
Meet GPTCache: A New Framework that Brings Caching to LLM Applications
GPTCache expands on the ideas of LLM memory by providing a general-purpose framework to store information in LLM workflows.

I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
Caching is one of the interesting emerging capabilities in language model programming(LMP). Very often, caching is associated with memory which is another novel idea of LMP apps. However, caching encompasses a wider range of use cases relative to memory. While memory focuses on storing contextual information about LLM interactions, caching includes the storage of prompts, responses, concepts, evaluation functions and many others. Among the new wave of LMP frameworks, GPTCache has excelled as a unique foundation for enabling caching capabilities in LLM solutions.
Created by Zilliz, GPTCache is a versatile open-source tool that has been meticulously designed to enhance the efficiency and speed of GPT-based applications. Its primary objective is to optimize performance by implementing a cache system capable of storing and retrieving responses generated by language models. Currently, GPTCache seamlessly supports both the OpenAI ChatGPT interface and the LangChain interface, widening its compatibility and usability. Utilizing advanced embedding algorithms, GPTCache employs a sophisticated approach to convert user queries into embeddings. These embeddings are then stored within a vector store, enabling efficient similarity searches.
The Architecture
Embracing a modular design, GPTCache ensures unparalleled flexibility for users to tailor their semantic cache. Each module comprises a comprehensive range of options, empowering users to select the most suitable configurations to fulfill their specific needs.
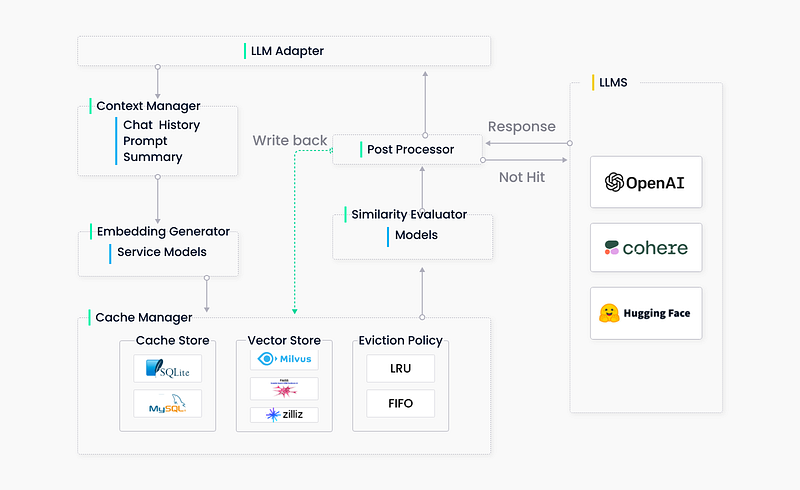
• LLM Adapter, a key component of GPTCache, seamlessly integrates with various LLM models while adhering to standardized protocols of the OpenAI API. This integration offers a unified experience, simplifying experimentation and testing across different LLM models. Notably, GPTCache extends its support to the OpenAI ChatGPT API, Langchain, and an exciting roadmap that encompasses Hugging Face Hub, Bard, Anthropic, as well as self-hosted models like LLaMa.
• The Embedding Generator within GPTCache empowers users to generate embeddings using their preferred models. With support for various embedding APIs such as OpenAI embedding API, ONNX with GPTCache/paraphrase-albert-onnx model, Hugging Face embedding API, Cohere embedding API, fastText embedding API, and SentenceTransformers embedding API, users can seamlessly extract embeddings from the request queue, facilitating subsequent similarity searches.
• Cache Storage, as the name suggests, serves as the repository for LLM responses within GPTCache. By caching these responses, GPTCache enhances the evaluation of similarity, ensuring that relevant and semantically aligned responses are promptly returned to the requester. GPTCache provides compatibility with a wide array of popular databases, including SQLite, PostgreSQL, MySQL, MariaDB, SQL Server, and Oracle.
• The Vector Store module assists in identifying the K most similar requests based on extracted embeddings from the input query. The availability of multiple vector stores, such as Milvus, Zilliz Cloud, and FAISS, through the user-friendly interface, expands the array of choices available to users.
• The Cache Manager, a vital component of GPTCache, orchestrates the operations of both the Cache Storage and Vector Store modules. When the cache reaches its capacity, GPTCache implements a replacement policy to evict data, ensuring sufficient space for new entries.
- The Similarity Evaluator module within GPTCache collects data from both the Cache Storage and Vector Store modules. Employing various strategies, this module determines the similarity between the input query and requests stored in the Vector Store.
GPTCache provides integration with several LLM frameworks such as LangChain or LLamaIndex.
Benefits
GPTCache brings a number of tangible benefits to LLM applications.
By utilizing a caching mechanism, you can achieve remarkable performance improvements in retrieving responses from your Language Model (LLM). When a response has been previously requested and resides in the cache, the time taken to fetch it is significantly reduced. Implementing response caching not only optimizes response retrieval but also enhances the overall performance of your application.
LLM services usually impose fees based on a combination of request numbers and token count. However, by intelligently caching LLM responses, you can effectively minimize the number of API calls made to the service, resulting in substantial cost savings. This becomes particularly relevant when dealing with high-traffic scenarios where expenses related to API calls can be substantial.
Implementing a caching mechanism for LLM responses can greatly enhance the scalability of your application. By reducing the load on the LLM service, caching helps avoid bottlenecks and ensures that your application can handle a growing number of requests seamlessly.
GPTCache serves as a valuable asset during the development phase of your LLM application, effectively reducing costs. Developing an LLM application necessitates continuous connections to LLM APIs, which can incur substantial expenses. GPTCache offers an identical interface to LLM APIs and can store either LLM-generated or mocked-up data. This enables you to verify your application’s features without the need for connectivity to LLM APIs or the network, resulting in cost savings.
Positioning a semantic cache in closer proximity to your users significantly reduces the time required to retrieve data from the LLM service. By effectively diminishing network latency, you can greatly enhance the overall user experience, ensuring swift and responsive interactions.
LLM services often enforce rate limits, which restrict the number of requests a user or client can make within a specific timeframe. Hitting these limits leads to service outages, as additional requests are blocked until a certain period has passed. By leveraging GPTCache, you can effortlessly scale your infrastructure to accommodate a growing volume of queries, ensuring consistent performance as your application’s user base expands.
Just like previous tech trends, caching is an emerging but very promising area of the LLM space. Technologies such as GPTCache are setting up a strong foundation for the development of this area.