
MLOps 4: Continuous Training, Model Management, & Continuous Integration
Click to go to Entire Series
Having discussed the data engineering side of MLOps, in the previous chapter, let’s get into model training in this chapter and how MLOps helps in making it efficient.
Managed training pipelines
We’ll start off with managed training pipelines. Similar to managed data pipelines, training pipelines play a vital role in the ML workflow.
A robust managed training pipeline helps create repeatable ML training and testing workflows while reducing human costs.
Being the core activity, as well as the most unpredictable activity in building an ML application, ML training can benefit a lot from an organized MLOps setup for the project.
What are the key training pipeline functions?
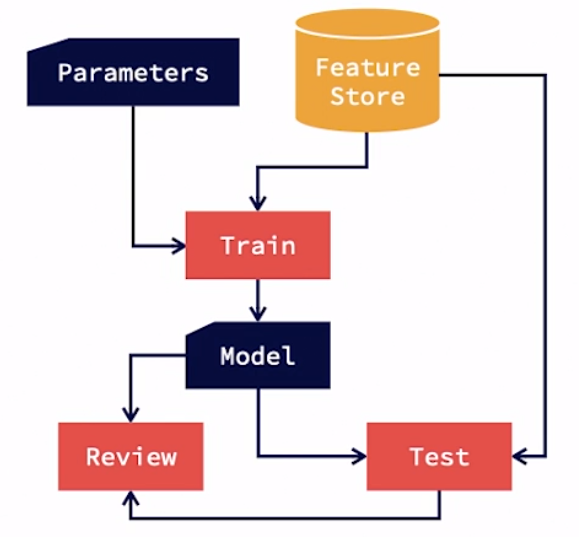
It starts with the feature store. Training inputs are fetched from the feature store for model training. The hyper parameters are also set up for training. An experiment is then planned and executed. Executing the experiment results in the ML model. The model is then validated during training to ensure that desire levels of performance are achieved. Then an independent test data set is used from the feature store and the model is tested with this data set to analyze out-of-sample errors. The results of this testing are reviewed to see if desired performance goals are met. And if there are more opportunities for improvement, new experiments are planned. This results in updating the model parameters and retraining the model with possibly an updated training data set.
This process keeps repeating until a model with the desired performance is achieved.
What are the best practices of managing a training data pipeline?
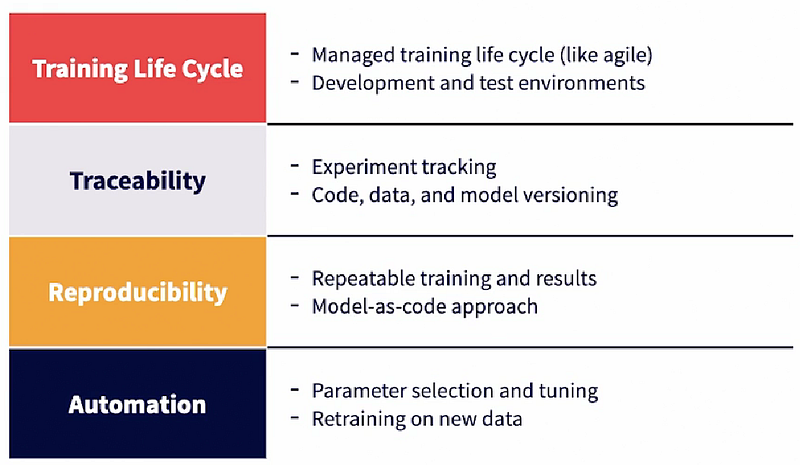
1) TRAINING LIFE CYCLE: To begin with, there has to be a life cycle like agile that needs to be followed by the data science team. There has been some progress in customized processes for machine learning that are optimized for continuous experiments. Also, modeling involves writing code mostly in notebook. There should be separate development and test environments for training the models. It’s recommended that the final run of the model takes place in a controlled environment.
2) TRACEABILITY: Next comes traceability of the experiments. Experiment tracking is a key MLOps activity that we will cover later in this chapter. Also, version control should be used for code, data, and models, and the corresponding versions need to be tied together for experiment tracking.
3) REPRODUCIBILITY: Reproducibility of training is a key MLOps goal. It should be able to reproduce the building of the model from scratch from its training data and input parameters. Model as code approach is recommended where all the notebooks themselves are baseline and versioned. Version data should be used. Rerunning the code should result in the same model being produced again.
4) AUTOMATION: Finally, automation plays a key role in scaling the training process efficiently. Automation can be used for parameter selection and tuning of models. Techniques like grid search can be executed with automation each time a new experiment is done. Similarly, when new training data is available, the data engineering and model training pipelines should be automatically executed to build a new model and compare it to the baseline.
Experiment tracking
One of the critical areas for MLOps is the tracking of ML experiments. In ML training, multiple runs of building and validating the model happens as the data scientists work towards their expected performance goals.
Each ML training run is considered an experiment.
Experiment tracking helps manage the evolution of an ML model towards stated performance goals. Experiments should be tracked continuously to analyze if improvements are made and decide on the next set of experiments to run.
What should be tracked for an experiment?

1) MODEL: We begin with the model itself. All the model set up including the ML algorithm being used and the architecture of the model for deep learning models need to be tracked. Also the hyper parameters set up for the specific experiment should be tracked.
2) INPUT: Next comes the input to modeling. The specific data set and its version should be linked to the model. The training validation and test splits should also be tracked. With the model configuration and inputs, it should be possible to recreate the specific experiment and reproduce the results.
3) OUTPUT: Then comes the output produced. This includes the model itself in some serialized form like a pickle file. There are also performance measures like accuracy, errors and F1 scores that need to be tracked.
4) ANALYSIS & DECISIONS: Once the results are obtained, the data scientist would analyze the results and compare them against earlier experiments. This comparison should also be documented and tracked. All discussions, findings and next steps should be tracked as documentation and associated with the experiment.
What are the benefits of experiment tracking?
- Experiment tracking helps measure the impact of changing model parameters.
- It also helps identify model behavior due to changes in training data.
- Data scientists can verify if the project is moving towards the stated requirements and goals and take corrective action with experiment tracking.
- The results of experiments can help decide if the model needs to be promoted to production.
- This analysis can be automated along with decision criteria for promotions, thus leading to an automated experiment analysis and promotion pipeline.
One key aspect to remember is the amount of activity needed for experiment tracking. Doing this tracking manually is time consuming and prone to errors. It’s recommended to use the right tools built for this purpose and integrate them into the ML training pipelines. This way data is automatically added to the tool during experiments and tracked over time.
Model versioning
ML models evolve over time, as new training data is used and hyper parameters tuned. Tracking models with versions help establish lineage and manage its life cycle.
Version control schemes should be similar to what is followed for software code. The specifics of the number of sub-versions and how version numbers change can be specific to our organization.
- Having version models along with data versions and code versions helps the team to establish baselines that link all the three versions. Given a model version, it’s easy to see the input data that was used to build the model and the hyperparameters used. This helps in tracking and analyzing improvements in model performance.
- Version models can be easily referenced for integration and testing, and a given test cycle can stay with the same version until completed.
- Versioning also helps in model life cycle management, which we will discuss later.
Model registry
Similar to how data is cataloged in feature stores and code is stored in code repositories, models do need their own registry to manage their life cycle.
A model registry is a repository for storing and tracking machine learning models. It is a database that contains the model and metadata about the model.
The database can be queried at any time to access the model and information about it. It is constantly updated with all status changes and associated audit trails.
What information is captured in the model registry about the model?
- First, a serialized version of the model, like a pickle file is stored in the registry.
- Metadata about the model, including a unique model ID, version, and description of the model is stored.
- Hyper parameters used for the model is a key metadata to capture.
- Then there is model status based on which stage of the life cycle the model is currently in.
- There is also an audit trail of the model’s history, including timestamp of state changes, test passes, test failures and deployment.
- There are also links to the input data version, the code or the notebook version that is used to build the model, and performance results from experiment tracking.
Typically, an organization has a single central store for all the models that is shared by its ML teams.
- The registry provides traceability of the model, including its data and code lineage. This then helps in recreating the model if needed.
- The registry provides tracking of life cycle events for the model, thus helping in life cycle management.
- A central model registry serves as a communication and collaboration medium across multiple teams, and within the same team across different time intervals.
- The registry helps in automating the model creation and consumption activities. It also helps govern the data around the model, including access control and auditing.
Benchmarking models
A key activity in the machine learning life cycle is benchmarking of models. It is the activity of comparing models and their versions against baselines and other competing models to understand how they perform against each other with respect to the stated project requirements and environments. It happens after a model is found to pass its fitness test and is ready for integration.
Benchmarking tests the model in environments that are closer to production, and test for both performance and operational metrics.
What setup is required for a benchmarking environment?
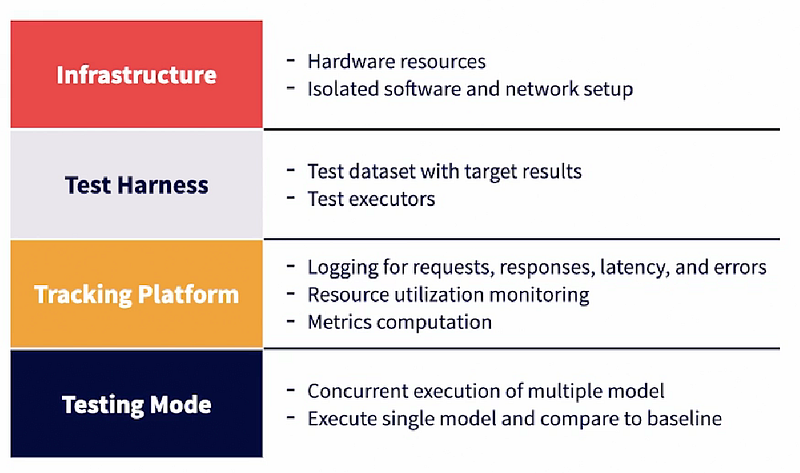
INFRASTRUCTURE: First, it needs hardware compute power, like CPU, memory and discs. It also needs an isolated software and network setup where the benchmarking process won’t be impacted by other activities.
TEST HARDNESS: Next, it needs a test hardness. Both the baseline and the new model need to be subjected to the same test hardness. The test hardness contains a test data set that will be fed to the model and the expected results from the model. There will also be test executors that can execute the test cases with required pacing and capacity.
TRACKING PLATFORM: Then comes the benchmarking tracking platform. The platform should provide for logging of prediction requests, the actual predictions, observed latency, and errors. Resource utilization during execution should also be monitored. Then various performance and operational metrics need to be computed. The tracking platform can use a combination of standard DevOps observability platforms and ML experiment tracking platforms.
TESTING MODE: Finally, the mode of testing also needs to be determined. It could be that both models run simultaneously at the same time, or it’s a single model that is executed and then compared against the baseline. This is use case specific.
Benchmarking activities should result in collection of various metrics for analytics.
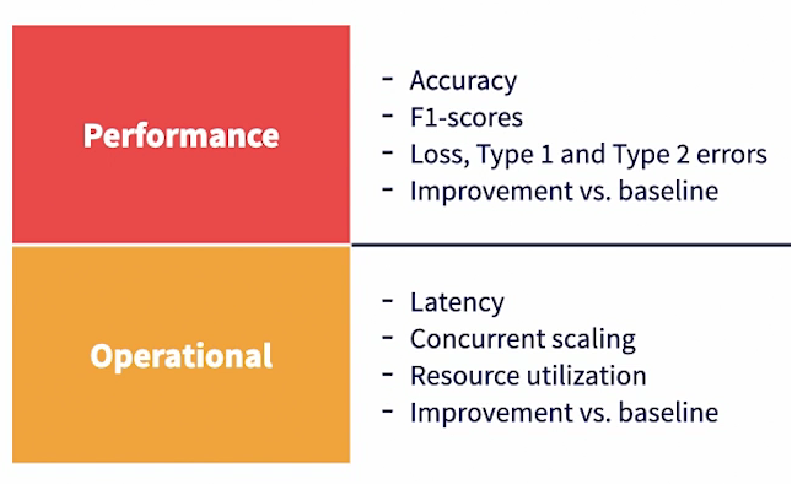
- First, there are the model performance or effectiveness metrics that need to be computed, including accuracy, F1-scores, et cetera.
- Then operational metrics also need to be computed, like latency, scaling and resource utilization. A given model may perform better than its baseline when executed from a notebook. But when executed in a benchmarking setup, it may require more resources and may create additional latency.
The benchmarking process provides validation that the model is fit for production for both performance and operational requirements.
Let’s review some of the best practices for benchmarking.
- Benchmarking should enable apples-to-apples comparison and care should be taken to make sure that it is indeed so.
- It’s recommended to log all actions, results and resource utilization at the most granular level as possible. This is required for troubleshooting, if needed.
- The benchmarking task should be automated and integrated into the training and deployment pipelines.
- As the model gets promoted, benchmarking should run automatically and compared to its baselines.
- Experiment tracking tools can be used to track benchmarking results for long-term performance analytics.
Model life cycle management
The machine learning process can be considered as the journey of a model. A model goes through a life cycle and managing its life cycle is central to MLOps. A well defined model life cycle with associated policies and processes helps in organizing, managing and scaling machine learning in an organization.
When we talk about life cycle, we are talking about multiple model states and the state transitions that happen during the life of a model.
Let’s discuss a sample life cycle of a machine learning model or more specifically, a version of a model.
This is a sample set of state and state transitions and you should build your own state transition scheme for your organization.
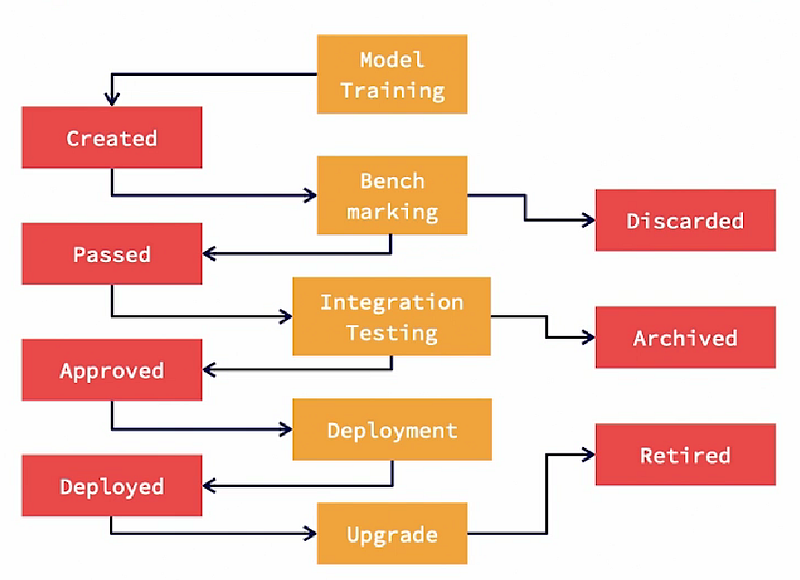
- First, we start with the model training activity, which produces a model. The model moves into the created state. Then, we perform model benchmarking. If the model passes benchmarking, it transitions to the passed state. If it fails benchmarking, it moves to the discarded state.
- Next, the model is integrated with non ML code and goes through integration testing. If it passes integration testing, it moves to the APPROVED state. Else, it moves to the archived state. We could have also discarded it.
- An approved model is then deployed in production and moved to the deployed state.
- When a new version of the model is ready, it’s upgraded in production. Then, the current model is moved to the retired state.
As the model goes through this life cycle, it is considered being promoted to newer states.
How do we promote models?
It’s recommended to define the model life cycle and the promotion criteria during the requirement stage.
- Promotions should be based on metrics. This includes performance and operational metrics based on which model requirements are stated.
- For integration testing, it should have a past criteria that is around these metrics again and also other non ML criteria like the total number of issues found.
Automate the promotion process in the pipeline based on thresholds on these metrics. It improves efficiency with less human intervention.
Add human oversight as needed. During the initial stages, more oversight as needed to make sure that the pipeline and promotions are working as desired but as the pipeline matures, oversight can be reduced.
Capture the decision and promotion history as part of the model registry for future reference.
Solution Integration pipelines
Once the model is ready and benchmarked, it needs to be integrated with the non ML part of the solution.
ML models do not work standalone. They need to be embedded into other code to deliver end-to-end solutions. This requires integration with other code like APIs, UIs, databases, and microservices. How do we go about doing this integration?
Let’s look at the solution integration pipeline now.
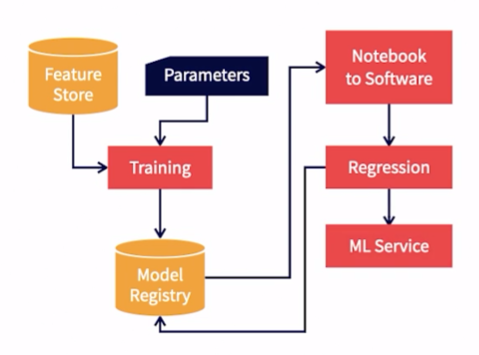
As seen before, we trained the model using input data from the feature store and hyper parameters. We then stored the model in the model registry. Now, the model and its pre-processing and post-processing code is in the form of a notebook. It needs to be converted into a software form that is suitable for integration. We call this step, notebook to software.
This method produces the model in an executable form. This is then regression tested to make sure that the model still continues to perform as its baseline notebook form. This produces an ML service that is ready for integration. We call it a service here but it could be a library or a function.
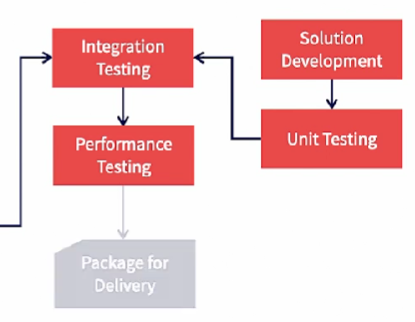
On the other hand, the non ML code evolves independently. The non ML code is tested with other functions and it gets ready for integration. The ML service is then integrated into the non counterpart and integration tested. The entire solution is then performance tested to make sure that the solution as a whole meets the requirements of the project. This is then packaged and is ready for delivery.
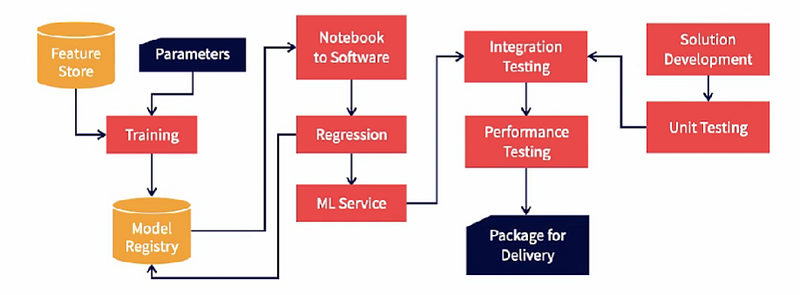
The package contains both the model in its executable form and the non ML code.
Notebook to software
The notebook to software step deals with producing a deployable and executable version of the model.
Code in ML notebooks need to be converted to executable software before it can be integrated and deployed. This conversion should ensure that processing and model aspects from the notebook are faithfully reproduced into the code, and has the same performance as the notebook.
There are multiple ways in which a model can be made into an executable form. This depends upon the type of use case and deployment.
- To begin with, the model can be provided as embedded software, where it gets embedded into non-ML executables.
- Alternatively, it can be its own running service that receives requests from clients and returns responses. The use cases could be batch or historical predictions and streaming or online predictions.
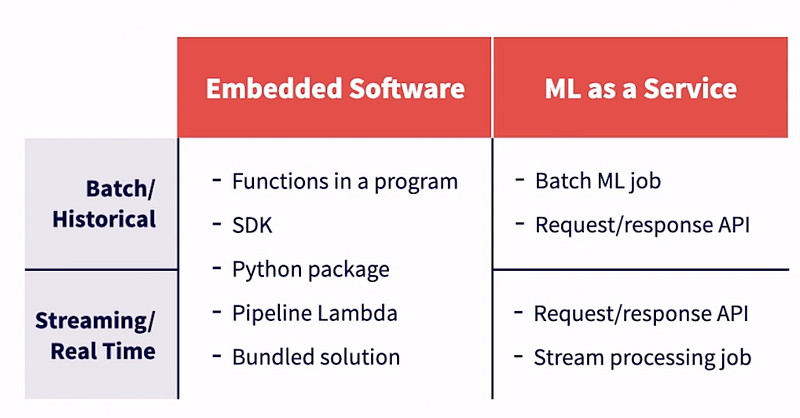
If it’s an embedded software, it does not make a difference between the use cases. The model could be a function in a program. It could be made available as an SDK. It could be a Python package. It can be a pipeline Lambda function. It can be a form of bundled solution that is sold.
If it runs as a service, the deployment forms will vary.
- For batch use cases, the model itself can be a batch ML job that reads data from a database and writes predictions back to the database. It can be an API, like a rest API, that receives requests from clients and returns predictions as responses.
- For streaming, APIs can do the work also. Predictions can be a stream processing job that reads requests from a queue and writes the predictions to another queue.
Whichever deployment form is chosen, the process of conversion is similar.
What needs to be converted and added to the executable?
- First, required steps for pre-processing of input data needs to be added. These may be steps like tokenization, encoding, input scaling, et cetera.
- Next, the model filed from the registry needs to be brought in. The executable can either package the model file as a part of the deployment package or read it in real time from an external repository.
- Next, the inference step needs to be coded in.
- After that, any kind of post-processing, like decoding, reverse scaling, conversion to business outcomes, et cetera, should also be added in.
- The code should provide interfaces to receive inputs and return outputs. These may be function calls, rest APIs or database queries.
- Finally, the build, test and deployment infrastructure for this executable also needs to be built, like any other software module.
Once the notebook is converted to software, it is critical to do regression testing of the model to make sure that it has not lost any of the steps or performance that it had in the notebook. Here, it’s recommended to use the benchmark results for the model as the baseline. Then, use the same input data used for benchmarking as input for testing.
Regression should ensure that the model delivers the same performance as the original notebook. If not, it needs to be fixed and retested. Special attention should be given to the pre-processing and post-processing steps. And their regression should also be tested.
Solution integration patterns
When do we integrate the ML and non-ML parts of the solution? Let’s look at the options available in this video.
The ML and non-ML parts of the solution evolves simultaneously in incremental cycles. Integrating code is always cumbersome, if the process is not well managed. Ensuring integration with stable versions of the software will help avoid sub prices later during deployment.
Let’s look at a sample ML and non-ML pipeline.
On the ML side, we start with the model version 2.0 and the corresponding ML service version 2.0, we then evolve this model with retraining and come up with a model version 3.0. This goes through the notebook to software process to produce ML service 3.0. On the other side, we start with the non-ML version 4.0. It goes through development and testing processes to produce non-ML version 5.0. This process happens simultaneously, where the ML service 3.0 is being developed. When would you integrate the new ML service 3.0 with non-ML version 5.0.
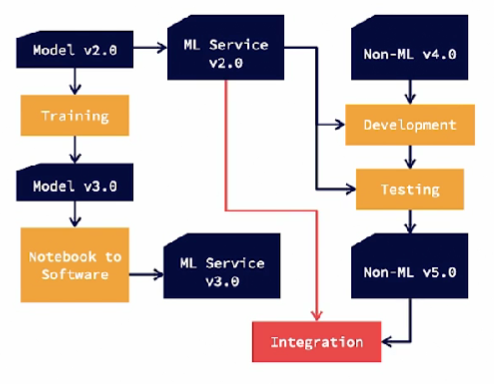
The first option is to hold the ML version constant throughout the non-ML iteration. Do note that during the development of the non-ML model, the ML service should be available in some form for making development progress. This may be a dummy service or an earlier version. So we can use ML service version 2.0 for the development of non-ML version 5.0, all the way to integration and deployment. Keeping the ML service constant, provides stability in the development process of the non-ML service. We can then do the next solution release, where we can hold the non-ML version to 5.0 and use the new ML service 3.0.
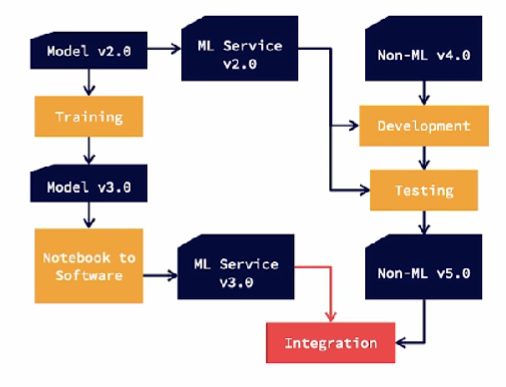
The second option is to adapt a new ML version, as soon as it becomes available during the non-ML cycle. In this case, we will use ML service 2.0 during non-ML 5.0 development, until ML service 3.0 becomes available. The new ML service version is introduced in the middle of the non-ML development or integration cycle.
What are the advantages and disadvantages of adapting the model too soon as it becomes available?
Adapting ASAP provides for a faster overall life cycle and quicker time to market. Any issues with the model or the integration would be found earlier. On the other hand, bringing a new version late in the cycle may result in problems and unplanned delays as we roll back and forward. It also requires complex team collaboration between the ML and non-ML teams to make sure that these pieces would work properly when bought together later in the development cycle. Automation can be challenging also if it automatically pulls in a new version of the model, into the development and test cycle leading to breaking of the pipeline.
Once again, choose a pattern that best fits your requirements and take care of the shortcomings with proper processes.
Best practices for solution integration
Let’s complete the course by discussing some best practices for solution integration for machine learning. We will extend some of the best practices in other pipelines to the integration pipeline also.
- Define code promotion policies for various stages in the integration pipeline. Stated policies help everyone understand the requirements and avoid confusion at a later stage.
- Define acceptance criteria that are measurable either using pass-fail tests or performance and operational metrics.
- Automate solution integration and testing, as this needs to be done frequently, as the ML and non-ML parts evolve simultaneously.
- Focus on both the ML and-non ML test cases during integration.
- And finally, it’s important for the ML and non -ML teams to collaborate consistently to make sure that each knows what the other team is working on and can anticipate changes.





