
WEEKLY AI NEWS: RESEARCH, NEWS, RESOURCES, AND PERSPECTIVES
ML news: Week 29 January — 4 February
FTC investigates Microsoft, the leak of a new Mistral model, and much more

The most interesting news, repository, articles, and resources of the week
Check and star this repository where the news will be collected and indexed:
You will find the news first in GitHub. Single posts are also collected here:
Weekly AI and ML news — each week the best of the field
Edit description
salvatore-raieli.medium.com
Research
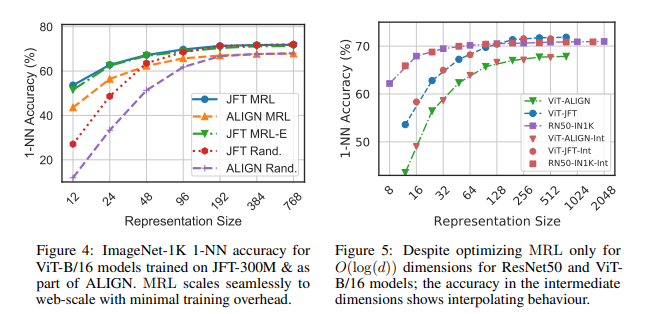
- Matryoshka Representation Learning. The new embeddings from OpenAI are scalable to meet your demands. This is thought to be caused by the learning strategy known as the nesting doll approach, which learns characteristics at different granularities.
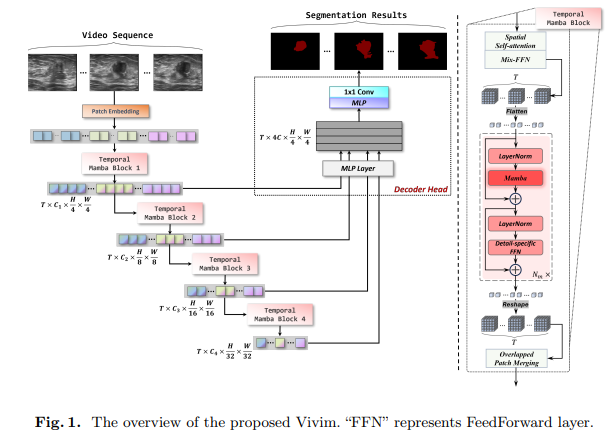
- Vivim: a Video Vision Mamba for Medical Video Object Segmentation. A new framework called Vivim efficiently processes lengthy video sequences for medical video object segmentation. In comparison to conventional techniques, Vivim provides faster and more accurate segmentation results by effectively compressing spatiotemporal data using the state space model methodology.
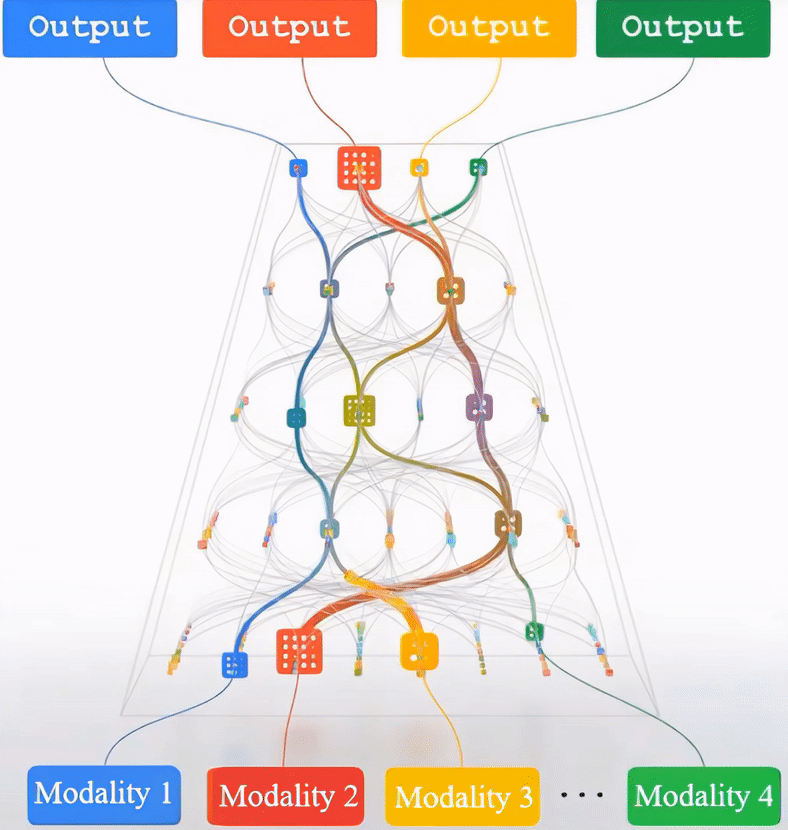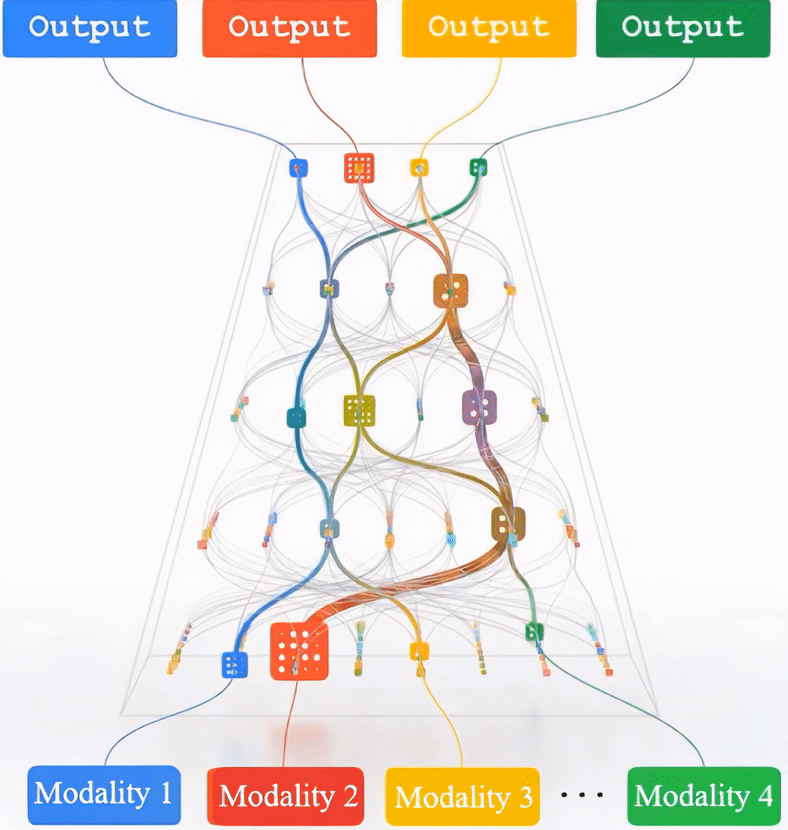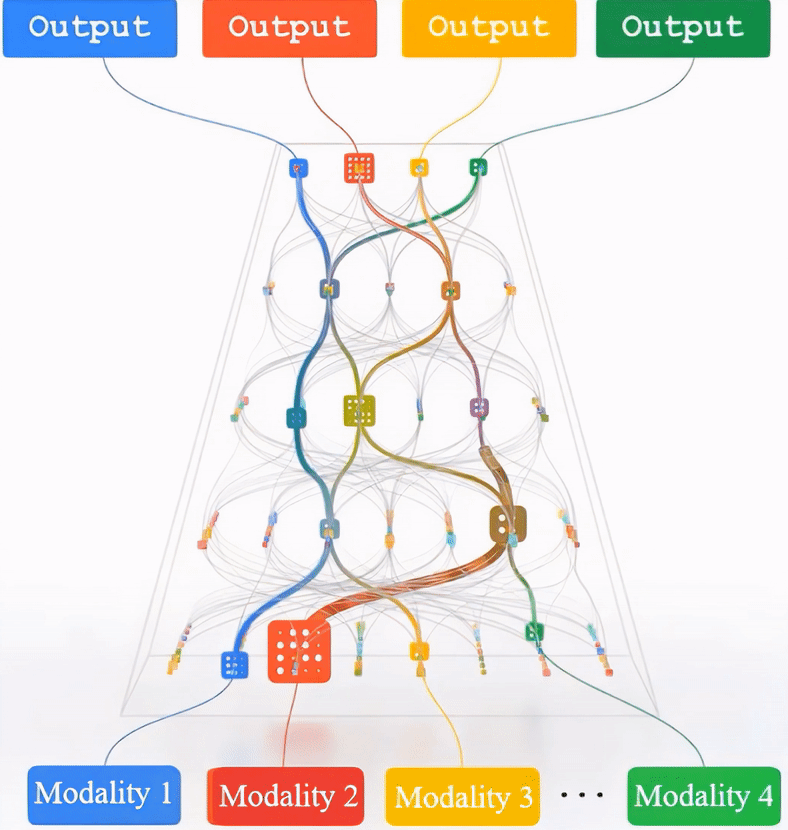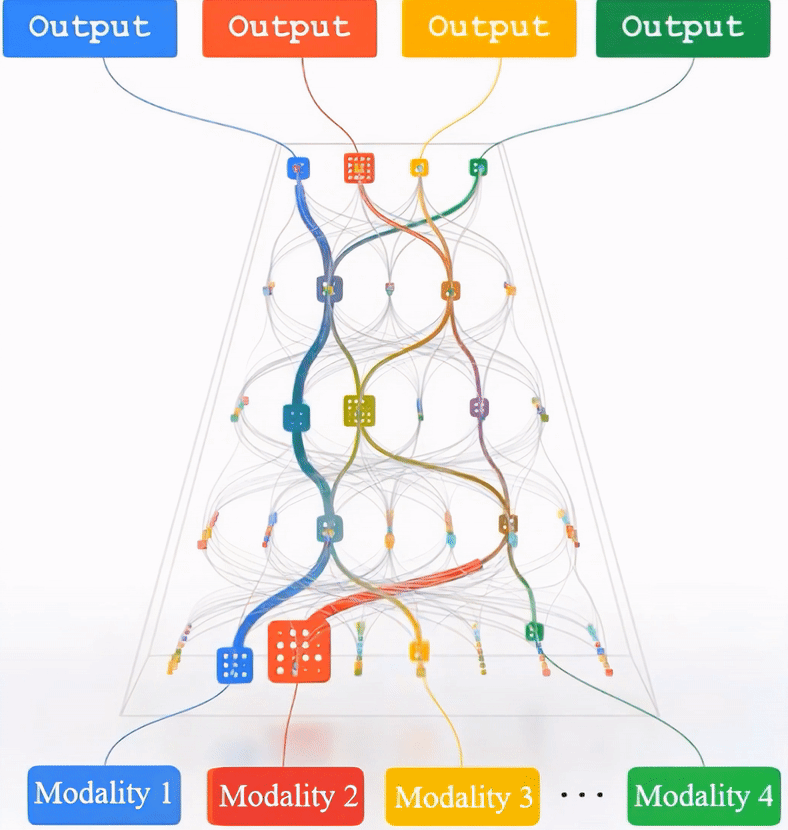
- Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities. This study presents a unique way to improve transformers by utilizing disparate input from many modalities, e.g., audio data to improve an image model. By connecting the transformers of two distinct modalities in a unique way, the Multimodal Pathway enables a target modality to profit from the advantages of another.
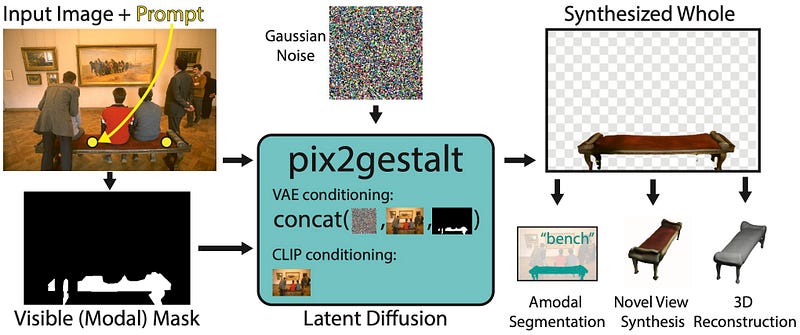
- pix2gestalt: Amodal Segmentation by Synthesizing Wholes. A framework called Pix2Gestalt is intended for zero-shot amodal segmentation. When an item is partially occluded, it can rebuild its entire shape and look with great skill. Pix2Gestalt, which makes use of large-scale diffusion models, performs exceptionally well in difficult situations, such as producing artistic images that break convention.
- Large-Vocabulary 3D Diffusion Model with Transformer. The variety of objects that may be generated in 3D poses a significant difficulty. This study builds up the system to operate with a considerably bigger range of items in each 3D category and employs a changed architecture to enhance sampling efficiency.
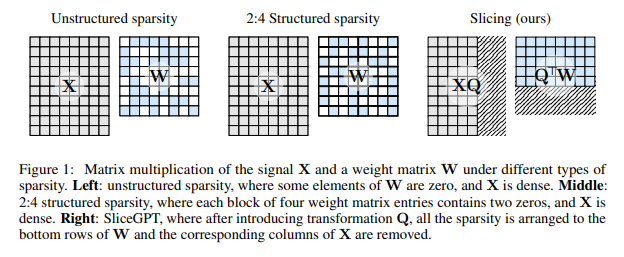
- SliceGPT: Compress Large Language Models by Deleting Rows and Columns. Another potential distillation work. Importantly, this one can work on models as small as Phi-2. This means you can remove 90% of the rows and columns of weight matrices with minimal reduction to quality at almost all scales.
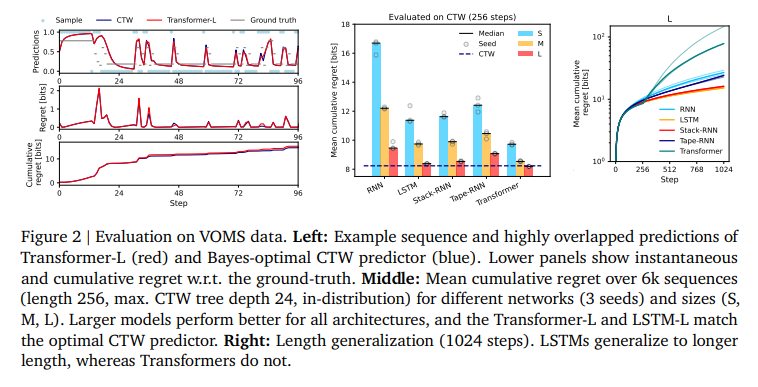
- Learning Universal Predictors. The process of teaching systems to learn from experience and swiftly adjust to new tasks is known as meta-learning. With artificial data produced by a Universal Turing Machine, this Google project enhances Meta-Learning and conducts both theoretical and experimental analysis of the outcomes.
- CreativeSynth: Creative Blending and Synthesis of Visual Arts based on Multimodal Diffusion. CreativeSynth is an artistic picture editing technique that combines text and image inputs in a seamless manner. Its diffusion approach, which has specialized attention processes built in, allows for fine alteration of both style and content while maintaining the essential elements of the original artwork.
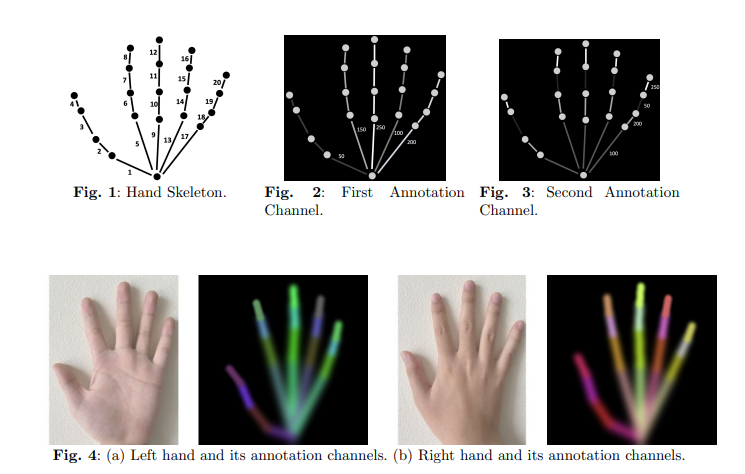
- Annotated Hands for Generative Models. By adding three more channels to training photos for hand annotations, researchers have increased the capacity of generative models, such as GANs and diffusion models, to produce realistic hand images.
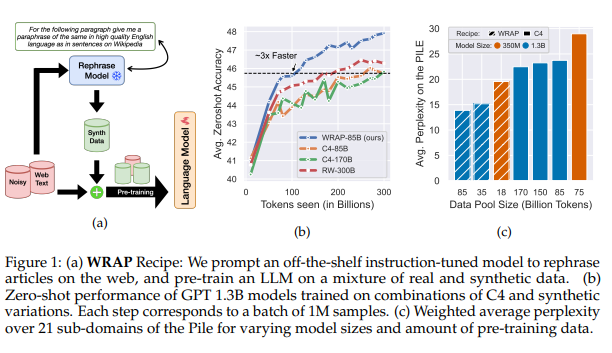
- Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling. Many AI systems employ the concept of “up captioning” to enhance labels during training. This work from Apple rephrases C4 as instructions, Q&A pairs, and more in order to apply it to pre-training. The rephrasing step increased convergence by 10x, according to the study, making the model significantly more sample-efficient, albeit at the expense of the rephrasing step itself.
- Continual Learning with Pre-Trained Models: A Survey. This work provides an extensive overview of the most recent developments in continuous learning, which is centered on continually adjusting to new information while preserving prior understanding.
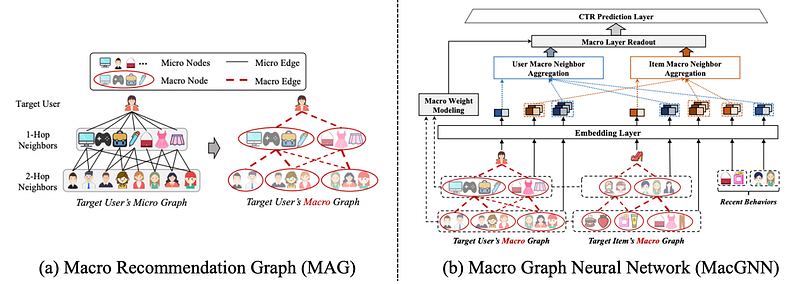
- MacGNN. The MAcro Recommendation Graph (MAG) and Macro Graph Neural Networks (MacGNN) are introduced in this research. These methods greatly reduce the number of nodes by assembling similar behavior patterns into macro nodes, which addresses the computational difficulty of Graph Neural Networks.
- Machine learning predicts which rivers, streams, and wetlands the Clean Water Act regulates. Our framework can support permitting, policy design, and the use of machine learning in regulatory implementation problems.
- Weaver: Foundation Models for Creative Writing. A group of models called Weaver have been trained especially to narrate stories. On a benchmark for storytelling, the biggest model (34B params) performs better than GPT-4.
- Text Image Inpainting via Global Structure-Guided Diffusion Models. In this study, two datasets for handwritten words and scenes are introduced, along with a benchmark. With original, damaged, and assistant photos, the new Global Structure-guided Diffusion Model (GSDM) effectively recovers clean texts by making use of text structure. Both picture quality and identification accuracy demonstrate notable gains.
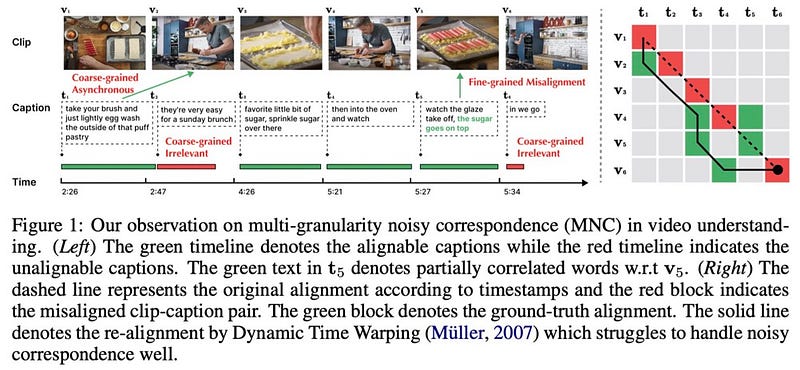
- Multi-granularity Correspondence Learning from Long-term Noisy Videos. With Norton, the multi-granularity noisy correspondence problem in video-language studies is addressed, offering a novel strategy for enhancing long-term video comprehension.
- GPAvatar: Generalizable and Precise Head Avatar from Image(s). With the use of a Multi Tri-planes Attention module and a dynamic point-based expression field, GPAvatar presents a novel technique for generating 3D head avatars from photos.
- MobileDiffusion: Rapid text-to-image generation on-device. With certain architectural modifications, Google has demonstrated a latent consistency diffusion model that it trained for sub-second generation times on mobile devices.
- SNP-S3: Shared Network Pre-training and Significant Semantic Strengthening for Various Video-Text Tasks. Shared Network Pre-training (SNP) enhances the joint learning of text and video. Compared to earlier models, this approach is more effective and adaptable and incorporates a novel technique called Significant Semantic Strengthening (S3) to improve comprehension of important terms in sentences.
- Hi-SAM: Marrying Segment Anything Model for Hierarchical Text Segmentation. An improved version of the Segment Anything Model (SAM) with a focus on hierarchical text segmentation is called Hi-SAM. Hi-SAM is an excellent text segmenter at several levels, ranging from strokes to paragraphs, and it can even analyze layouts.
News
- Voltron Data acquires Claypot to unlock real-time AI with modular data systems. Today, San Francisco-based Voltron Data, a startup providing enterprises with a modular and composable approach to building systems for data analytics, confirmed to VentureBeat that is acquiring the real-time AI platform Claypot. The terms of the deal were not disclosed.
- FTC investigating Microsoft, Amazon, and Google investments into OpenAI and Anthropic. The commission wants to understand the tangled web of investments between cloud providers and AI startups.
- Google’s New AI Is Learning to Diagnose Patients. The DeepMind team turns to medicine with an AI model named AMIE
- 1/100th of the cost: CPU startup Tachyum claims that one of its processing units can rival dozens of Nvidia H200 GPUs — with a 99% saving that could turn the AI market on its head if true. The 5nm Prodigy processor can dynamically switch between AI, HPC, and cloud workloads and costs $23,000
- ChatGPT is violating Europe’s privacy laws, Italian DPA tells OpenAI. OpenAI has been told it’s suspected of violating European Union privacy, following a multi-month investigation of its AI chatbot, ChatGPT, by Italy’s data protection authority.
- This whimsical clock is the playful gadget AI needs right now. The Poem/1 clock dreams up a new poem every minute to tell you the time. Do you need it? No. But you might want it.
- iOS 17.4: Apple continues work on AI-powered Siri and Messages features, with help from ChatGPT. Apple is widely expected to unveil major new artificial intelligence features with iOS 18 in June. Code found by 9to5Mac in the first beta of iOS 17.4 shows that Apple is continuing to work on a new version of Siri powered by large language model technology, with a little help from other sources.
- Opera to launch new AI-powered browser for iOS in Europe following Apple’s DMA changes. Opera revealed today that it will launch a new AI-powered browser built on its own engine for iOS in Europe. The Norway-based company announced the change following the news that Apple is going to allow alternative browser engines to run on iOS as a result of the requirements of the European Digital Markets Act (DMA).
- Mistral CEO confirms ‘leak’ of new open source AI model nearing GPT-4 performance. The past few days have been a wild ride for the growing open-source AI community — even by its fast-moving and freewheeling standards.
- Microsoft LASERs away LLM inaccuracies.Microsoft’s LASER method seems counterintuitive, but it makes models trained on large amounts of data smaller and more accurate.
- LLaVA-1.6: Improved reasoning, OCR, and world knowledge. The most recent iteration of the visual language model Llava features enhanced reasoning, global knowledge, and OCR. It complements Gemini in some duties. The model, code, and data will be made available by the Llava team.
- ServiceNow’s statement on AI. The $150 billion market capitalization business ServiceNow revealed last week that, among all of its new product family launches, including its initial Pro SKU, its generation AI solutions generated the biggest net new ACV contribution for the first full quarter. It’s exciting to see that enterprise-level AI applications are already contributing to significant revenue growth.
- Bard’s latest updates: Access Gemini Pro globally and generate images. You can now generate images in Bard in English in most countries around the world, at no cost. This new capability is powered by our updated Imagen 2 model
- Amazon debuts ‘Rufus,’ an AI shopping assistant in its mobile app. Amazon announced today the launch of an AI-powered shopping assistant it’s calling Rufus who’s been trained on the e-commerce giant’s product catalog as well as information from around the web.
Resources
- imp-v1–3b. An additional multimodal model was trained using SigLIP and Phi-2. This one is tiny enough to run on-device and provides very promising performance.
- WebDataset. WebDataset is a library for writing I/O pipelines for large datasets. Its sequential I/O and sharding features make it especially useful for streaming large-scale datasets to a DataLoader.
- LLMs-from-scratch.An unfinished yet intriguing series of exercises to teach language model building from the beginning.
- Exploring ColBERT with RAGatouille. For RAG applications, ColBERT is a great paradigm for embedding queries and index data. This article runs some benchmarks and examines the method’s underlying intuition.
- mamba.rs. Inspired by efforts on the Llama models, this project uses pure Rust to run inference for Mamba on the CPU.
- 🦙 Code Llama. Code Llama is a code-specialized version of Llama 2 that was created by further training Llama 2 on its code-specific datasets, sampling more data from that same dataset for longer.
- Eagle 7B : Soaring past Transformers with 1 Trillion Tokens Across 100+ Languages (RWKV-v5). A brand new era for the RWKV-v5 architecture and linear transformer has arrived — with the strongest multi-lingual model in open source today
- InconsistencyMasks. A novel technique for picture segmentation called Inconsistency Masks (IM) functions even with sparse data. Tested on the ISIC 2018 dataset, our method performs better than conventional methods and even surpasses models trained on fully labeled datasets.
- distortion-generator. A novel technique for picture distortion strikes a compromise between privacy and accuracy in biometric systems, rendering facial photos incomprehensible to humans yet identifiable to AI.
- TaskingAI. TaskingAI brings Firebase’s simplicity to AI-native app development. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process.
- 100x Faster Clustering with Lilac Garden. A difficulty in language model training is locating a sufficiently varied dataset. It is considerably more difficult to visualize this data. This useful tool facilitates data exploration to enhance filtering and overall quality through topic modeling and quick clustering.
- float8_experimental. Although less precise model training is quicker and less expensive, it is less reliable. Quantized training has been the subject of several excellent contemporary studies. Building on those foundations, this repository offers float8 teaching through readable and hackable code.
- Enchanted. Enchanted is an open-source, Ollama-compatible, elegant iOS/iPad mobile app for chatting with privately hosted models such as Llama 2, Mistral, Vicuna, Starling, and more. It’s essentially ChatGPT app UI that connects to your private Ollama models. You can download Enchanted from the App Store or build yourself from scratch.
- Introduction to point processing. Whether you are doing medical image analysis or you use Photoshop, you are using point preprocessing
- MF-MOS: A Motion-Focused Model for Moving Object Segmentation. A new model called MF-MOS makes use of LiDAR technology to more effectively identify moving objects during autonomous driving. Using residual maps for motion capture and range pictures for semantic guiding distinguishes motion from semantic information in a unique way.
- Mctx: MCTS-in-JAX. Mctx is a library with a JAX-native implementation of Monte Carlo tree search (MCTS) algorithms such as AlphaZero, MuZero, and Gumbel MuZero. For computation speed up, the implementation fully supports JIT-compilation.
- FireLLaVA: the first commercially permissive OSS LLaVA model. A new open-vision model called FireLlava can be used for commercial applications after it is trained on data. It performs similarly to the first Llava, but not quite as well as Llava 1.5.
- uAgents: AI Agent Framework. uAgents is a library developed by Fetch.ai that allows for the creation of autonomous AI agents in Python. With simple and expressive decorators, you can have an agent that performs various tasks on a schedule or takes action on various events.
- teknium/OpenHermes-2.5. Some of the top open models available have been trained using data from OpenHermes-2.5. More than one million high-quality data points are included in the collection. It’s now available for purchase.
- OLMo: Open Language Model. A State-Of-The-Art, Truly Open LLM and Framework
- BAAI/bge-m3. A flexible embedding model that performs very well in multi-functionality (dense, multi-vector, and sparse retrieval), multi-linguistic (supporting more than 100 languages), and multi-granularity (managing inputs ranging from brief phrases to documents with up to 8192 tokens) is presented by the BGE-M3 project. It makes use of a hybrid retrieval pipeline, which leverages its simultaneous embedding and sparse retrieval capabilities, to combine several techniques and re-ranking for increased accuracy and generalization.
- RAGs. Using natural language, users can develop RAG pipelines from data sources with the help of the Streamlit app RAGs. All users need to do is specify the parameters and tasks they require from their RAG systems. You can query the RAG, and it will respond to inquiries about the information.
- GPT Newspaper. GPT Newspaper project, an innovative autonomous agent designed to create personalized newspapers tailored to user preferences. GPT Newspaper revolutionizes the way we consume news by leveraging the power of AI to curate, write, design, and edit content based on individual tastes and interests.
Perspectives
- Many AI Safety Orgs Have Tried to Criminalize Currently-Existing Open-Source AI. Numerous teams are attempting to address the difficulties posed by the quickly developing field of artificial intelligence.
- AlphaFold found thousands of possible psychedelics. Will its predictions help drug discovery? Researchers have doubted how useful the AI protein-structure tool will be in discovering medicines — now they are learning how to deploy it effectively.
- Reaching carbon neutrality requires energy-efficient training of AI. Artificial intelligence (AI) models have achieved remarkable success, but their training requires a huge amount of energy.
- What will robots think of us? Two recent science fiction novels humorously illustrate the importance of correct robot mental models.
- What Can be Done in 59 Seconds: An Opportunity (and a Crisis). AI is already capable of completing several jobs in less than a minute, thus businesses and staff will need to stress the need to utilize AI for good rather than evil.
- The American Dynamism 50: AI. This list of 50 companies, compiled by a16z, addresses some of the most important issues facing the US in the areas of manufacturing, transportation, energy, and military. They’re all utilizing AI to speed up their work in one way or another. This is an excellent insight if you’re interested in practical uses of artificial intelligence.
Meme of the week

What do you think about it? Some news that captured your attention? Let me know in the comments
If you have found this interesting:
You can look for my other articles, and you can also connect or reach me on LinkedIn. Check this repository containing weekly updated ML & AI news. I am open to collaborations and projects and you can reach me on LinkedIn.
Here is the link to my GitHub repository, where I am collecting code and many resources related to machine learning, artificial intelligence, and more.
or you may be interested in one of my recent articles: