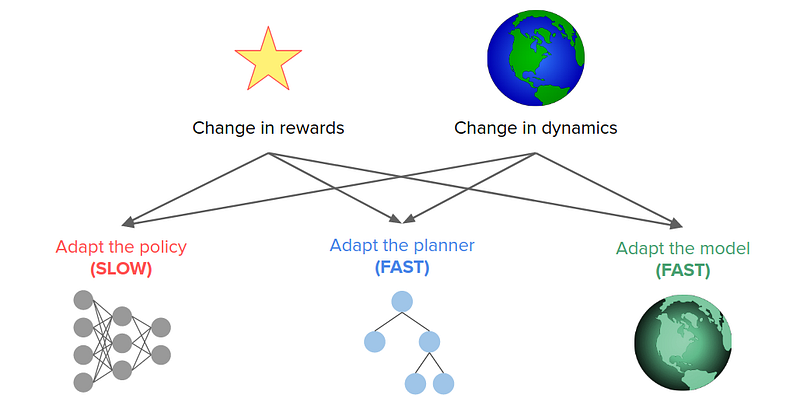
The world can be changed in two different ways:
- Change in rewards. So we’re being asked to do a new task, but the dynamics are the same.
- Change in dynamics.
Based on the above changes, we can do different things in response to them.
In a model-free approach, we must adapt to the policy. But this tends to be relatively slow because it’s hard to quickly adapt changes in rewards to the same dynamics and vice versa because they are sort of entangled with each other.
If we have an explicit model of the world, we can update our behavior differently. One option would be that we can adapt the planner, but we can also adapt the model itself, or we can do both.
A pre-trained policy may not generalize to all states (especially in combinatorial spaces). So some states that we might find ourselves in might be required harder or more reasoning, and others may require less. We have to try to detect when planning is required, and they adapt the amount of planning depending on the difficulty of the task. For example, in the following gifs, in the upper case, the n-body agent can easily solve the task and reach the center’s goal using just a couple of simulations. But in the bottom case, it is much harder to reason about because it starts on one of the planets, which requires many more simulations. We can adaptively change this amount of computation as needed. Save the computation on easy scenes and then spend it more on the hard ones.
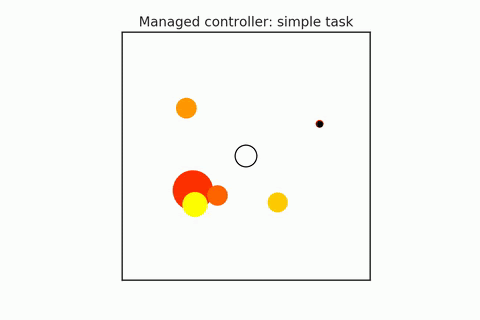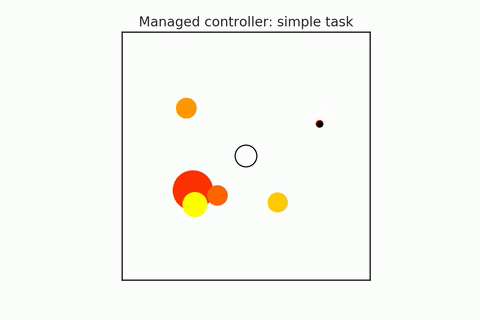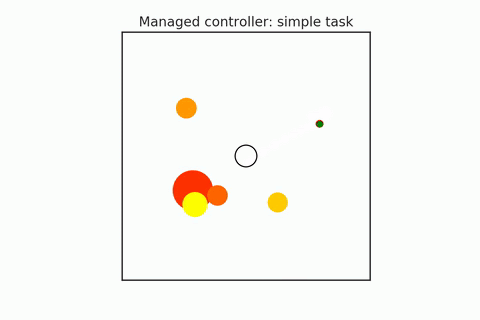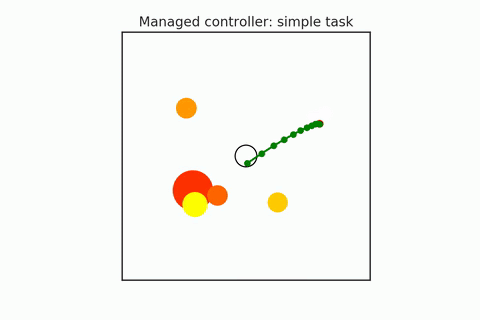
- Hamrick et al. (2017). Meta control for adaptive imagination-based optimization. ICLR 2017.
- Pascanu, Li, et al. (2017). Learning model-based planning from scratch. arXiv.
Here is another same idea in a life-long learning setup where the reward can suddenly change, and either the agents can observe the change in the reward, or they just have to infer the reward has changed. Because of changes in reward, it needs more planning because the prior policy is less reliable, and more planning allows you to better explore these different options for the reward function. In the video below, as you can see in the bottom agent after the reward is changed, the agent needs to do more planning to have a nice movement compared to the other two agents.
For the times that the dynamics change, it could be very useful to adapt the model. One way to approach this is to train the model using the meta-learning objective so that during training, you’re always training it to adapt to a slightly different environment around you, and at the test time, you actually see a new unobserved environment that you never saw before, you can take a few gradient steps to adapt the model to deal with these new situations. Here is an example where the agent, half cheetah, has been trained to walk along some terrain, but it’s never seen as a little hill before. Therefore, the baseline methods that cannot adapt their model cannot get the agent to go up the hill, whereas this meta-learning version can get the cheetah to go up the hill.
Humans are ultimate model-based reasoners and we can learn a lot from how we build and deploy models of the world. — Motor control: forward kinematics models in the cerebellum. We have a lot of motor systems that are making predictions about how our muscles are going to affect the kinematics of our bodies.
- Language comprehension: we build models of what is being communicated in order to understand.
- Pragmatics: we construct models of listener & speaker beliefs in order to try to understand what is trying to be communicated.
- Theory of mind: we construct models of other agents’ beliefs and behavior in order to predict what they are going to do.
- Decision making: model-based reinforcement learning
- Intuitive physics: forward models of physical dynamics
- Scientific reasoning: mental models of scientific phenomena
- Creativity: being able to imagine novel combinations of things
- … and much more!
For more you can see the following reference:
- Markman, Klein, & Suhr (2008). Handbook of Imagination and Mental Simulation.
- Abraham (2020). The Cambridge Handbook of the Imagination.
If you look at the mentioned different domains, where people are engaging in model-based reasoning, a few themes emerge that could be really useful in thinking about how to continue to develop our models in MBRL.
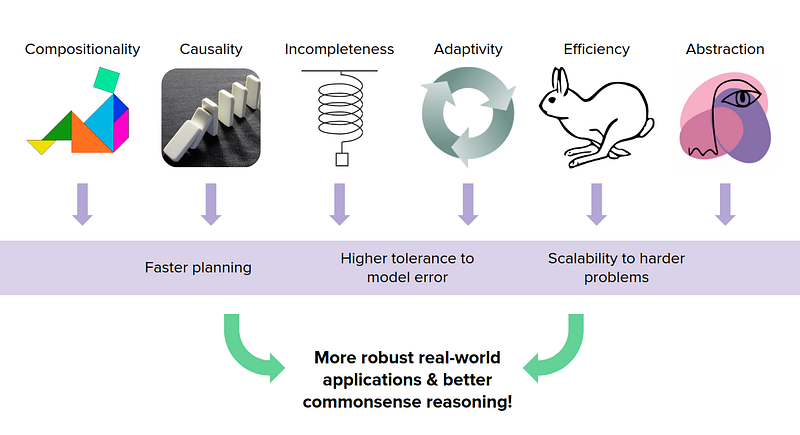
Humans use their models of the world in ways that are compositional, causal, incomplete, adaptive, efficient, and abstract. Taking these ideas and trying to distill them into MBRL enables us to do
This will lead us to more robust real-world applications and better common-sense reasoning.
Humans are much stronger than MBRL algorithms that we have in compositionality.


Another facet of human model-based reasoning is the fact that we can reason about incomplete models, but reason about them in very rich ways. This is in contrast to model-based RL which if we have a model error, would be a huge deal and are very far from human capabilities.

The way that we (humans) use our models is also incredibly adaptive. We can rapidly assemble our compositional knowledge into on-the-fly models that are adapted to the current task. Then we quickly solve these models, leveraging both mental simulation & (carefully chosen) real experience
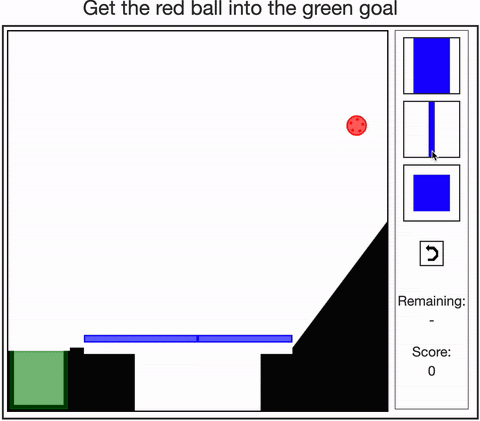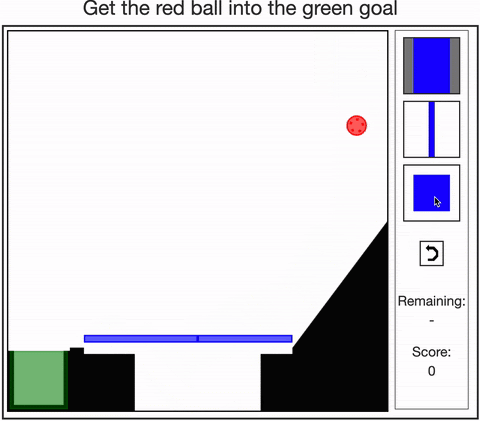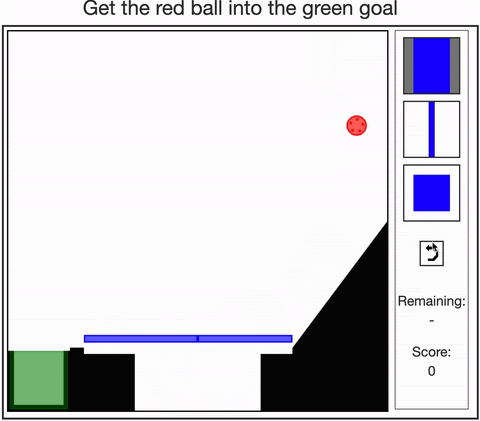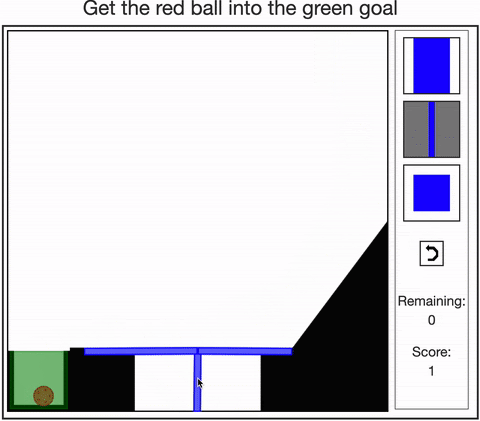
- Allen, Smith, & Tenenbaum (2019). The tools challenge: Rapid trial-and-error learning in physical problem-solving. CogSci 2019.
- Dasgupta, Smith, Schulz, Tenenbaum, & Gershman (2018). Learning to act by integrating mental simulations and physical experiments. CogSci 2018.
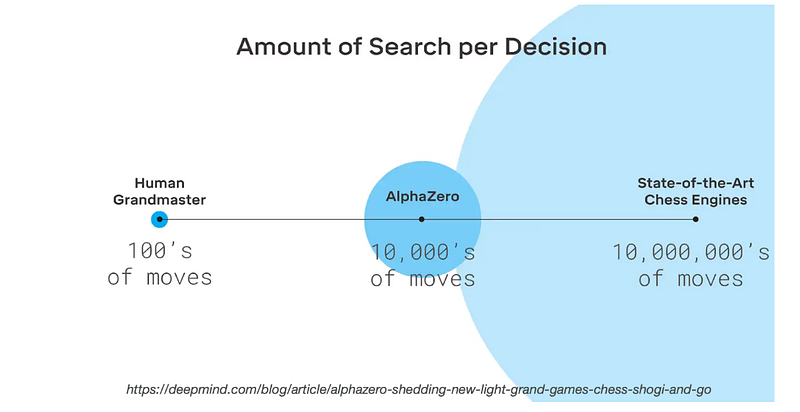
Humans’ model-based reasoning is also very efficient. The figure below illustrates how much of an improvement Alpha-zero was over the former state-of-the-art chess engine which requires tens of millions of moves during a simulation. Whereas Alpha-zero only needs tens of thousands. But again it is not comparable to a human grandmaster, which only requires hundreds of moves. So we need to continue to develop planners that are able to sort of leverage our models as quickly and as efficiently as possible towards this type of efficiency.
The final feature of humans’ ability to use models of the world is an abstraction. We go through all of the different levels of abstraction as we’re planning over multiple timescales, over multiple forms of state abstraction, and we move up and down different forms of abstraction as needed and so we ideally want integrated agents that could do the same.

In this tutorial, we discussed what it means to have a model of the world and different types of models that you can learn. We also talked about where the model fits into the RL loop. We talked about the landscape of model-based methods and some practical considerations that we care about when integrating models into the loop. We also saw how we can try to improve models by looking toward human cognition.
Because MBRL inherits methods both from model-free RL and model learning in general, it inherits the problems from both of them too.
Thank you for taking the time to read my post. If you found it helpful or enjoyable, please consider giving it a like and sharing it with your friends. Your support means the world to me and helps me to continue creating valuable content for you.


