
Mistral 7b Outperforms GPT-4 in Specialized Tasks
Predibase recently released 25 fine-tuned LLMs that outperform GPT-4, that can be served on a single GPU.
Before getting into the details, there are 4 important facts that you need to know about small LLMs:
- Small LLMs can consistently outperform larger, generalist language models, such as GPT-4.
- They can specialize in wide variety of tasks using Parameter Efficient Fine-tuning (PEFT), which provides lower memory footprint and faster fine-tuning. You can make this process even faster with techniques such as QLoRA, i.e., with 4-bit quantization, without sacrificing the performance.
- Many specialized tasks are intrinsically low-rank and LoRA adapters are much cheaper to fine-tune and serve. In fact, you can serve many LoRA adapters using a single GPU, using libraries such as SLoRA or Lorax. The models that we will have a look at shortly cost less than $8 per adapter, and all 25 of them can be served off of a single A100 GPU!
- Production applications with real-world traffic requires performance and low-latency at the same time, which make smaller models a great fit.
In this article, I will walk you through:
- The chosen datasets that benchmark these LLMs against GPT-4.
- The diverse categories and specific tasks these models ace.
- How their performance stacks up through rigorous evaluations.
- Insights into the fine-tuned models
- Serving LoRA adapters on single GPU
Let’s go!

Datasets for Evaluation
Let’s have a look at the datasets used for fine-tuning:
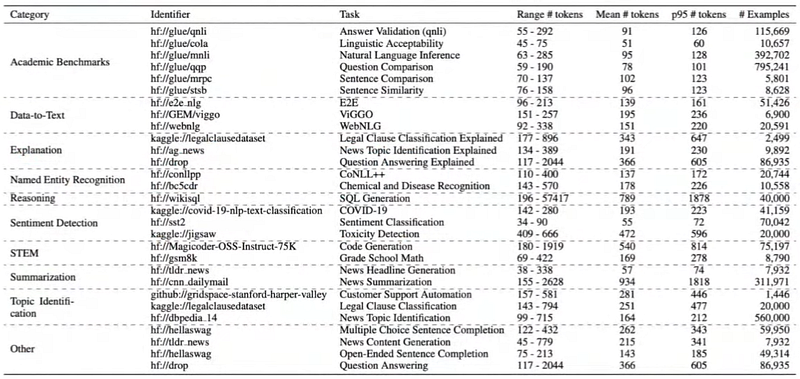
Predibase team selected the datasets based on their common use in benchmarking or serving as a proxy for specific industry tasks — many of them will be familiar if you have been fine-tuning models.
Fine-tuning Categories and Tasks
You can see that these models are trained for certain Categories and Tasks , here’s a brief overview:
Academic Benchmarks
- Answer Validation (QNLI): Determines whether a given answer is valid for a posed question.
- Linguistic Acceptability (CoLA): Judges whether an English sentence is linguistically acceptable.
- Natural Language Inference (MNLI): Predicts whether a hypothesis is true (entailment), false (contradiction), or undetermined (neutral) given a premise.
- Question Comparison (QQP): Determines if two questions are semantically equivalent.
- Sentence Comparison (MRPC): Identifies whether two sentences are semantically equivalent.
- Sentence Similarity (STSB): Measures the similarity between two sentences.
Explanation
- News Topic Identification Explained (ag_news): Categorizes and explains the categorization of news articles into predefined topics.
- Question Answering Explained (drop): Provides answers to questions with explanations based on given contexts.
Named Entity Recognition
- Chemical and Disease Recognition (bc5cdr): Identifies chemical and disease mentions in text.
- Named Entity Recognition (CoNLL++): Identifies and classifies named entities in text into predefined categories.
Reasoning
- WikiSQL (SQL Generation): Generates SQL queries from natural language questions.
Sentiment Detection
- Sentiment Detection (COVID-19): Detects sentiment in text related to COVID-19.
- Sentiment Detection (SST2): Identifies positive or negative sentiment in sentences.
- Toxicity Detection (Jigsaw): Identifies toxic comments and content.
STEM
- Code Generation (magicoder): Automatically generates code snippets from natural language descriptions.
- Grade School Math (gsm8k): Solves grade-school level math problems.
Structured-to-Text
- Structured-to-Text (e2e_nlg): Converts structured data into natural language text.
- Structured-to-Text (viggo): Generates descriptive text from structured information in the context of video games.
Summarization
- News Headline Generation (tldr_news): Creates headlines for news articles.
- News Summarization (cnn): Summarizes news articles into concise versions.
Topic Identification
- Customer Support Automation: Automates responses to common customer support inquiries.
- Legal Clause Classification: Classifies text into different types of legal clauses.
- News Topic Identification (dbpedia): Categorizes news articles into predefined topics based on DBpedia classes.
Other
- Multiple Choice Sentence Completion (hellaswag): Chooses the correct ending to a sentence from multiple options.
- News Content Generation (tldr_news): Generates brief news articles based on given prompts.
- Open-Ended Sentence Completion (hellaswag): Completes sentences in an open-ended manner without multiple-choice options.
- Question Answering (drop): Answers questions based on a given context or passage.
Let’s have a look at their performance.
Performance Evaluation
To better understand the performance of these models, Predibase team various metrics for evaluation.
Accuracy and ROGUE are used as primary metrics together with HumanEval and GSM8K.
The average quality across 27 tasks was 0.661 for Mistral-7b adapters using QLoRA, whereas GPT-4 scored 0.535.
A kind request here:
All the resources we offer for free are part of our grand vision, a commitment to a world where everyone has skills and tools to put AI to work for themselves, driving positive change and innovation in their lives.
That’s why, we pour our passion, expertise, and countless hours into creating content that we believe can make a difference in your journey.
But here’s a surprising fact: Out of the thousands who benefit from our content, only a mere 1% engage or follow us on Medium.
If you ever found value in our work, please take a moment to follow us on Medium, clap this article and leave a comment — it’s a small gesture, but it means the world to us and helps us tailor our content to your aspirations.
Thank you for stopping by, and being an integral part of our community.
You can see the detailed view here:
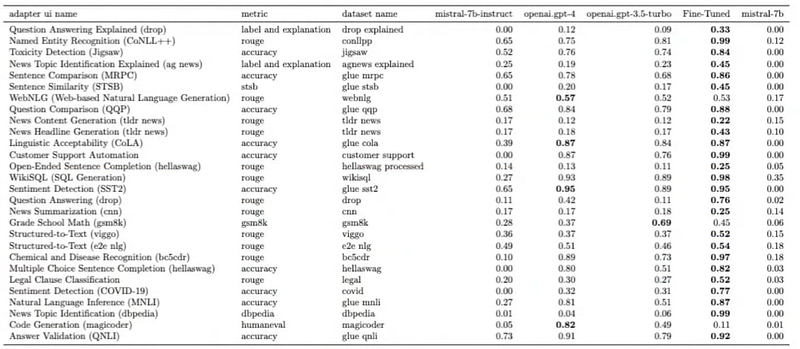
And this is another view that shows the difference in performance between Mistral 7b fine-tuned models and GPT-4:
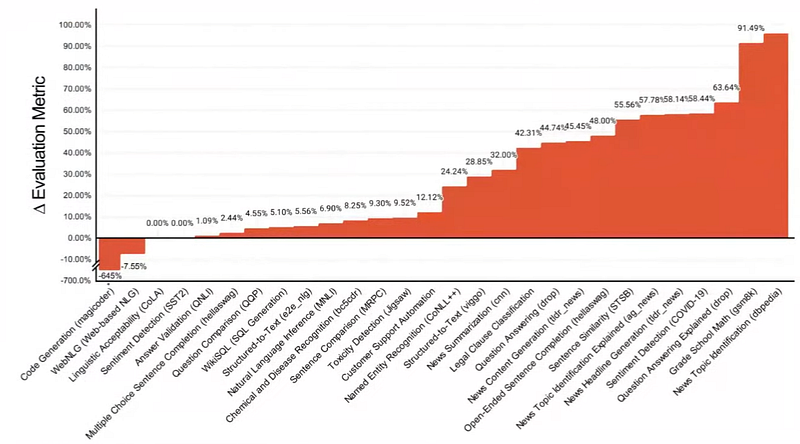
You can see that the percentage differences can go as high as 91%, and that’s where you may want to start comparing to see how capable these models are.
Fine-tuned Mistral 7B Models
Ready to play around?
All you need to do is to navigate to LoRA Land, and start experimenting with different categories and tasks.
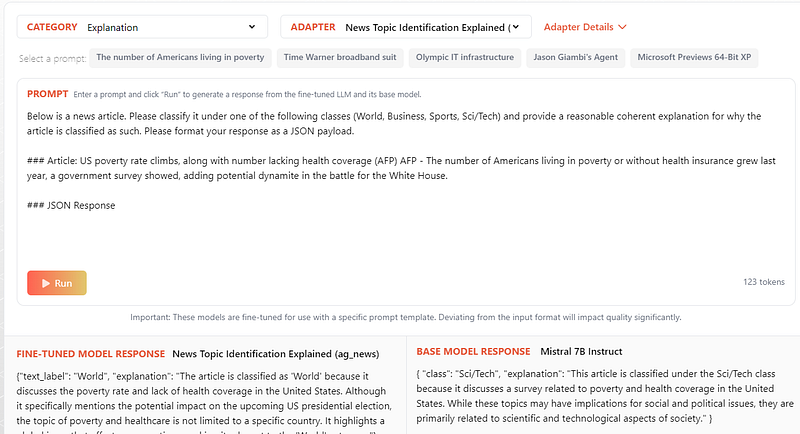
You can also try the models in your own environment.
To do that, you can get the models from Predibase’s Hugging Face page.
Serving LoRA Adapters with LoRAX
LoRAX (LoRA eXchange) is Multi-LoRA inference server that scales to 1000s of fine-tuned LLMs. It’s built on top of Hugging Face’s text-generation-inference.
You can serve thousands of fine-tuned models on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency — Predibase
Here’s a brief look at the LoRAX features:
- Dynamic Adapter Loading: Quickly integrates and loads LoRA adapters on-demand, enabling powerful ensemble capabilities.
- Heterogeneous Continuous Batching: Consolidates various adapter requests, ensuring stable latency and throughput.
- Adapter Exchange Scheduling: Efficiently swaps adapters between GPU and CPU, optimizing system throughput.
- Optimized Inference: Enhances performance with tensor parallelism, advanced CUDA kernels, quantization, and token streaming.
- Production-Ready Tools: Offers Docker images, Kubernetes charts, monitoring, and isolation features for robust deployment.
- Free Commercial Use: Available under the Apache 2.0 License, allowing commercial deployment without licensing fees.
For a quick start, launch the Docker server:
model=mistralai/Mistral-7B-Instruct-v0.1
volume=$PWD/data
docker run --gpus all --shm-size 1g -p 8080:80 -v $volume:/data \
ghcr.io/predibase/lorax:latest --model-id $modelPrompt the base LLM:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{
"inputs": "[INST] Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? [/INST]",
"parameters": {
"max_new_tokens": 64
}
}' \
-H 'Content-Type: application/json'Then prompt the LoRA adapter:
curl 127.0.0.1:8080/generate \
-X POST \
-d '{
"inputs": "[INST] Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? [/INST]",
"parameters": {
"max_new_tokens": 64,
"adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"
}
}' \
-H 'Content-Type: application/json'There is also a Python client:
# pip install lorax-client
from lorax import Client
client = Client("http://127.0.0.1:8080")
# Prompt the base LLM
prompt = "[INST] Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? [/INST]"
print(client.generate(prompt, max_new_tokens=64).generated_text)
# Prompt a LoRA adapter
adapter_id = "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"
print(client.generate(prompt, max_new_tokens=64, adapter_id=adapter_id).generated_text)That’s it, I hope you will leverage some of these models in your projects!
Let me know if you have any questions in the comments, see you next time around.




