
MNIST — Dataset of Handwritten Digits
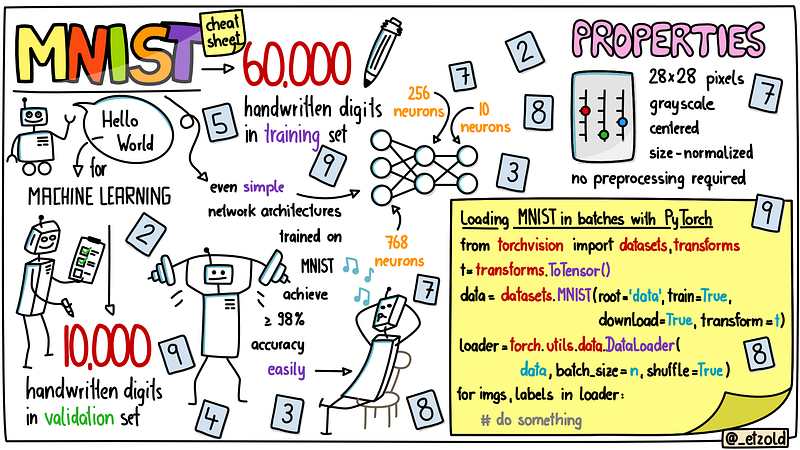
MNIST is a widely used dataset of handwritten digits that contains 60,000 handwritten digits for training a machine learning model and 10,000 handwritten digits for testing the model. It was introduced in 1998 and has become a standard benchmark for classification tasks. It is also called the “Hello, World” dataset as it’s very easy to use. MNIST was derived from an even larger dataset, the NIST Special Database 19 which not only contains digits but also uppercase and lowercase handwritten letters.
In the MNIST dataset each digit is stored in a grayscale image with a size of 28x28 pixels. In the following you can see the first 10 digits from the training set:

Today, the dataset is considered as too simple (e.g. see tweet of Ian Goodfellow) for testing the modern, very complex deep learning models with up to billions of parameters. However, the dataset is still useful. For instance it is useful for quickly testing new implementation of algorithms. If the tested model achieves a high accuracy on MNIST chances are that the implementation is correct. If the algorithm doesn’t work on MNIST, it won’t work at all. Second, MNIST is well suited for machine learning beginners who, for instance, do their first steps in applying machine learning to image recognition.
The dataset was extensively studied by the machine learning community for more than two decades now and a lot of resources can be found in the Internet, books and research papers. Even a simple three layer neural network can achieve accuracies of more than 98% (i.e. an error less than 2%) easily. No preprocessing is required to play with that dataset as all digits are size-normalized and centered in the image. The data can directly be used as input to a machine learning model. The images are grayscale images so that beginners don’t have to deal with multiple color dimensions.
Loading MNIST with PyTorch
With today’s popular machine learning frameworks it’s very easy to load the MNIST dataset. The following code shows the basic steps you have to do with PyTorch.
The basic steps are:
- Specify the transformation that should be applied to the data when it is loaded. In the example we use the ToTensor() transformation which converts PIL images into tensors.
- We load the data with MNIST from datasets. We specify a directory in which the data is stored and we say that we want to load the training dataset. The data should be downloaded and we specify the transformation that should be applied.
- We create a data loader which shuffles the data and returns it from the dataset in batches of size n.
- Finally, we can iterate over the data. In each iteration we get the images and the labels of the images.
Complete Example: Building a Classifier for MNIST
In the following you can see a complete example. It shows how to load the MNIST dataset and train a simple three layer neural network with PyTorch.
This simple example already achieves an accuracy of 97.42% which is quite good for code that can easily be written down in less than 30 minutes. However, a lot of research papers show that this result can be further improved. As one can see here the best result that was achieved so far (as of this writing in January 2022) was published in 2020 in the paper “An Ensemble of Simple Convolutional Neural Network Models for MNIST Digit Recognition”. The proposed method achieved an accuracy of even 99.91% which is an error of just 0.09%. This is quite impressive as this method clearly outperforms human which achieve error rates at 0.2% (see here).
Can we achieve 100% accuracy?
If we can achieve 99.91% accuracy you might wonder whether or not we can achieve even 100%. Well, we might get closer to 100% but it seems that you also have to be lucky to achieve 100% as there might be some incorrectly labeled digits in the test set. As shown here, the training set already contains incorrectly labeled digits (see the first three images below) and some ambiguous images (the two images at the right). Therefore, a perfect classifier (a classifier which always predicts the correct category) will never be able to achieve 100% as it would need to predict an incorrect label which obviously contradicts with the definition of a perfect classifier.

Visualize MNIST
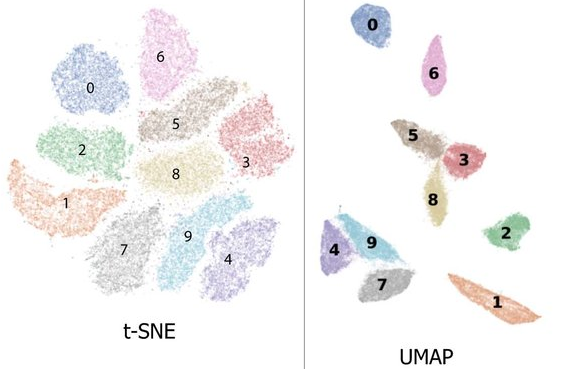
If we visualize the dataset we can clearly see that that digits form compact and well separated clusters when plotted on a two-dimensional plane with t-SNE and UMAP. These well separated clusters are one reason why machine learning models are very successful in correctly classifying the data.
Similar Datasets
Fashion-MNIST
Fashion-MNIST is a dataset which was created by Zalando and which shares the same characteristics with MNIST. Therefore, it can be used as a direct drop-in replacement for the MNIST dataset. As for MNIST, each example in Fashion-MNIST is a 28x28 grayscale image and the examples are size-normalized and centered. It also contains 60,000 training examples and 10,000 examples in the test set. The examples are also drawn from 10 categories which are trouser, pullover, dress, coat, sneaker and so on.
It can also by used very easily with PyTorch. Instead of using “MNIST” from the torchvision.datasets package just use “FashionMNIST”.
In the following you can see some examples of the dataset:

CIFAR-10
Another widely used dataset with similar characteristics as MNIST is CIFAR-10. It consists of 50,000 training examples and 10,000 test examples from 10 classes (e.g. airplane, automobile, bird, cat and so on). The size of the images for CIFAR-10 have been increased slightly to 32x32 pixels and dataset contains only color images.
Again the dataset can be used very easily with PyTorch. You just have to use the class “CIFAR10” of the torchvision.datasets package.
Here you can see some examples of the dataset:

Summary
Today, MNIST is typically not used anymore for benchmarking new algorithms as it’s too simple for today’s complex models. However, it is a great dataset for starting with machine learning and for quickly testing the implementation of machine learning algorithms. No preprocessing is required to use the data and less than five lines of Python code are needed when it’s used with PyTorch.
The article’s full resolution image is available at: https://etzold.io/mnist.png






{kind=link}