
Microsoft’s Medprompt+ with GPT-4 Beats Gemini Ultra, Reclaims Benchmark Throne on MMLU

Well that was quick! Gemini Ultra from Google DeepMind’s purportedly superior performance benchmarks against OpenAI’s GPT-4 has been short-lived.
Microsoft Research just released a blog post about its Medprompt+ approach on GPT-4, retaking the benchmark throne against Gemini Ultra which was announced only a week ago.
Medprompt and its Evolution: Developed by a team at Microsoft Research, Medprompt represents a significant leap in prompting strategies. It utilizes specialized techniques to draw out the expertise-like responses from AI models. The approach has been extended into a more robust version, known as Medprompt+, which integrates simple and complex prompting methods. This combination has been instrumental in achieving state-of-the-art (SoTA) results on various benchmarks.
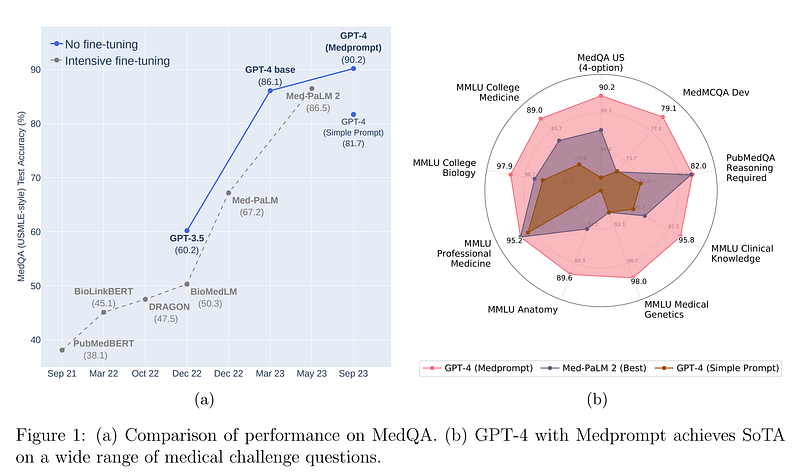
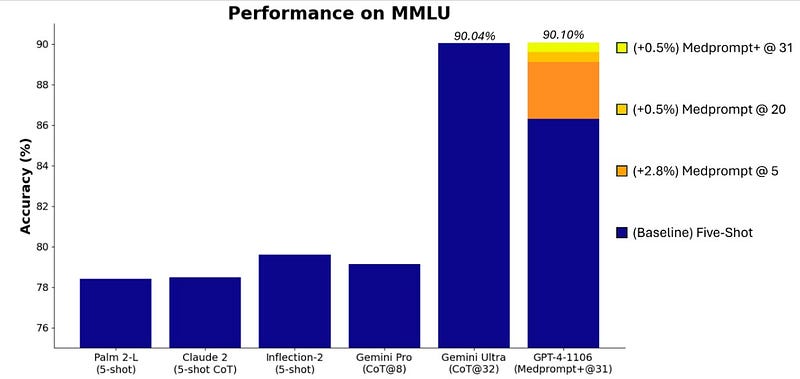
Performance on MMLU Benchmark: The Measuring Massive Multitask Language Understanding (MMLU) challenge is a comprehensive test of general knowledge and reasoning abilities of large language models. The Medprompt approach has shown exceptional performance on this benchmark, with the modified version, Medprompt+, achieving a record score of 90.10%, surpassing other models like Google’s Gemini Ultra.

Promptbase — A Resource Hub: Promptbase, a repository on GitHub, has been introduced to disseminate information and tools for maximizing the performance of foundation models. It includes scripts for replicating results using the Medprompt methodologies and will continue to expand with more resources in the future.
Techniques Behind Medprompt: Medprompt combines several strategies:
- Dynamic Few Shots: This involves selecting task-specific few-shot examples dynamically, enhancing relevance and adaptability.
- Self-Generated Chain of Thought (CoT): It encourages the model to generate intermediate reasoning steps, thereby improving complex reasoning capabilities.
- Majority Vote Ensembling: This technique combines multiple outputs to yield better predictive performance, enhanced by choice-shuffling for robustness.
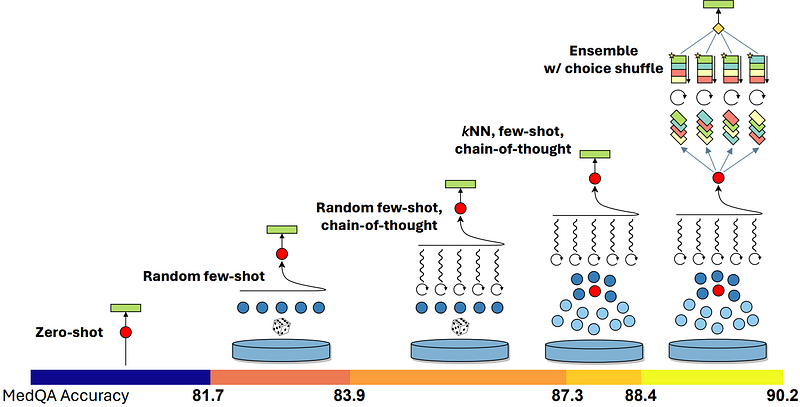
Extending Medprompt: Medprompt+ extends the original framework by incorporating simple, direct prompts alongside the sophisticated CoT-based ones. This approach dynamically selects the most appropriate technique for each problem, leading to improved performance across diverse MMLU challenges.
Future Directions: The development of Medprompt and Medprompt+ marks a significant milestone in the realm of AI prompting strategies. These methodologies not only demonstrate the capabilities of generalist models like GPT-4 in specialist domains but also pave the way for more nuanced and efficient prompting strategies. The field is rapidly evolving, and with platforms like Promptbase, the AI community can expect continuous advancements and collaborative opportunities in prompt engineering.
Gemini Ultra Controversies
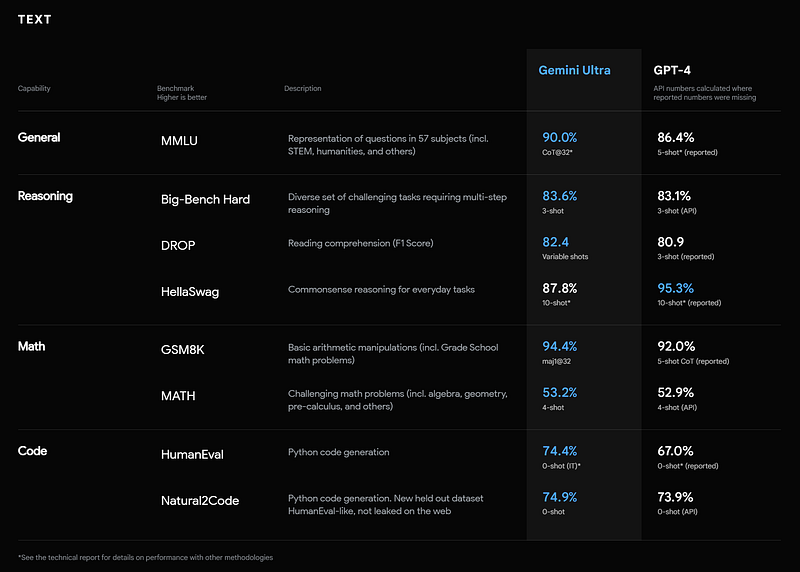
Google DeepMind’s latest AI model, Gemini has sparked intense debates on social media regarding its comparison with OpenAI’s GPT-4. Influencers are particularly focused on the evaluation methods and practical applications of these models:
- Smitarani Tripathy, Social Media Analyst, GlobalData: Highlights the debate over Gemini AI’s evaluations, noting that influencers find Gemini Ultra underperforming compared to GPT-4 in standard evaluations. The CoT@32 method is seen as impractical in real-world applications, emphasizing GPT-4’s superiority and the need for more transparent evaluations.
- Saurabh Kumar, Co-Founder, Adora: Critiques Gemini’s use of uncertainty routed CoT for claiming higher MMLU scores, pointing out GPT-4’s superior performance in standard evaluations and questioning the lack of explanation for the technique’s benefits.
- Harry Surden, Professor of Law, University of Colorado: Expresses disappointment in Gemini Ultra’s need for CoT@32 to surpass GPT-4, expecting Gemini to perform better in standard 5-shot evaluations.
- Shital Shah, Principal Research Engineer, Microsoft: Observes that while Gemini beats GPT-4 with CoT@32, it falls short in 5-shot evaluations, suggesting Gemini’s inherent power is not fully realized without proper prompting.
- Bindu Reddy, CEO, Abacus.AI: Points out that Gemini’s lead over GPT-4 in MMLU is specific to CoT@32 and that GPT-4 maintains a lead in standard 5-shot evaluations.
- Ethan Mollick, Professor, The Wharton School: Raises questions about Gemini Ultra’s capabilities and its narrow margin of outperforming GPT-4, pondering the implications for the future of large language models (LLMs).
- Brett Winton, Investment Advisor, ARK Invest: Criticizes the comparisons between prompt-engineered Gemini and non-engineered GPT-4, calling for like-for-like evaluations.
The release of Google’s Gemini AI has led to significant discussions among AI influencers, focusing on its comparative performance with GPT-4 and the methodologies used in evaluations. There is a general consensus on the need for direct, comparable evaluations to gauge the true capabilities of these models, with many influencers leaning towards GPT-4’s superiority in standard settings. The discussions highlight the evolving nature of AI technology and the complexities involved in its assessment.