
Mastering the Database Duality: Exploring the Realm of SQL and 8 Different NoSQL Databases with Cheatsheet
In today's digital era, data is the lifeblood of organizations, fueling innovation, driving insights, and empowering decision-making. Choosing a suitable database becomes crucial as businesses strive to manage and harness their data effectively. The database landscape presents us with two prominent paradigms: SQL and NoSQL. These divergent approaches offer distinct strengths and capabilities, providing a rich tapestry of data storage and management options.
In this blog, we embark on a journey through the realm of databases, delving into the contrasting worlds of SQL and NoSQL. We will unravel the intricacies, explore the key characteristics, and examine the unique benefits of each approach. From the structured rigidity of SQL to the flexible agility of NoSQL, we will dissect the fundamental differences and shed light on how these databases cater to diverse data requirements.
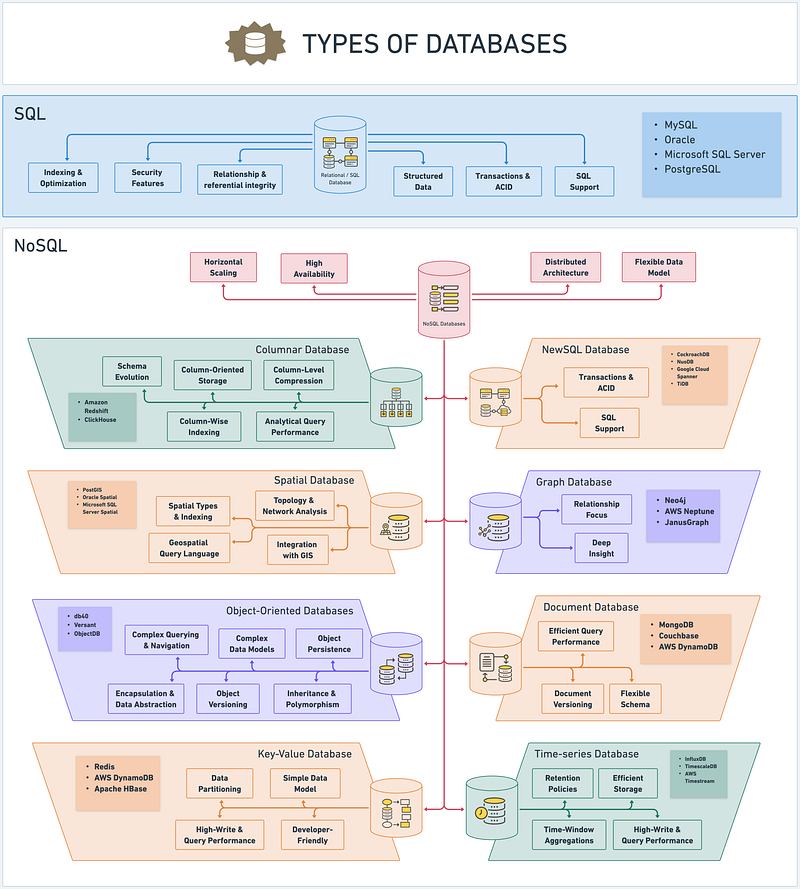
SQL — Structured Query Language
SQL (Structured Query Language) databases have been the data storage and management foundation for decades. They provide a structured and efficient way to store and retrieve data, making them the go-to choice for many businesses. Let's dive into the key features of SQL databases and explore some popular providers such as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL.

- SQL Support: SQL databases excel in their support for the SQL language. SQL provides a standardized and intuitive way to interact with the database, allowing for efficient data querying, manipulation, and retrieval. SQL's declarative nature enables users to express complex operations concisely and readably.
- Indexing & Optimization: SQL databases offer robust indexing mechanisms that improve query performance by creating efficient data access paths. Indexes allow quick data retrieval based on specified columns, enhancing search speed and overall database performance. Additionally, SQL databases provide optimization techniques like query optimization, which analyzes and optimizes query execution plans for improved efficiency.
- Relationship & Referential Integrity: One of the critical strengths of SQL databases is their ability to handle relationships between tables. They support establishing relationships using primary and foreign keys, ensuring data integrity, and enforcing referential integrity constraints. These features enable the creation of complex data models with interconnected tables, facilitating data consistency and accuracy.
- Structured Data: SQL databases excel at managing structured data, which follows a predefined schema. They enforce a fixed schema that defines the data's structure, types, and relationships. This structure ensures data consistency and enables efficient storage and retrieval operations.
- Transactions & ACID: SQL databases provide transactional capabilities, supporting the ACID properties (Atomicity, Consistency, Isolation, Durability). Transactions ensure that a group of database operations is treated as a single unit of work, guaranteeing data integrity and consistency even in the face of failures or concurrent access. ACID compliance ensures that transactions are reliable and adhere to strict data consistency rules.
- Security Features: SQL databases prioritize security and offer robust security features. They provide access controls, allowing administrators to define user privileges and restrict unauthorized access. SQL databases also support data encryption at rest and during transit, protecting sensitive information from unauthorized access or interception.
Providers like MySQL, Oracle, Microsoft SQL Server, and PostgreSQL are widely used and respected in the industry, offering a range of features and scalability options to meet diverse business needs. Each provider has unique strengths, such as performance, scalability, and enterprise-level features, making them suitable for different use cases.
NoSQL
NoSQL databases have emerged as a powerful alternative to traditional SQL databases, offering unique features and capabilities that address specific data management challenges.
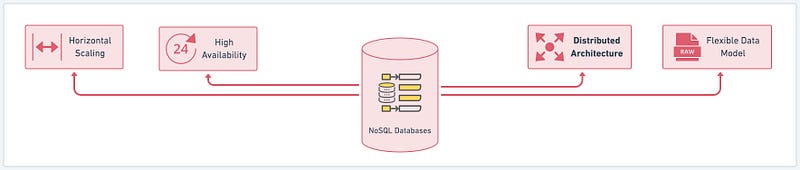
- High Availability: NoSQL databases prioritize high availability, ensuring data remains accessible even during hardware failures or network issues. They employ replication techniques to create multiple copies of data across different nodes or clusters, enabling automatic failover and seamless data accessibility.
- Horizontal Scaling: NoSQL databases are designed to scale horizontally, allowing you to handle increasing data volumes and traffic by adding more nodes to the system. They distribute data across multiple servers, allowing seamless scalability without sacrificing performance or availability.
- Distributed Architecture: NoSQL databases embrace a distributed architecture, where data is distributed across multiple servers or nodes in a cluster. This architecture enables efficient load balancing, fault tolerance, and high-performance data processing. It also allows for seamless expansion as the data volume grows.
- Flexible Data Model: One of the distinguishing features of NoSQL databases is their flexible data model. Unlike the structured schema of SQL databases, NoSQL databases accommodate unstructured and semi-structured data, making them suitable for handling diverse data types such as JSON, XML, key-value pairs, or document structures. This flexibility enables developers to store and manage data without predefined schemas, providing agility and adaptability.
NoSQL databases differ from SQL databases in several aspects. While SQL databases excel in handling structured data with predefined schemas and supporting complex relationships, NoSQL databases are designed for handling unstructured or semi-structured data with flexible schemas. SQL databases emphasize strong data consistency through transactions and ACID properties, while NoSQL databases prioritize scalability, distributed architecture, and eventual consistency.
SQL databases are well-suited for applications that require strict data integrity, complex querying capabilities, and structured data models. They are commonly used for transactional systems, financial applications, and scenarios where data relationships are critical.
On the other hand, NoSQL databases shine in scenarios that demand high availability, horizontal scalability, and the ability to handle massive amounts of unstructured or semi-structured data. They are widely used in modern web applications, big data analytics, content management systems, and real-time data processing.
Choosing between SQL and NoSQL depends on the specific requirements of your application. SQL databases are favored when data consistency and complex querying are paramount, while NoSQL databases excel in scalability, flexibility, and handling of diverse data formats.
In the vast world of NoSQL databases, there are several specialized types, each catering to specific data management needs. Let’s explore the diverse landscape of NoSQL databases, including columnar, NewSQL, spatial, graph, object-oriented, document, key-value, and time-series databases. Each type offers unique features and benefits, empowering organizations to handle different data structures and use cases effectively.
Columnar Database
Columnar databases store and query data in a column-oriented fashion, providing significant advantages for analytics and data warehousing. By storing data column-wise rather than row-wise, they deliver exceptional query performance, high compression rates, and efficient data aggregation. Columnar databases are ideal for scenarios that require complex analytical queries, large-scale data storage, and high-speed data retrieval.
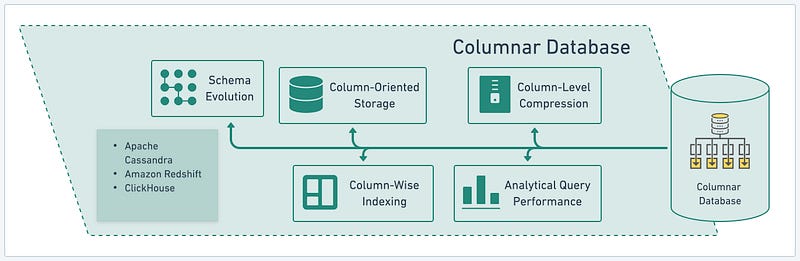
Let’s explore the critical features of columnar databases using Apache Cassandra, Amazon Redshift, and ClickHouse as examples:
- Schema Evolution: It allows for schema evolution, enabling flexibility in adapting to changing data requirements. Unlike traditional SQL databases, where altering the schema can be cumbersome, columnar databases can handle schema modifications more seamlessly, allowing for adding or removing columns without disrupting existing data.
- Column-Level Compression: It excels in compressing data at the column level. Since columns often contain similar or repetitive values, columnar storage allows for efficient compression techniques that reduce storage requirements and improve overall performance. This compression technique is particularly beneficial when dealing with large volumes of data.
- Analytical Query Performance: They are optimized for analytical query performance, especially for complex and ad-hoc queries. The columnar storage layout allows for the efficient processing of questions that involve aggregations, filtering, and data retrieval from specific columns, resulting in faster query execution and improved performance for analytical workloads.
- Column-Oriented Storage: Columnar databases store data in a column-oriented manner, which contrasts with row-oriented storage used in traditional relational databases. This storage approach enhances data retrieval performance for analytical workloads by only accessing the necessary columns rather than retrieving entire rows. It eliminates the need to scan irrelevant columns, improving query performance.
- Column-Wise Indexing: Columnar databases employ column-wise indexing techniques to enhance query performance further. These indexing mechanisms optimize data access by creating indexes tailored to individual columns. As a result, queries that involve filtering or searching specific columns can be executed more efficiently, reducing the need for full table scans.
NewSQL Database
NewSQL databases are a category of databases that combine the scalability and performance of NoSQL databases with the ACID transactions and SQL support of traditional relational databases. They aim to address the limitations of conventional relational databases in handling high scalability and distributed environments. Let’s explore the key benefits of NewSQL databases using CockroachDB, NuoDB, Google Cloud Spanner, and TiDB as examples:
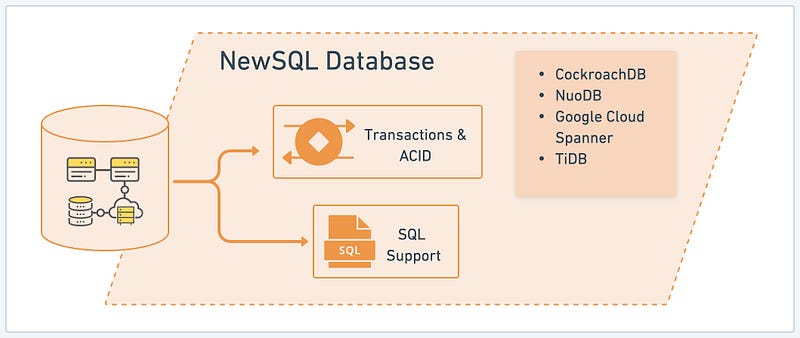
- Transactions & ACID: NewSQL databases strongly support transactions and ACID (Atomicity, Consistency, Isolation, Durability) properties. They ensure data integrity and consistency even in distributed and highly scalable environments. The ability to perform complex and reliable transactions is critical for applications that require consistency across multiple operations or data manipulations.
- SQL Support: NewSQL databases offer SQL support, making them compatible with existing SQL-based applications and allowing developers to leverage their SQL knowledge and skills. SQL provides a familiar and widely adopted language for data querying and manipulation, enabling seamless integration and migration from traditional relational databases to NewSQL solutions.
Spatial Database
Spatial databases are designed to handle geospatial data, which includes information related to geographic locations, maps, and spatial relationships. Several providers offer spatial database solutions, such as PostGIS, Oracle Spatial, and Microsoft SQL Server Spatial. Let’s explore the key benefits of spatial databases:
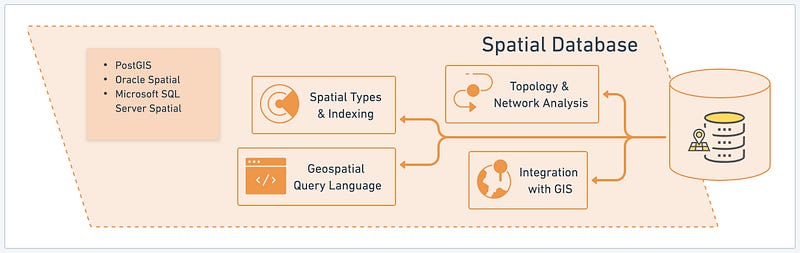
- Topology & Network Analysis: Spatial databases provide advanced topology and network analysis capabilities. They enable the representation and analysis of spatial relationships, such as connectivity, proximity, and containment. This feature is handy for transportation networks, routing, logistics, and urban planning applications.
- Integration with GIS: Spatial databases seamlessly integrate with Geographic Information Systems (GIS). They offer compatibility with GIS tools, allowing storing, managing, and analyzing spatial data within a GIS environment. This integration facilitates data visualization, mapping, and geospatial analysis, enabling geospatially-enabled applications and decision-making processes.
- Spatial Types & Indexing: Spatial databases provide specialized data types and indexing techniques for efficient spatial data storage and retrieval. They support geometric primitives (points, lines, polygons), spatial relationships (intersects, contains, within), and coordinate systems. Spatial indexing structures, such as R-trees, enhance query performance by optimizing spatial data access.
- Geospatial Query Language: Spatial databases typically include a dedicated Geospatial Query Language (GQL) or extensions to SQL for querying and manipulating geospatial data. These languages provide a rich set of functions and operators designed explicitly for spatial operations, enabling developers to express complex spatial queries and perform spatial analysis effectively.
SELECT name
FROM cities
WHERE ST_Within(geometry, ST_Buffer(ST_Point(-122.4194, 37.7749), 1000))Object-Oriented Database
Object-oriented databases (OODBs) are designed to store and manage complex data models that align with object-oriented programming paradigms. Several providers offer OODB solutions, including db4o, Versant, and ObjectDB. Let’s explore the key benefits of object-oriented databases:
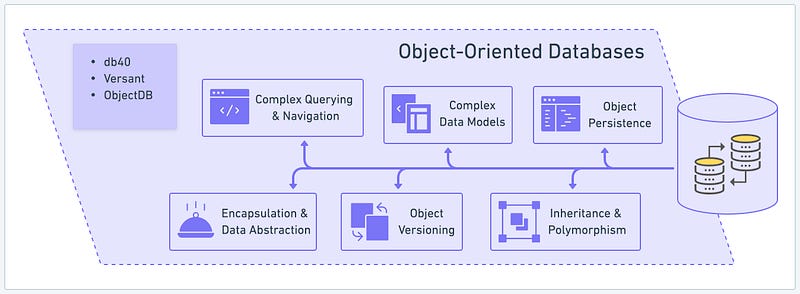
- Encapsulation & Data Abstraction: OODBs enable encapsulation and data abstraction, allowing the group of data and methods into objects. This feature promotes code organization, modular development, and data security by encapsulating data within objects and providing abstraction layers for accessing and manipulating that data.
- Complex Querying & Navigation: OODBs offer advanced capabilities, including support for complex queries involving relationships, inheritance, and nested objects. With OODBs, developers can easily navigate object graphs and retrieve related objects efficiently, simplifying complex data retrieval operations.
- Inheritance & Polymorphism: OODBs support inheritance and polymorphism, critical principles of object-oriented programming. Inheritance allows for creating class hierarchies, enabling code reuse and promoting code organization. Polymorphism allows objects of different types to be treated uniformly, providing flexibility and extensibility in modeling complex data structures.
- Object Versioning: OODBs provide mechanisms for object versioning, allowing developers to track and manage object changes over time. Object versioning enables efficient handling of data evolution and facilitates tasks such as rollback, auditing, and concurrency control.
- Object Persistence: OODBs offer object persistence, meaning that objects can be stored directly in the database without needing object-relational mapping. This native persistence simplifies development, reduces complexity, and enables transparent and direct manipulation of objects within the database.
- Complex Data Models: OODBs excel in handling complex data models, including interconnected, nested, and heterogeneous data structures. They support complex relationships, associations, and aggregates, making them suitable for applications that require rich data modeling capabilities.
Key-Value Database
Key-value databases are NoSQL database that stores data as a collection of key-value pairs. They offer simplicity and high performance for specific use cases. Let’s explore the key benefits of key-value databases using Redis, AWS DynamoDB, and Apache HBase as examples:
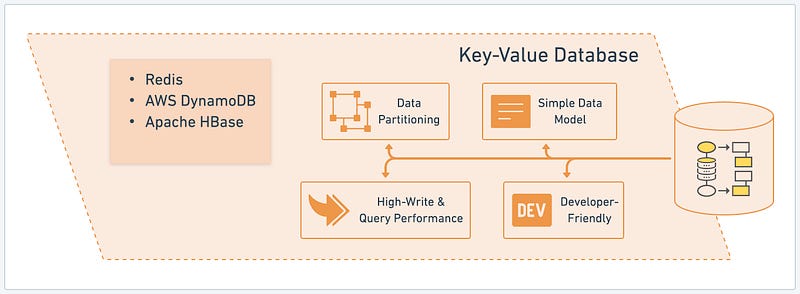
- Simple Data Model: Key-value databases have a straightforward data model, storing and retrieving data using a unique key associated with each value. This simplicity allows for fast and efficient data access, making key-value databases ideal for scenarios that require quick and direct key-based lookups.
- Data Partitioning: Key-value databases offer built-in support for data partitioning and distribution across multiple servers or nodes. This feature enables horizontal scaling and helps to manage large volumes of data by distributing it across a cluster. By dividing the data into partitions, key-value databases achieve high scalability and improved performance.
- Developer-Friendly: Key-value databases are known for their developer-friendly nature. They provide simple and intuitive APIs that allow developers to interact with the database using basic operations like set, get, delete, and update. This ease of use and minimalistic approach make key-value databases suitable for rapid application development and prototyping.
- High-Write & Query Performance: Key-value databases are designed to deliver high performance, particularly in write-heavy and query-intensive scenarios. They handle massive write loads by providing fast and efficient write operations. Additionally, key-value databases offer low-latency access to data, making them well-suited for applications that require real-time data processing and high-speed data retrieval.
Time-series Database
Time-series databases are explicitly designed to handle data ordered and indexed by time. They excel at efficiently storing, managing, and analyzing time-stamped data, such as IoT sensor data, log files, financial market data, and more. Let’s explore the key benefits of time-series databases using InfluxDB, TimescaleDB, and AWS Timestream as examples:
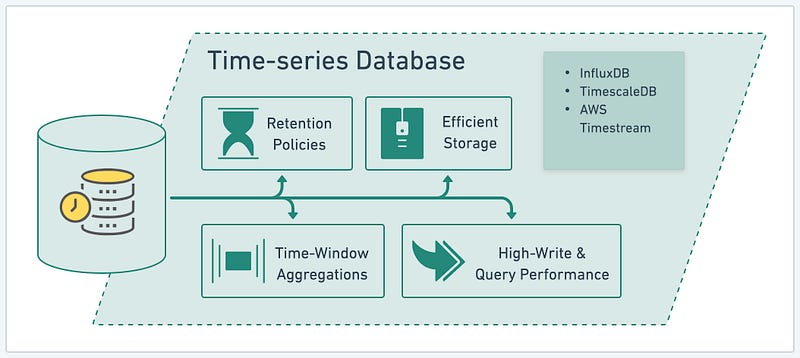
- High-Write & Query Performance: They are optimized for handling high volumes of write operations and fast query performance. They are designed to efficiently ingest and store time-stamped data, providing high-speed data ingestion and retrieval. This feature is crucial for applications that require real-time or near-real-time data processing and analysis.
- Efficient Storage: It employs techniques optimized for efficient data storage. They typically utilize columnar or compressed storage formats, enabling efficient storage and reducing disk space requirements. By efficiently storing data, time-series databases can handle large data volumes without compromising performance or scalability.
- Time-Window Aggregations: It offers built-in support for time-window aggregations, allowing easy and efficient calculation of data aggregates over specific time intervals. These aggregations, such as sum, average, min, max, and count, provide valuable insights and enable quick analysis of time-series data at different granularity levels.
- Retention Policies: It allows the definition of retention policies to manage data lifecycle and storage requirements. Retention policies specify how long data should be retained in the database and what level of granularity is necessary. This flexibility enables efficient data storage management, automatic data purging, and the ability to handle long-term data retention needs.
Document Database
Document or document-oriented databases are designed to store, retrieve, and manage semi-structured and unstructured data in documents. They offer flexibility and scalability for handling diverse data structures. Let’s explore the key benefits of document databases using MongoDB, Couchbase, and AWS DynamoDB as examples:
- Flexible Schema: Document databases provide a flexible schema, allowing for dynamic and schema-less data structures. Unlike traditional relational databases that enforce a fixed schema, document databases allow for variations in the structure and content of documents within the same collection. This flexibility enables easy adaptation to evolving data requirements and simplifies development.
- Document Versioning: Document databases support document versioning, which enables the storage and management of different versions of documents over time. This feature is valuable for scenarios where data evolves or requires auditing and historical tracking. Document versioning allows for efficient retrieval and monitoring of changes, enabling developers to analyze and manage document revisions.
- Efficient Query Performance: Document databases offer efficient query performance by leveraging indexing and optimized query execution plans. They provide various querying capabilities, including querying by document fields, nested structures, and even full-text search. Additionally, document databases often utilize document-level caching and optimized storage structures to deliver fast and responsive query performance.
Graph Database
Graph databases are designed to store and process data in the form of interconnected nodes (vertices) and relationships (edges). They excel at representing and querying complex relationships and dependencies between entities. Let’s explore the key benefits of graph databases using Neo4j, AWS Neptune, and JanusGraph as examples:
- Deep Insight: Graph databases provide deep insights into complex relationships and connections within the data. They represent rich and intricate node relationships, enabling a holistic understanding of data patterns, dependencies, and associations. This capability is precious for applications that involve social networks, recommendation systems, fraud detection, knowledge graphs, and network analysis.
- Relationship Focus: Graph databases prioritize relationships as first-class citizens. They offer efficient and performant traversals of relationships, allowing for quick and precise navigation across nodes based on their connections. This relationship-centric approach enables powerful query capabilities to explore patterns, identify connections, and analyze dependencies, delivering insights that are difficult to achieve with traditional databases.
Conclusion
Selecting a suitable database requires a deep understanding of your project’s requirements. SQL databases are ideal for structured data and complex relationships, while NoSQL databases offer scalability and flexibility for diverse data types. Specialized databases cater to specific needs such as analytics, spatial data, graph relationships, etc. You can make an informed decision that aligns with your project’s unique requirements by evaluating key features, benefits, and providers.
Remember, this guide provides a starting point; further research and evaluation are essential to choosing the best database for your use case. With a suitable database, you can unlock the power of efficient data storage, retrieval, and analysis, setting the foundation for a successful project.
— —
Thanks to Alex Xu for his invaluable partnership in developing this content and diagrams.
— —
I conclude this learning; I hope you have learned something new today. Please do share with more colleagues or friends. Finally, consider becoming a Medium member. Thank you!
— —




