
Mistral 7B Beats Llama v2 13B on All Benchmarks: Overview and Fine-tuning
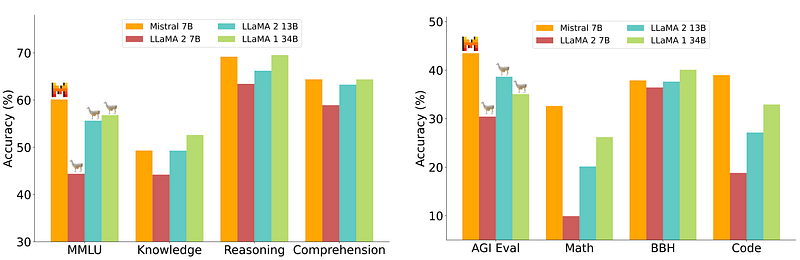
A few days ago, the Mistral AI team released Mistral 7B, which beats Llama 2 13B on all benchmarks and Llama 1 34B on many benchmarks, and is almost on par with CodeLlama 7B.
“Community-backed model development is the surest path to fight censorship and bias in a technology shaping our future” — Mistral AI

Looking good!
If you are running macOS or Linux, you can try it locally using Ollama. It should give you 25 tokens/second on a low-end Macbook based on reports, which is already reasonable - we want to hear what performance you get out of your system, and we’d appreciate it if you could drop that in the comments.
Let’s see how Mistral AI team created this beast.
There are 3 techniques that Mistral 7B leveraged to offer faster inference and the ability to handle longer sequences with minimal computational overhead.
1. Grouped-query attention (GQA)
Attention mechanisms, the cornerstone of transformer architectures, have traditionally been computationally intensive, especially when dealing with long sequences. GQA offers a solution by grouping queries together and computing their attention simultaneously. This approach reduces the number of attention computations, leading to a significant speed-up in model inference without compromising accuracy.
The brilliance of GQA lies in its simplicity. Instead of computing attention for each query individually, queries are grouped, and attention is computed for the entire group at once. This batching technique reduces the computational burden, making the model faster and more efficient.
2. Sliding Window Attention (SWA)
As language models grow in size and complexity, the ability to handle longer sequences becomes paramount. Traditional attention mechanisms struggle with long sequences due to quadratic computational complexity. SWA allows models to attend over longer sequences without a proportional increase in computation.
SWA employs a “window” approach. For each token, the model only attends to a fixed-size window of neighboring tokens. This window slides across the sequence, ensuring each token can attend to its immediate neighbors. The result? A linear computational complexity makes it feasible to process longer sequences without a dramatic increase in computational cost.
3. Byte-fallback BPE tokenizer
The Byte-fallback BPE tokenizer offers several advantages when fine-tuning large language models:
- Coverage: Traditional tokenizers might not handle out-of-vocabulary (OOV) words well. With the Byte-fallback BPE tokenizer, every possible word or character sequence can be tokenized, ensuring no word is left as an OOV. This is especially crucial for domain-specific terms that might not be present in the general vocabulary.
- Flexibility: The tokenizer can adapt to various languages and scripts, making it versatile for multilingual models or models that need to understand domain-specific languages or jargon.
- Efficiency: It provides a balance between word-level and character-level tokenization, ensuring that the token sequences are neither too long (as with character-level tokenization) nor miss out on nuances (as with word-level tokenization).
For enterprise use cases, especially when fine-tuning domain-specific large language models (LLM), the Byte-fallback BPE tokenizer can be useful. Enterprises often deal with niche terminologies, product names, or industry-specific jargon that might not be part of the standard vocabulary. Using this tokenizer ensures that these terms are effectively tokenized and understood by the model.
Apache 2.0 Commercial Use License
Mistral 7B is released under the Apache 2.0 license, you can use it without restrictions — there are 3 options:
- Download it and use it anywhere (including locally) with a Mistral AI’s reference implementation
- Deploy it on any cloud (AWS/GCP/Azure), using the vLLM inference server and skypilot
- Use it on HuggingFace
“This is the result of three months of intense work, in which we assembled the Mistral AI team, rebuilt a top-performance MLops stack and designed a most sophisticated data processing pipeline, from scratch” — Mistral AI

While Mistral AI didn’t provide the cut-off date for its training data, several examples show that it’s sometime in 2023.
Fine-tuning Mistral 7B
Businesses seek to harness the power of AI in diverse domains, and open-source models are important in terms of transparency and adaptability in these domains. Open-source LLMs also enable the auditing of generative systems and the detection of misuse, ensuring a more trustworthy and reliable AI ecosystem.
Different versions of the Mistral 7B on HuggingFace are already growing fast and there are a few community resources that you can use to start fine-tuning Mistral 7B for your own use case.
A Personal Request to Our Valued Reader:
We envision a future where every individual is equipped with the knowledge and tools to harness the power of AI, driving positive change and innovation in the world.
Each article we publish, every notebook we share, and all the resources we offer are a testament to our commitment to this vision. We pour our passion, expertise, and countless hours into creating content that we believe can make a difference in your journey.
But, here’s a surprising fact: Out of the thousands who benefit from our content, only a mere 1% choose to follow us on Medium. Our dream is to see that number rise to 10%. Why? Because every follow is a vote of confidence, a sign that we’re on the right track, and an indicator of the topics and resources you’d love to see more of.
If you ever found value in our work, if you believe in a world empowered by AI, and if you’d like to be part of this exciting journey with us, please take a moment to Follow Us on Medium. It’s a small gesture, but it means the world to us and helps us tailor our content to your needs.
Thank you for being an integral part of our community. Together, let’s shape the future of AI.
Start with one of the following resources,
- Harper Carroll’s walkthrough for fine-tuning Mistral 7B
- Phill Schmid’s training script to fine-tune Mistral 7B using AWS SageMaker
and let us know if you want to know more about specific steps or stages of the fine-tuning process.
If you are interested in fine-tuning Llama v2 13B, check out the guide we recently released:
That’s it, enjoy Mistral 7B and we will see you another time!




