Medical Image Segmentation Types and Applications
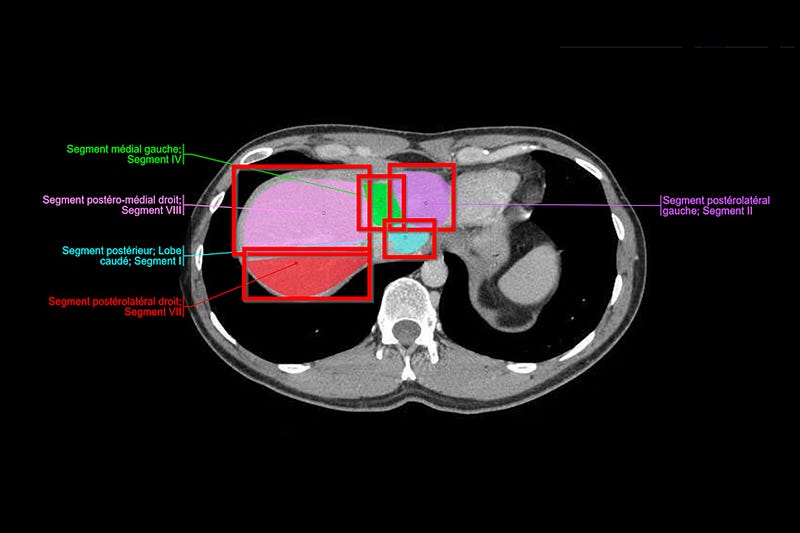
Image segmentation is a technique that separates regions of interest (ROIs) from medical images and videos. It can help you label and annotate data more efficiently and effectively when you train computer vision models for healthcare problems. This can enhance the quality and performance of your models.
By applying image segmentation, you can detect and isolate objects, divide pixels into groups, and use these groups as labels for your computer vision models.
In this story, you will learn about image segmentation in medical imaging, how it can benefit your healthcare computer vision projects, what are some of its applications, and how to implement it.
What is Medical Segmentation
Image segmentation is a technique that separates regions of interest (ROIs) from medical images and videos. It is a crucial step for annotating and labeling data, which is needed to train computer vision models (CV, AI, ML, etc.) for medical diagnostics.
This article will explain image segmentation in more detail and how it can help you with your computer vision projects.
Image segmentation can be applied to various types of medical images, such as DICOM and NIfTI images, CT scans, X-Rays, and MRI files. It can help you identify and isolate objects and regions in the images.
There are many methods for image segmentation, ranging from traditional to deep-learning based ones. All of them require high accuracy and precision, as any errors in the annotation or model-building stage can have serious implications for patients, treatments, and healthcare providers.
This guide is for medical ML, DataOps, and annotation teams and leaders who want to learn how to use image segmentation for their computer vision projects.
Medical Image Segmentation In Healthcare Computer Vision Models
Image segmentation is a technique that separates regions of interest (ROIs) from medical images and videos. It is helpful for many computer vision use cases in healthcare, such as the following:
Radiology
Radiology is a medical specialty that creates a lot of images (X-ray, mammography, CT, PET, and MRI), and healthcare organizations are using AI-based models to enhance their diagnostic quality and speed.
To train those models to find what medical professionals may not notice, or diagnose health problems more correctly, they need to label and annotate large datasets. Image segmentation can help them make better labels so that their models can be ready faster and achieve the results that healthcare organizations expect.
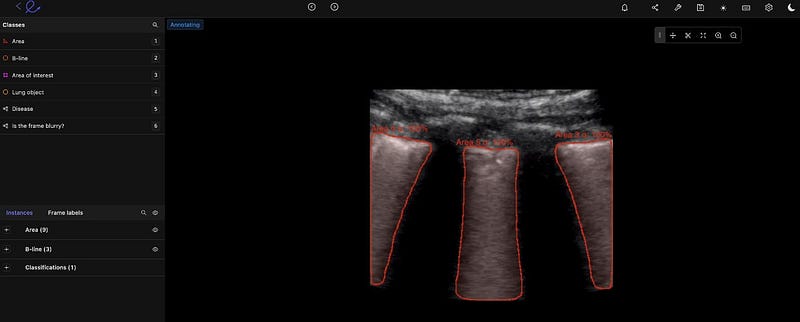
Gastroenterology
Gastroenterology GI model development is similar. We can train machine learning and computer vision models to detect cancerous polyps, ulcers, IBS, and other conditions more precisely at scale. This is especially useful for outliers and edge cases that may elude even the most experienced doctors and practice specialists.

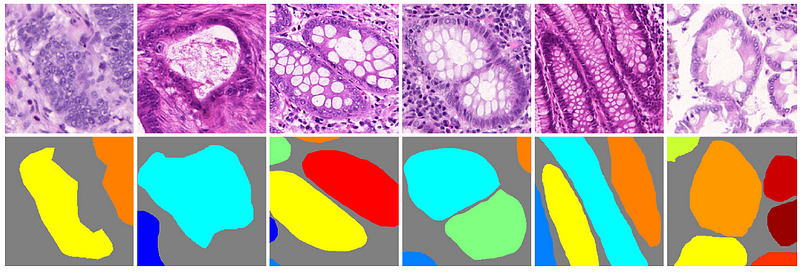
Histology
Medical image annotation is also helpful for histology, especially when AI models can correctly use common staining protocols (such as hematoxylin and eosin stain (H&E), KI67, and HER2). Image segmentation helps medical ML teams train algorithmic models, do labeling at scale, and produce more precise histology diagnoses from image-based datasets.
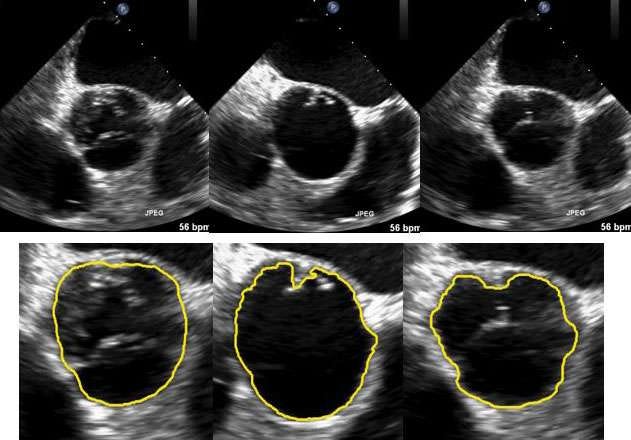
Ultrasound
Ultrasound Image segmentation can assist medical professionals in labeling ultrasound images more precisely to detect gallbladder stones, fetal deformation, and other findings.
Cancer Detection
When cancerous cells are hard to spot, or the scans are not clear, computer vision models can help with the diagnosis process. Image segmentation methods can train computer vision models to scan for the most prevalent cancers automatically, allowing medical teams to enhance detection and treatment plans.
Types of Medical Image Segmentation
Instant Segmentation
Like object detection, instance segmentation detects, labels, and segments each object in an image. This means you’re dividing the object’s edges, and you can do this manually or with AI, and you can also split objects that overlap. It’s a helpful method when you need to recognize and track individual objects.
Semantic Segmentation
Semantic segmentation is the process of assigning a label to every pixel in an image. This results in a densely labeled image, and then an AI-assisted labeling tool can use these inputs and create a segmentation map where pixel values (0,1,…255) are changed into class labels (0,1,…n).

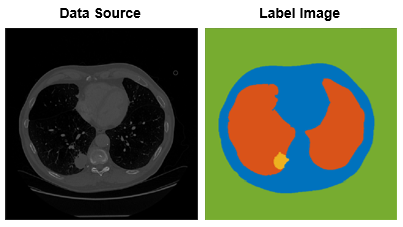
Panoptic Segmentation
Panoptic combines the two methods described above, semantic and instance. Every pixel is given a class label to recognize every object in an image. This technique offers a lot of detail and can be helpful in medical imaging for computer vision where accuracy is very important.

Thresholding Segmentation
Thresholding is a relatively easy image segmentation technique that splits pixels into classes based on a histogram intensity that matches a fixed value or threshold.
When images have little noise, threshold values can remain the same. But when images have a lot of noise, a dynamic method for choosing the threshold is better.
In most situations, a greyscale image is separated into two segments depending on their relation to the threshold value. Two of the most popular methods for thresholding are global and adaptive.
Global thresholding for image segmentation separates images into foreground and background regions, with a threshold value to distinguish them.
Adaptive thresholding segments the foreground and background using locally-set threshold values that depend on image features.
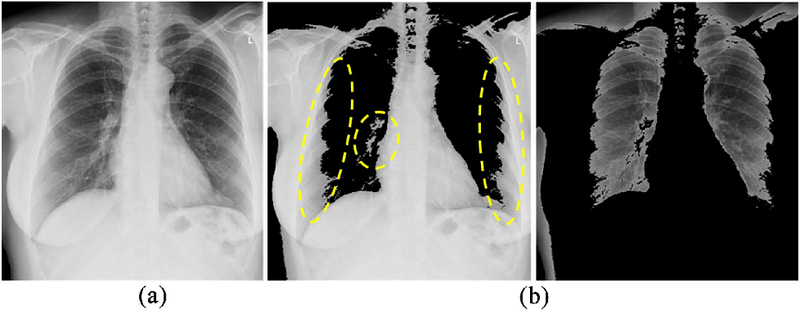
Region-based Segmentation
Region-based segmentation separates images into regions that have similar features, such as color, texture, or intensity, using a method that groups pixels. With this data, regions or clusters are then divided or combined until a desired level of segmentation is reached.
Annotators and AI-based tools can do this using a common split and merge method or graph-based segmentation.
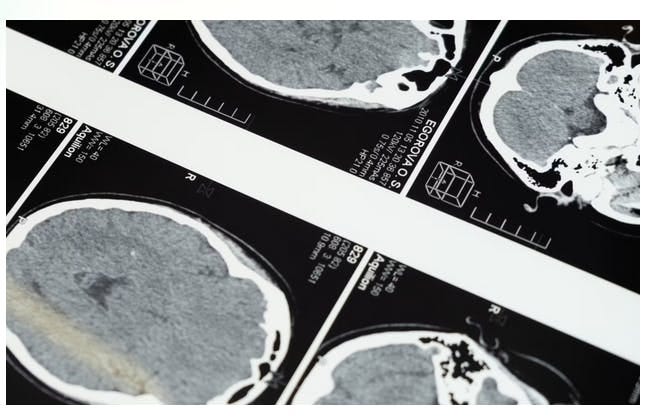
Edge-based Segmentation
Edge-based segmentation is used to detect and isolate the edges of an image from the background. AI tools can be used to find changes in intensity or color values and use this to draw the borders of objects in images.
One method is the Canny edge detection method, whereby a Gaussian filter is used, applying non-maximum suppression to narrow the edges and using hysteresis thresholding to eliminate weak edges.
Another method, called Sobel, involves calculating the gradient magnitude and direction of an image using a Sobel operator, which is a convolution kernel that extracts horizontal and vertical edge information separately.
Summary
We have seen the different types and applications of medical image segmentation in this story. in the up-coming stories, we will try to implement them in Python and show their applications in real medical scenarios.
If you like the article and would like to support me make sure to: 📰 View more content on my medium profile and 👏Clap for this article 📰 View more content on AI-ContentLab Blog 🚀👉 Read more related articles to this one on Medium and AI-ContentLab




