
ML-E8: Machine learning basics (bias, variance, over-fitting, accuracy, precession, validation etc)
Machine learning (ML) is a powerful field that applies computational and statistical techniques to empower computer systems to learn and improve from experience, without explicit programming.
This article will cover essential basics, including primary types of ML tasks, essential concepts, and various processes involved in machine learning.
ML series menu: E1 E2 E3 E4 E5 E6 E7 E8 E9
Section 1: Types of Machine Learning Tasks
Machine learning tasks can broadly be divided into two categories: classification and regression. The distinction lies in the nature of the output or prediction that the machine learning model is trained to produce.
1.1 Classification
Classification is a type of machine learning task where the output variable is a category or a class. It involves predicting the class or category of an object or sample. Examples of classification algorithms include Logistic Regression, Decision Trees, Random Forest, Support Vector Machines (SVM), and Neural Networks.
Example: Consider an email spam detection system. Here, the system classifies emails into two categories — “Spam” or “Not Spam.” This is a binary classification problem.
1.2 Regression
Regression, on the other hand, is a machine learning task where the output variable is a real or continuous value. It involves predicting a quantity. Linear Regression, Polynomial Regression, Decision Trees, Random Forests, and Support Vector Regression are examples of regression algorithms.
Example: Consider a house price prediction system. Here, the system predicts a real-valued price based on various features such as the location, the number of rooms, etc. This is a regression problem.
Section 2: Bias vs Variance
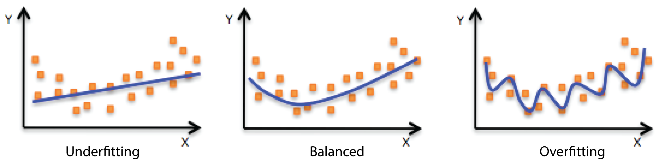
One of the key challenges in machine learning is balancing bias and variance.
2.1 Bias
Bias in machine learning refers to the error due to the model’s assumptions in the learning algorithm. High bias can lead to an oversimplified model that may ignore important trends in the data. This situation is called underfitting.
2.2 Variance
Variance, on the other hand, refers to the error due to the model’s sensitivity to small fluctuations in the training set. High variance can cause overfitting, where the model performs well on the training data but poorly on unseen data.
Balancing bias and variance is critical for a model to generalize well from the training data to unseen data.
Section 3: Evaluation Metrics
The selection of a performance metric in a machine learning project largely depends on the specific problem and the business context. However, in general, the following are commonly used:
- Accuracy: In classification problems, accuracy is one of the most commonly quoted metrics. It’s straightforward and easy to understand as it simply tells us the proportion of correct predictions made by the model.
- Area Under the Receiver Operating Characteristic (AUROC): AUROC is commonly used in binary classification problems, especially in medical testing, as it provides a single measure of a model’s performance at various threshold settings. It measures the entire two-dimensional area underneath the curve (AUC) of true positive rate (TPR) against false positive rate (FPR).
- F1 Score: In situations where the data is imbalanced, or when the cost of false positives and false negatives are significantly different, the F1 score is often used. It is the harmonic mean of precision and recall and seeks to balance these two values.
- Mean Absolute Error (MAE) or Root Mean Squared Error (RMSE): For regression problems, MAE and RMSE are often quoted as they give a sense of how much the model’s predictions deviate, on average, from the actual values in the dataset.
- R-squared: It’s also a commonly used metric in regression that explains the proportion of variance in the dependent variable that can be explained by the independent variables.
It’s important to note that while these metrics are often quoted, the best metric to use will depend on the specific objectives of your project and the nature of your data. In practice, you often will end up using multiple metrics to evaluate your models and to guide your model selection process.
Confusion matrix
In classification problems, we have the famous confusion matrix that lets us define a bunch of sub-metrics:
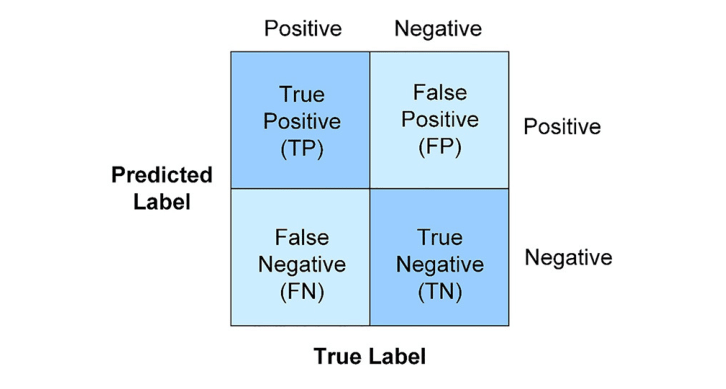

3.1 Accuracy
Accuracy is the fraction of correct predictions made by the model out of all predictions. It’s a common metric for classification problems.
3.2 Precision
Precision is the fraction of relevant instances among the retrieved instances. In other words, it answers the question, “What proportion of positive identifications was correct?”
3.3 Recall
Recall (or sensitivity) is the fraction of the total amount of relevant instances that were retrieved. In other words, it answers the question, “What proportion of actual positives was identified correctly?”
3.4 Specificity
Specificity is a vital performance measure in machine learning, specifically used in binary classification problems.
While recall (or sensitivity) focuses on the true positive rate, specificity provides the true negative rate. It is defined as the proportion of actual negative instances that are correctly identified as such.
Specificity answers the question, “What proportion of actual negatives was identified correctly?” In other words, it shows how good the model is at avoiding false alarms. High specificity indicates that the model is highly capable of correctly identifying negative outcomes.
3.5 F1 Score
The F1 score is the harmonic mean of precision and recall. It tries to find the balance between precision and recall. An F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0.
Section 4: Dataset Splitting
In machine learning, data is typically divided into three sets: training set, validation set, and test set.
4.1 Training Set
The training set is used to train the model. It is where the model learns to recognize patterns or relationships between features and the target variable.
4.2 Validation Set
The validation set is used to provide an unbiased evaluation of the model’s fit on the training set while tuning model hyperparameters. It is a checkpoint to ensure the model is learning correctly.
4.3 Test Set
The test set provides the final, unbiased assessment of the model. It is used to evaluate the model’s performance after training and validation, and should only be used once the model is completely trained.
Section 5: Fitting, Validation, and Prediction
5.1 Fitting
Fitting is the process where a machine learning model learns the mapping function from the input variables to the output variable using the training data. The model identifies patterns and relationships in the data during the fitting process.
5.2 Validation and Testing
Validation is the process of checking whether the model has learned effectively from the training data. The model’s predictions on the validation set are compared to the actual values to measure its performance and fine-tune hyperparameters.
After the model has been trained and validated, it must be tested. The purpose of the test set is to provide an unbiased evaluation of the final model. Testing allows for the assessment of how well the model is likely to perform on future, unseen data. This set is only used once the model has been finalized (after processes like training and validation are complete). The performance on the test set gives a final estimate of the model’s accuracy (or other relevant evaluation metrics), and represents how the model will perform in real-world scenarios. It’s crucial not to use the test set for model training or hyperparameter tuning to avoid overfitting and ensure an unbiased evaluation.
5.3 Prediction
Prediction is the final step in the machine learning process, where the fully trained model is used to predict the output for new, unseen data.
Section 6: Cross-Validation
Cross-validation is a robust method for assessing the performance of machine learning models. It reduces overfitting and provides a better understanding of the model’s ability to generalize to unseen data.
In k-fold cross-validation, the training set is randomly partitioned into k equal-sized subsamples. Of the k subsamples, a single subsample is retained as the validation set for testing the model, and the remaining k-1 subsamples are used as training data. The process is repeated k times, with each subsample used exactly once as the validation data. The k results from the folds are then averaged to produce a single estimation.
Section 7: Parameters vs Hyperparameters
In machine learning, the concepts of parameters and hyperparameters are fundamental, though they serve very different roles in the context of modeling. Understanding the distinction between them is vital for implementing and fine-tuning algorithms effectively.
7.1 Parameters
Parameters are internal variables that the model learns during the training process. They are the part of the model that is updated in response to the training data. In a linear regression model, for example, the coefficients or weights applied to input features are parameters. The model’s goal is to learn the best set of parameters that accurately map the input to the output.
7.2 Hyperparameters
Contrary to parameters, hyperparameters are external configurations that are not learned from the data. They are set prior to the commencement of the learning process and remain constant during training. Examples of hyperparameters include the learning rate in many machine learning algorithms, the depth of a decision tree, or the number of hidden layers in a neural network.
Hyperparameters play a crucial role in determining the performance of a machine learning model. They are usually tuned during the validation process to find the optimal values that produce the best performing model. This tuning process often involves techniques like grid search or randomized search to explore a range of potential values.
Conclusion
Understanding the basics of machine learning, such as task types, bias and variance, evaluation metrics, data splitting, fitting, validation, prediction, and cross-validation, is crucial to further exploring this field. Machine learning has tremendous potential, and knowing these fundamentals enables more effective application and interpretation of machine learning models.