
ML Paper Challenge Day 18 — Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Day 18: 2020.04.29 Paper: Deep Speech 2: End-to-End Speech Recognition in English and Mandarin Category: Model/Deep Learning/Speech Recognition
Model Architecture
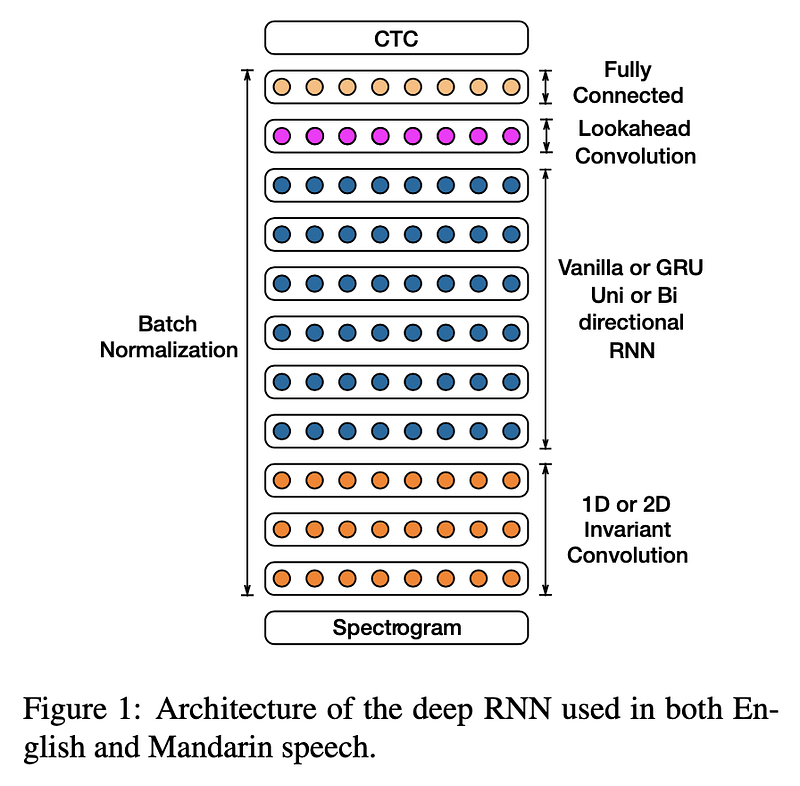
Input: log-spectrograms of power normalised audio clips, calculated on 20ms windows Output: alphabet of each language Inference: CTC models paired a with language model trained on a bigger corpus of text
Batch Normalisation for Deep RNNs
Objective: To train networks using gradient descent when the size and depth increases
2 Ways to apply:
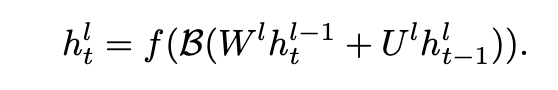
- Insert a BatchNorm transformation, B(·), immediately before every non-linearity -> Not effective
- Batch normalise only the vertical connections For each hidden unit, compute the mean and variance statistics over all items in the mini-batch over the length of the sequence.
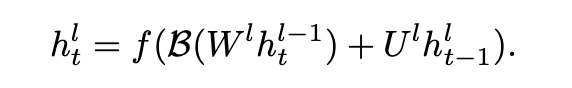
SortaGrad
Objective: Make training more stable. Accelerates training and results in better generalisation
Use the length of the utterance as a heuristic for difficulty and train on the shorter (easier) utterances first.
In the first training epoch, iterate through mini-batches in the training set in increasing order of the length of the longest utterance in the mini-batch.
After the first epoch, training reverts back to a random order over mini-batches
GRU vs LSTM
GRU and LSTM reach similar accuracy for the same number of parameters, but the GRUs are faster to train and less likely to diverge.
Frequency Convolutions
Objective: model spectral variance due to speaker variability more concisely than what is possible with large fully connected networks
Multiple layers of Time-and-frequency domain (2D) convolution do better than one layer.
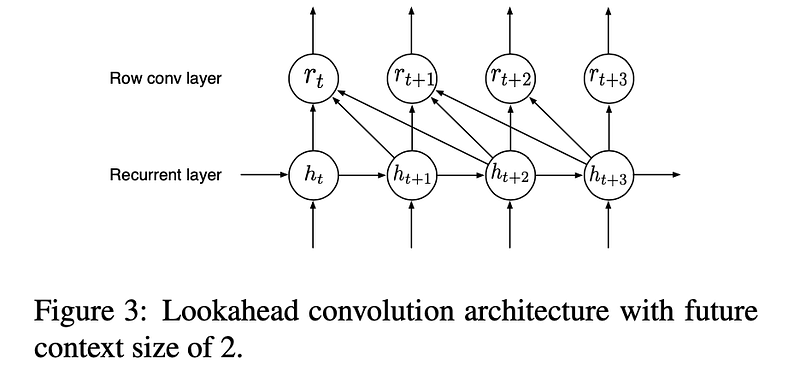
Lookahead Convolution and Unidirectional Models
Objective: Bidirectional RNN models are challenging to deploy in an online, low-latency setting because they cannot stream the transcription process as the utterance arrives from the user. However, models with only forward recurrences routinely perform worse than similar bidirectional models.
The layer learns weights to linearly combine each neuron’s activations τ time-steps into the future, and thus allows us to control the amount of future context needed.
Adaptation to Mandarin
- The only architectural changes we make to our networks are due to the characteristics of the Chinese character set.
- Use a character level language model in Mandarin as words are not usually segmented in text.




