
ML Paper Challenge Day 34, 35 — SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Day 34–35: 2020.05.15–16 Paper: SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size Category: Model/Optimization
SqueezeNet
Strategy
- Replace 3x3 filters with 1x1 filters
- Decrease the number of input channels to 3x3 filters using squeeze layers
- Downsample late in the network so that convolution layers have large activation maps
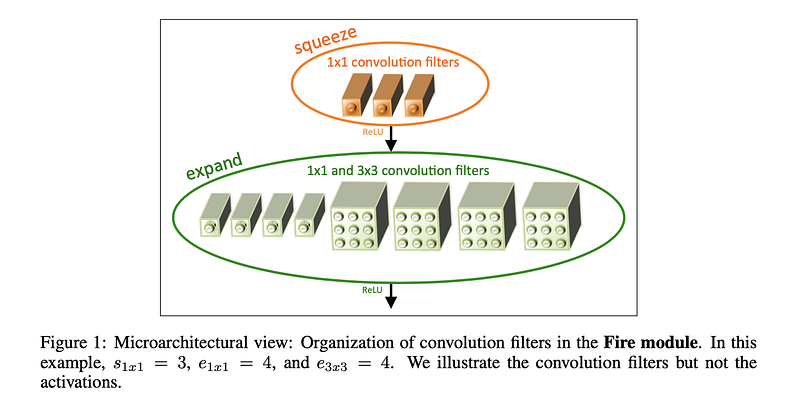
Fire Module, comprised of
- a squeeze convolution layer (which has only 1x1 filters) (as per Strategy 1)
- feeding into an expand layer that has a mix of 1x1 and 3x3 convolution filters
- We expose three tunable dimensions (hyperparameters) in a Fire module: s\_(1x1), e\_(1x1), and e\_(3x3).
- In a Fire module, s\_(1x1) is the number of filters in the squeeze layer (all 1x1), e\_(1x1) is the number of 1x1 filters in the expand layer, and e\_(3x3) is the number of 3x3 filters in the expand layer.
- When we use Fire modules we set s\_(1x1) to be less than [e\_(1x1) + e\_(3x3)], so the squeeze layer helps to limit the number of input channels to the 3x3 filters, as per Strategy 2.
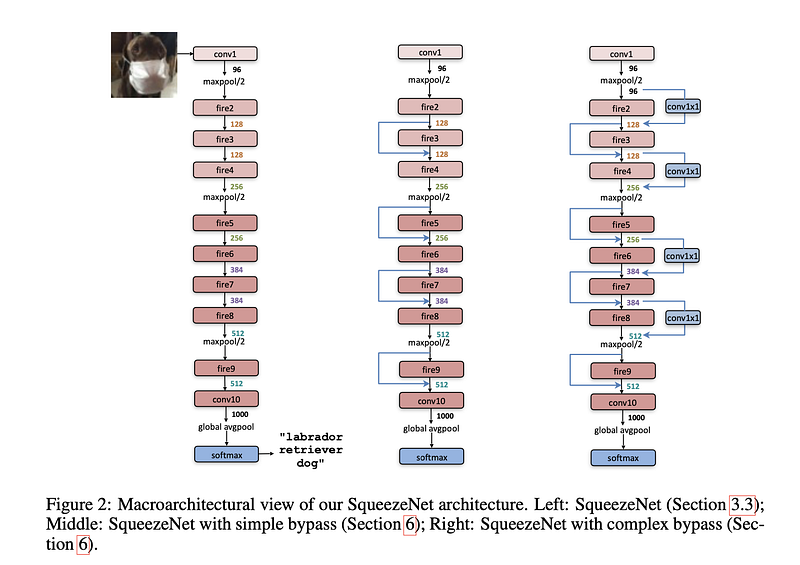
SqueezeNet Architecture
- begins with a standalone convolution layer (conv1)
- followed by 8 Fire modules (fire2–9)
- ending with a final conv layer (conv10)
- gradually increase the number of filters per fire module from the beginning to the end of the network
- performs max-pooling with a stride of 2 after layers conv1, fire4, fire8, and conv10; these relatively late placements of pooling are per Strategy 3
Other details
- To have the same height and width in the output activations from 1x1 and 3x3 filters, add a 1-pixel border of zero-padding in the input data to 3x3 filters of expand modules.
- ReLU is applied to activations from squeeze and expand layers.
- Dropout with a ratio of 50% is applied after the fire9 module.
- Lack of fully-connected layers
- begin with a learning rate of 0.04, and linearly decrease the learning rate throughout training